Splunk大数据分析经验分享
转自:http://www.freebuf.com/articles/database/123006.html
Splunk大数据分析经验分享:从入门到夺门而逃
* 作者:Porsche(U神),本文属FreeBuf原创奖励计划文章,未经许可禁止转载
大家好,我是U神,关于Splunk的文章网上非常少,中文的官方文档也很少。这篇文章的都是我观看某Splunk视频(那视频好贵,我是通过某XX看到的)后写下的学习笔记,我用自己通俗易懂的语言非常详细地写了splunk的安装、CLI命令、SPL语言、数据分析等。记录这些笔记花了较长时间,一方面是让学习更加深刻,一方面防止忘记了后可以找找笔记再看看,另一方面发出来也想分享给每一个想学习Splunk的朋友,相信这篇文章会是你入门的最佳选择。
目录
0×01 初识splunk0x02 Linux上安装Splunk0x03 Windows上安装Splunk
0×04 Splunk安装后配置
0×05 Splunk的目录结构
0×06 Splunk常用的CLI命令
0×07 实战-导入数据前的准备
0×08 实战-导入并分析本地数据-1
0×09 实战-导入并分析本地数据-2
0×10 使用转发器转发数据
0×11 实战-数据分析和可视化-1
0×12 实战-数据分析和可视化-2
0×13 邮箱服务器配置
0×14 创建APP 0X15 Splunk技巧
0×15 splunk技巧
0×01 初识splunk
一、公司:
美国Splunk公司,成立于2004年,2012年纳斯达克上市,第一家大数据上市公司,荣获众多奖项和殊荣。 总部位于美国旧金山,伦敦为国际总部,香港设有亚太支持中心,上海设有海外第一个研发中心。 目前国内最大的客户许可是800GB/天。 产品:Splunk Enterprise【企业版】、Splunk Free【免费版】、Splunk Cloud、Splunk Hunk【大数据分析平台】、Splunk Apps【基于企业版的插件】等。
二、产品:
Splunk Enterprise,企业版,B/S架构,按许可收费,即每天索引的数据量。
(购买20GB的许可,则默认每天可索引20G数据量;一次购买永久使用;如果使用试用版,试用期结束之后会切换到免费版)
Splunk Free,免费版,每天最大数据索引量500MB,可使用绝大多数企业版功能。
(免费版没有例如:身份验证、分布式搜索、集群等功能)
Splunk Universal Forwarder,通用转发器,是Splunk提供的数据采集组件,免费,部署在数据源端,无UI界面,非常轻量,占用资源小。
(转发器无许可证,是免费的;企业版专用的;所以部署在数据源,例如:部署在你的WEB服务器上,监控你的WEB日志,实时监控,产生一条日志则转发一条,进行增量转发;一般配置修改配置文件或者使用CLI命令。占用资源小)
三、Splunk是什么
面向机器数据的全文搜索引擎;
(使用搜索引擎的方式处理数据;支持海量级数据处理)
准实时的日志处理平台;
基于时间序列的索引器;
大数据分析平台;
一体化的平台:数据采集->存储->分析->可视化;
通用的搜索引擎,不限数据源,不限数据格式;
提供荣获专利的专用搜索语言SPL(Search Processing Language),语法上类似SQL语言
Splunk Apps 提供更多功能
(针对操作系统、思科网络设备,splunk都提供了专用的APP,接入数据源都可以看到直观的仪盘表。)
四、机器数据是什么
机器数据是指:设备和软件产生的日志数据、性能数据、网络数据包。这些数据都是一些非结构化的数据,我们可以统一将这些数据统一采集到splunk之后,splunk可以对这些数据进行索引、调查、监控、可视化等。
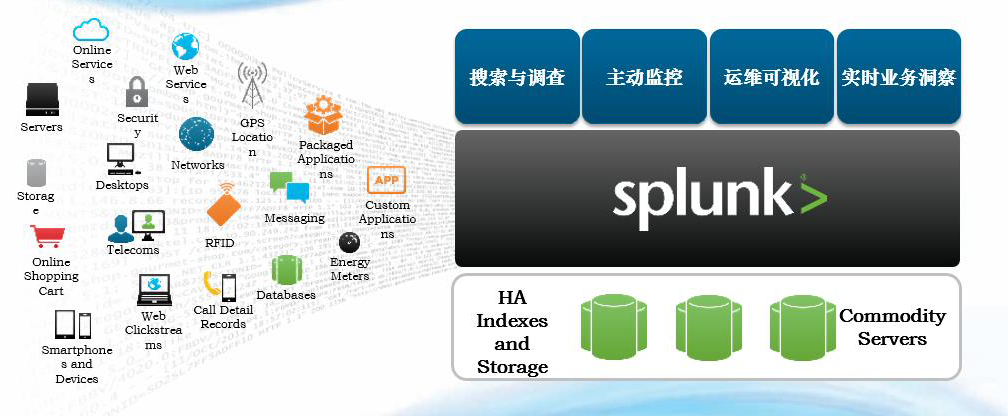
五、Splunk组件
索引器:索引器是用于为数据创建索引的Splunk Enterprise 实例。索引器将原始数据转换为事件并将事件存储至索引(Index)中。索引器还搜索索引数据,以响应搜索请求。
搜索头:在分布式搜索环境中,搜索头是处理搜索管理功能、指引搜索请求至一组搜索节点,然后将结果合并返回至用户的Splunk Enterprise 实例。如果该实例仅搜索不索引,通常被称为专用搜索头。
搜索节点:在分布式搜索环境中,搜索节点是建立索引并完成源自搜索头搜索请求的Splunk Enterprise实例。
转发器:转发器是将数据转发至另一个Splunk Enterprise 实例(索引器或另一个转发器)或至第三方系统的Splunk Enterprise 实例。
接收器:接收器是经配置从转发器接收数据的Splunk Enterprise 实例。接收器为索引器或另一个转发器。
应用:应用是配置、知识对象和客户设计的视图和仪表板的集合,扩展Splunk Enterprise 环境以适应Unix 或Windows 系统管理员、网络安全专家、网站经理、业务分析师等组织团队的特定需求。单个Splunk Enterprise 安装可以同时运行多个应用。
六、Splunk分布式架构
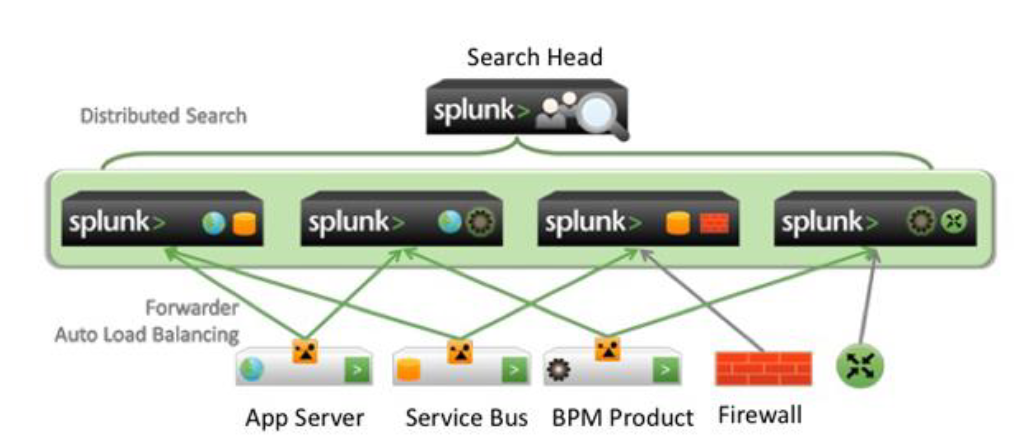
如上图所示:
1、可分为三层:第一层为数据源端:如应用服务器、服务总线、网络设备、防火墙等。
2、如果要采集这些数据例如:应用服务器可安装splunk的转发器,防火墙的数据可以通过TCP\UPD端口将数据发送到Splunk的中间层,Splunk的中间层称为splunk的索引器(接收器),数据将存储在这一层。
3、用户使用search head检索实例,search head将检索请求发送到各个索引器中。再把结果汇集到search head中,最后呈现给用户观看。
4、 数据源的转发器会将数据转发到多个splunk的实例中,转发器将进行自动负载均衡。
七、通用转发器
转发器分为重量(Heavy)、轻量(Light)和通用转发器(Universal)三种类型。
最常用的是通用转发器,其他两类很少使用。
与完整Splunk Enterprise实例相比,通用转发器的唯一目的是转发数据。与完整Splunk Enterprise 实例不同的是,您无法使用通用转发器索引或搜索数据。
为实现更高性能和更低的内存占用,它具有几个限制:
通用转发器没有搜索、索引或告警功能。
通用转发器不解析数据。
通用转发器不通过syslog 输出数据。
与完整Splunk Enterprise 不同的是,通用转发器不包含捆绑的Python 版本。
八、多种应用场景

0×02 Linux上安装Splunk
一、配置时间:
配置一致的时间
建议搭建企业内NTP服务器,将所有相关设备指向该服务器
(如果各个机器的时间不一致,就会因此产生问题。所以建议搭建一台NTP服务器,让所有设备的时间指向NTP服务器,让所有设备统一时间)
二、安装准备
本次安装基于CentOS 6.7, 64位
建议部署在64位环境下
Splunk Enterprise:
splunk-6.4.2-00f5bb3fa822-Linux-x86_64.tgz
Splunk 通用转发器:
splunkforwarder-6.4.2-00f5bb3fa822-Linux-x86_64.tgz
本次以root用户安装(可以使用非root)
三、 安装步骤
1)、wget下载tgz的压缩包。
2)、解压缩:#tar -zxvf splunk-6.5.1-f74036626f0c-Linux-x86_64.tgz -C /opt (默认我们解压到/opt目录下)
3)、splunk的可执行程序都放在/opt/splunk/bin/下,启动该程序应执行splunk,splunk命令参数如下:
#注意:以下命令我们称之为CLI命令,如下:通用转发器和splunk命令都可以如下执行
./splunk
start //启动splunk
--accept-license //自动接收许可
restart //重启splunk
status //查看splunk状态
version //查看splunk版
开始启动的时候记得记住加上–accept-license,这样更便于我们安装。
4)、splunk安装之后开启Splunk Web端口8000。Splunkd端口8089端为管理端口。 安装之后我们可以在浏览器中访问splunk 8000端口的WEB界面。
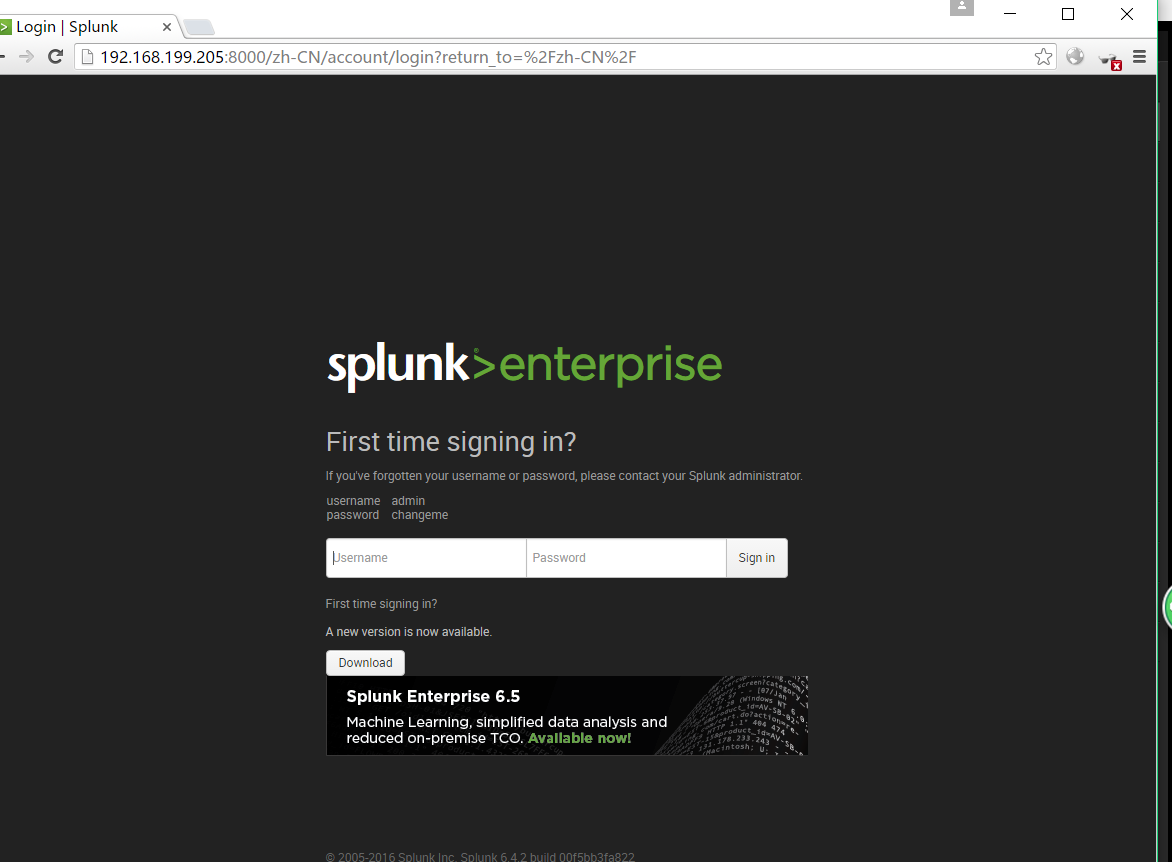
注意:如果外部计算机无法访问它。需要关闭iptables服务或将该端口加入策略中
#services iptables stop [其它类unix系统关闭防火墙]
systemctl stop firewalld.service [CentOS 7下停止防火墙]
Splunk地址如:http://192.168.199.205:8000,进入splunk默认的管理员为:admin 、密码为changeme。第一登录便会强制要求修改密码
配置splunk开机启动 ./splunk enable boot-start //这样每次开机,splunk服务都会开机启动

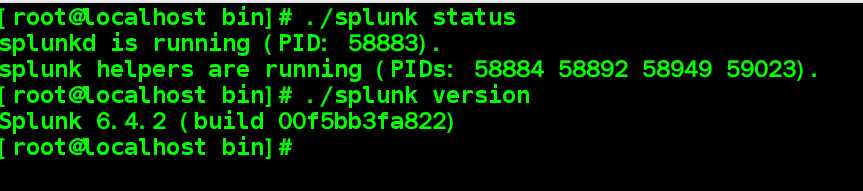
#通过上述命令查看splunk状态和版本信息 ./splunk status
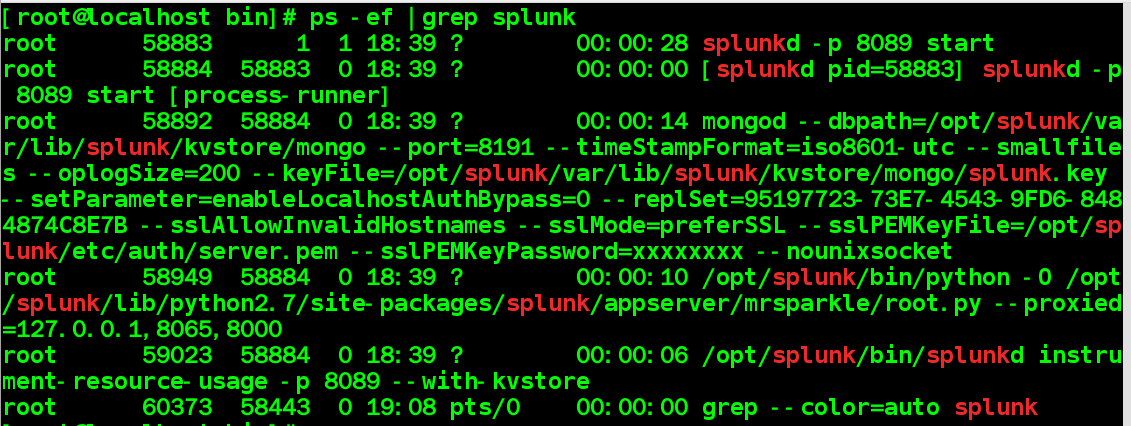
#查看进程相关信息 : ps -f | grep splunk
四、 Splunk的卸载
./splunk disable boot-start //关闭自启动
./splunk stop //停止splunk
./rm–rf/opt/splunk //移除splunk安装目录
卸载要慎重,注意数据备份
五、安装Splunk 通用转发器
1)、将通用转发器解压到opt目录下,Splunk转发器的安装方法和splunk一致,但它无UI界面。
tar zxvf splunkforwarder-6.4.2-00f5bb3fa822-Linux-x86_64.tgz -C /opt
2)、切换到Splunkforwarder的bin目录下去启动通用转发器
cd /opt/splunkforwarder/bin/ //切换到通用转发器的可执行程序目录
./splunk start –accept-license //启动通用转发器
注意:如果splunk web和通用转发器安装在同一 服务器,通用转发器的管理端口也是8090,则会提示被splunk占用,选择yes修改转发器管理端口,如下:

我们可通过CLI命令查看splunkd的端口
./splunk show splunkd-port //不过这里得输入splunk登录的账号密码

./splunk set splunkd-port 8091 //修改splund的端口为8091,提示:重启生效

3)、修改通用转发器密码
默认密码:admin/changeme
修改密码如下:其中role是角色,auth是验证原密码
./splunk edit user admin -password ‘admin’ -role admin -auth admin:changeme

0×03 Windows上安装Splunk
一、安装准备:
#搭建NPT服务器
配置一致的时间
建议搭建企业内NTP服务器,将所有相关设备指向该服务器
#安装用户的选择
本地系统用户,本次采用此方式
域用户,较复杂,请参考文档
#安装环境
本次安装基于Windows 7, 64位
建议部署在64位环境下
Splunk Enterprise:
splunk-6.4.2-00f5bb3fa822-x64-release.msi
Splunk 通用转发器:
splunkforwarder-6.4.2-00f5bb3fa822-x64-release.msi
二、 安装步骤
GUI安装,比较简单, 此处不演示。
Splunk默认安装在 “C:\Program Files\Splunk”
安装之后会注册两个服务,它的显示名称为:Splunkd Service、splunkweb (legacy purposes only)

启动:splunk start
关闭:splunk stop
重启:splunk restart
查看状态:splunk status
查看版本:splunk version
通过Windows DOS命令:
net start splunkd
net stop splunkd
通过服务面板 (services.msc)

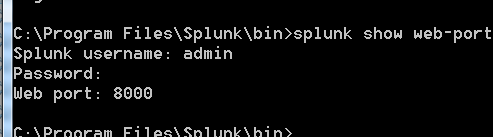
#查看splunk web的端口命令为:
splunk show web-port
三、卸载splunk
依照上方的讲解的停止splunkd。
通过Windows控制面板的卸载程序卸载。

四、 安装Splunk 通用转发器
GUI安装,比较简单,选择:自定义(Customize Options),如下可选择SSL证书。
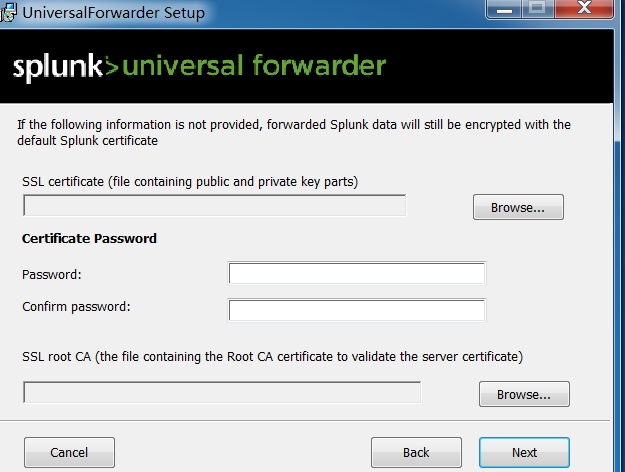
#其次安装的用户如下:
local system :本地系统用户
domain account :域账号
#选择是否收集的日志选项(Windows Event logs)。如:应用日志、安全日志、系统日志、转发事件日志、安装日志。
#选择是否收集Windows 的性能数据(Performance Monitor)。如:CPU、内存、磁盘、网络状态等
#注:收集这些日志都是Splunk的 Splunk Add-on for Microsoft Windows插件,你在NEXT下一步则可安装它。
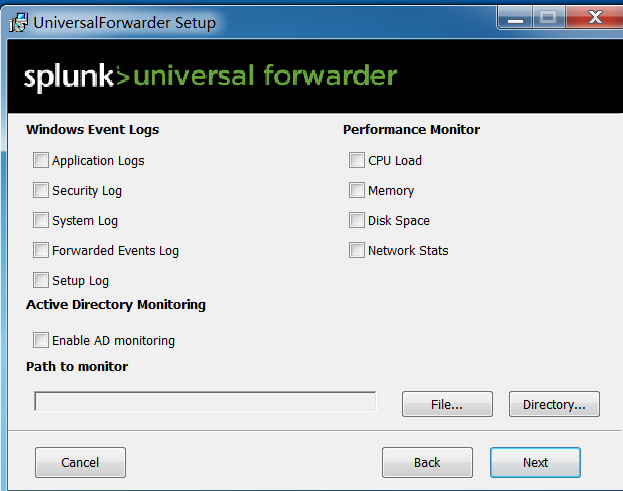
由于收集的这些日志会转发到splunk企业版中winEventlog的索引中,但是由于splunk 企业版没有创建该索引,如果需要创建要么手动创建,要么安装一个Splunk APP.创建索引可在:
进入Splunk Web→设置→索引→新建索引
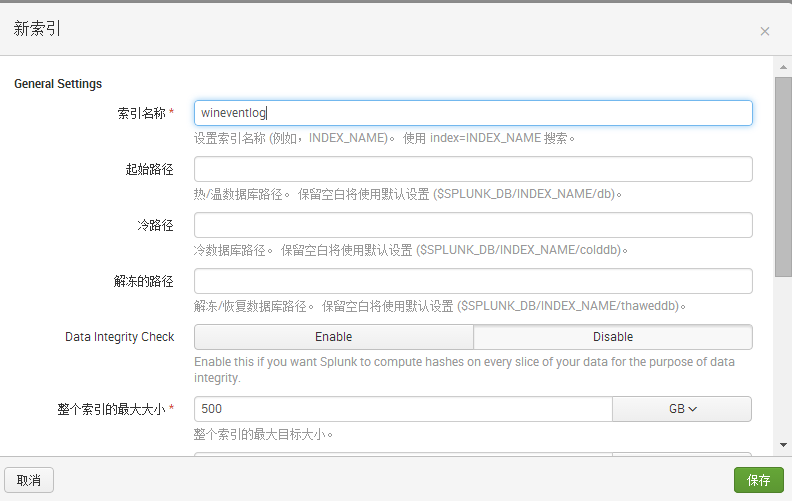
下一步(Receiving Indexer),这里是设置接收器,即上述勾选的系统日志将转发到哪个IP和端口上。由于我们的splunk企业版在本地,所以这里写localhost,开启一个10001端口让这些日志转发到Splunk entiprise上。

#接着在splunk enterprise上配置接收。
进入Splunk Web→设置→转发和接收→接收数据→新增→侦听此端口为:10001(刚才设置的接收端口)
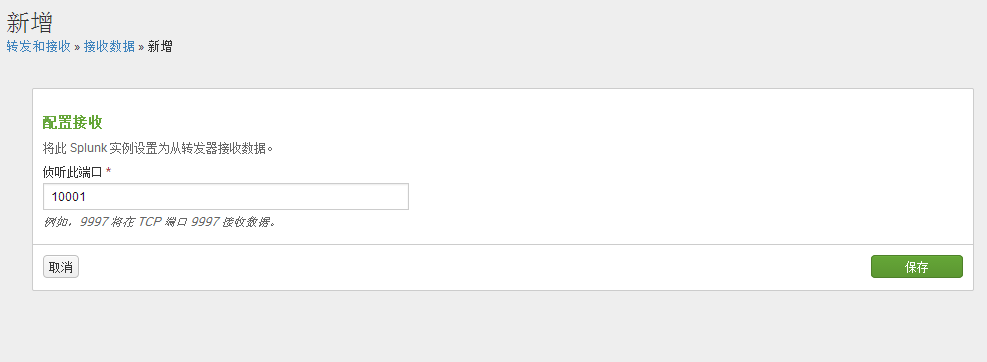
#使用splunk的CLI命令可以查看监听的端口
splunk display listen

当然你也可以通过splunk CLI命令来增加监听端口。
splunk enable listen 10002
此时你便可以查看wineventlog索引接收的数据了
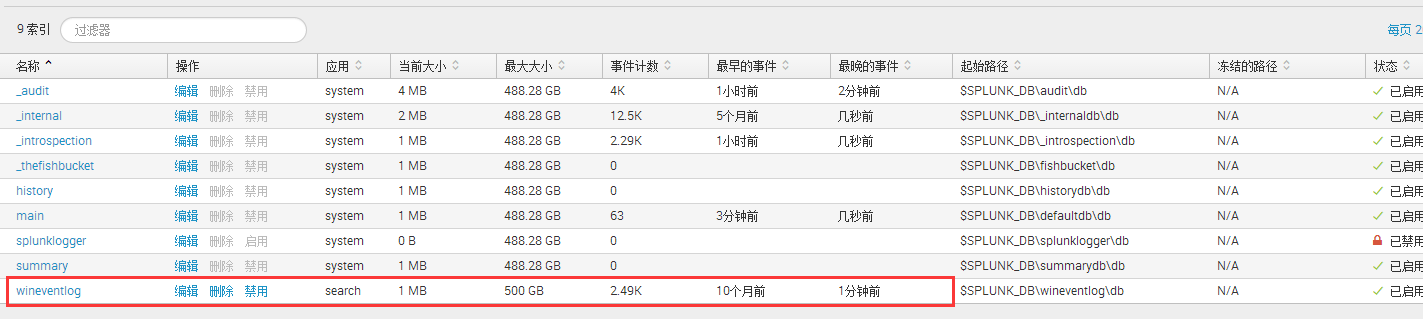
此时可以系统自带的APP (Search &Reporting)使用SPL语言来搜索索引事件。
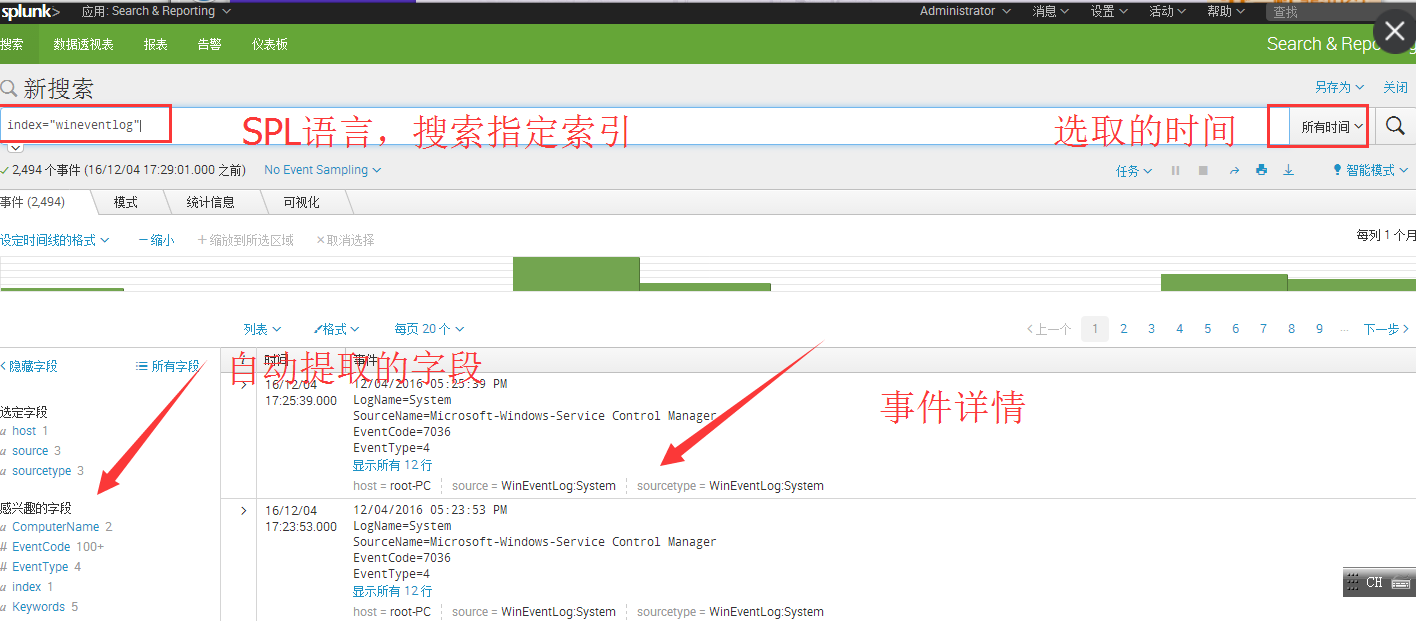
#注:Windows 下会自动解决Splunk Enterprise和通用转发器的管理端口8090的端口冲突。
0×04 splunk安装后的配置
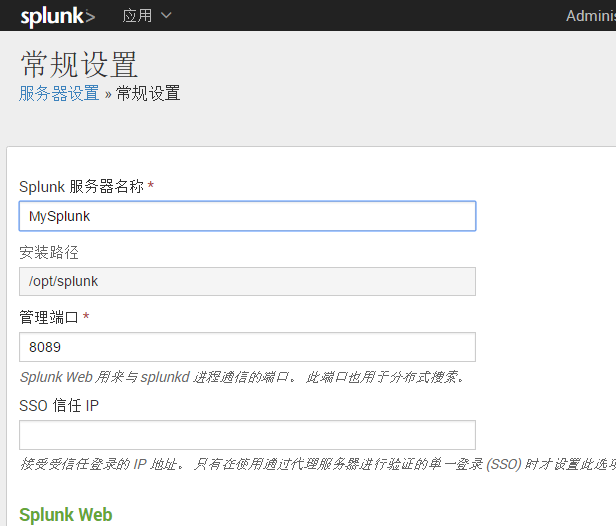
一、配置Splunk的服务器名称
设置->服务器设置->常规设置
默认是服务器主机名
也可通过命令行修改
./splunk set servername 服务器名称 //修改Splunk服务器名称
修改需要重启Splunk
二、配置Splunk的端口号
Splunkd端口号:8089
Splunk Web端口号:8000
可在Splunk Web 中修改,也可通过CLI命令修改
./splunk set splunkd-port 8090 //设置管理端口
./splunk set web-port 8001 //设置WEB端口
配置后需要重启Splunk
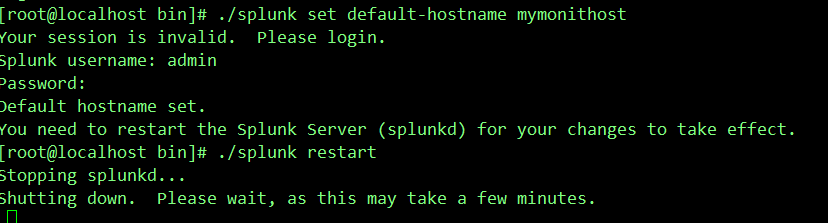
三、设置默认HOST名称
设置源自该服务器的事件的默认host值 #即设置日志所来自的源主机的名称进行标记。
可在Web界面修改
进入Splunk WEB页面→设置→服务器设置→常规设置→索引设置→默认主机名:
或者通过Splunk CLI修改:
#./splunk set default-hostname 新的host名称
配置后需要重启服务器
四、Splunk Web 启用SSL (HTTPS)
在Splunk Web 中启用:设置->服务器设置->常规设置
通过Splunk CLI 命令:
./splunk enable web-ssl //启用SSL
./splunk disable web-ssl //禁用SSL
需要重启
重启后Splunk Web 地址变为:

五、修改默认索引位置
默认索引目录为:/opt/splunk/var/lib/splunk/
可以通过配置文件进行修改位置:(例如,修改为:/foo/splunk):
mkdir /foo/splunk/ //创建新的索引目录, 非root用户请更改目录所有者(chown)
./splunk stop //停止Splunk
cp rp /opt/splunk/var/lib/splunk/* /foo/splunk/ //复制原索引目录下的所有文件到新的索引目录
vi /opt/splunk/etc/splunk-launch.conf //编辑splunk的配置文件
SPLUNK_DB=/foo/splunk //在该配置文件中设置splunk_db为新的索引路径(将原来注释去掉,然后再修改)
./splunk start //重新启动splunk
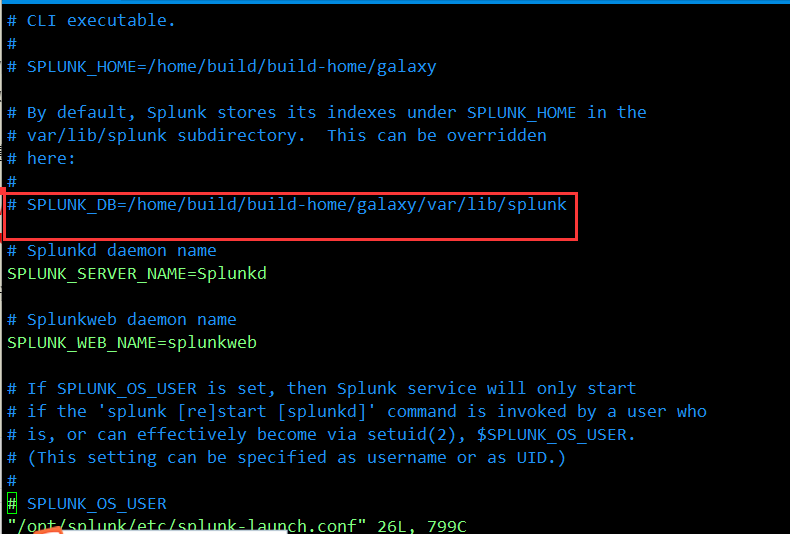
通过CLI命令:
./splunk list index //可查看所有索引以及索引的目录
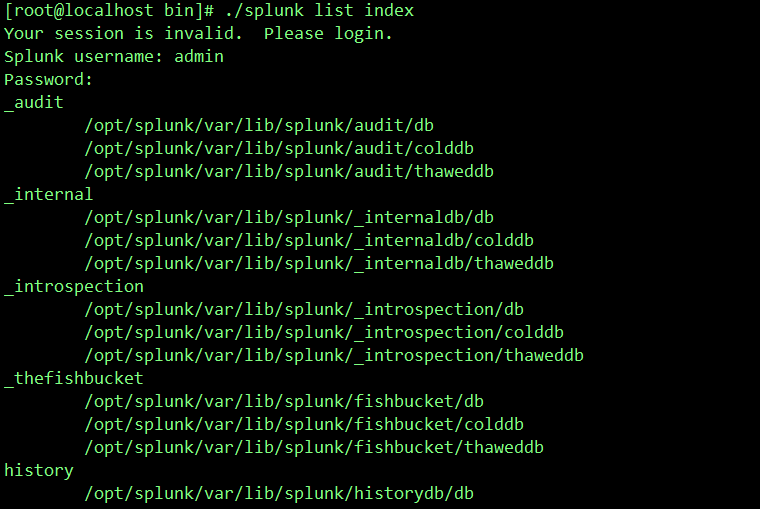
六、创建索引
索引:被检索的数据存储在索引(index)中,类似于database。(就是说转发过来的事件格式化后存储在索引中)
设置->索引->新建索引 (WEB页面中创建索引)
带有_的索引都是splunk的内部索引,这些索引不记录在许可证中
默认索引:main (如果转发过来的数据不指定索引,则会保存在默认的main索引中)
在Splunk Web 中创建/删除索引
通过Splunk CLI 创建/删除索引:
./splunk add index 新的索引名称 //创建新的索引
./splunk remove index 被删除的索引名称 //删除索引
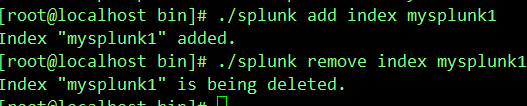
七、配置接收端口
Universal Forwarder 转发给Splunk Enterprise 时,Splunk Enterprise所使用的接收端口默认为TCP 9997。
设置->转发和接收->配置接收,新增9997 (Web界面设置)
通过Splunk CLI 命令:
./splunk enable listen 9997 //启用splunk的接收端口
无需重启Splunk
八、许可类型
设置->授权
安装后是“Enterprise Trial”试用版许可证,500MB/天,试用60天
试用到期后转为“Splunk Free”免费版许可证,500MB/天,部分功能无法使用。
企业版许可证,请联系Splunk销售。
转发器许可证,针对重量和轻量级许可证,通用转发器不需要。
使用情况报表,可以查看当前许可证使用的情况报表
0×05 Splunk的目录结构
一、Splunk的目录结构
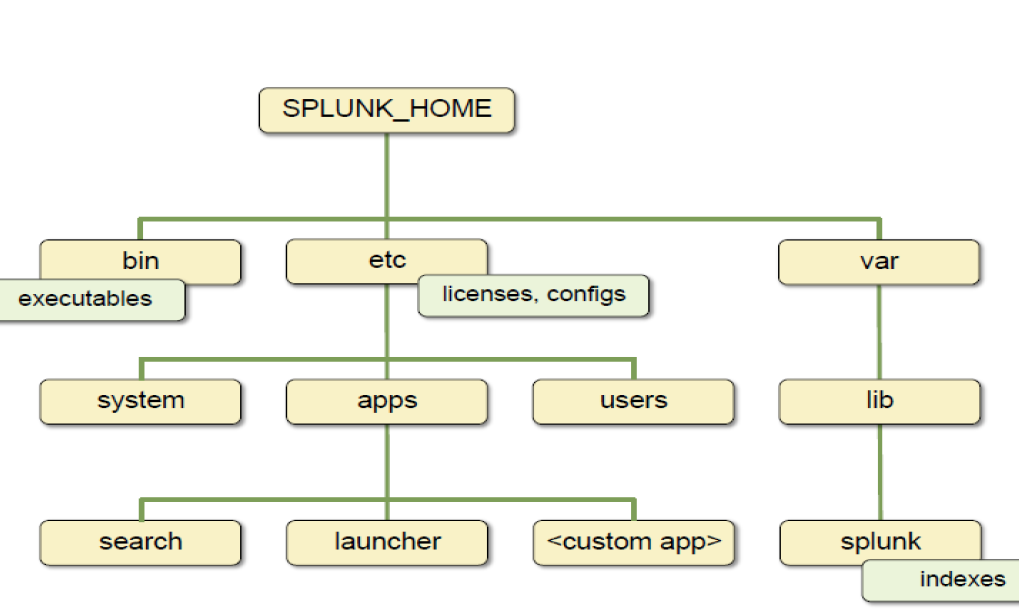
bin目录下:常用的Splunk命令将存储在该文件夹。
etc目录下:许可、配置文件 ,以及splunk创建的app、下载的app都将存在etc/apps;
etc/system目录,存放系统配置文件;
etc/system/local目录,用户对splunk进行的系统配置
etc/users目录,用户的配置文件,每个用户都拥有一个文件夹;
etc/licenses/ 目录,splunk的许可证目录。
etc/apps/目录,本身存在很多自带的APP,如:默认的search & reporting 的APP就是存在etc/apps/search。
etc/apps/SplunkForwarder 目录,是Splunk的重量级转发器。
etc/apps/SplunkLightForwarder 目录,是Splunk的轻量级转发器;
etc/apps/splunk_management_console 目录,是splunk的分布式管理控制台的APP;
以Search&Repoeting APP具体说明:
etc/apps/search/bin 目录,一些APP的脚本放在该目录;
etc/apps/search/local 目录,用户配置APP的文件存在在这里。Splunk升级不会覆盖该该文件夹下的配置文件
etc/apps/search/default 目录,Splunk APP自带的配置文件。
etc/apps/search/static 目录,APP的图标存放文件
#var目录:
var/lib/ 目录下基本是放索引。
var/log Splunk自身日志目录。
#include目录:
include/目录,Splunk自带的Python目录
#share
share/GeoLite2-City.mmdb 文件,Splunk自带的免费IP地址库。
share/splunk/目录,引用的第三方的库文件存储位置。
二、Splunk的配置文件

三、default 和 local区别
Default 目录是Splunk自带的目录
系统优先读取用户自定义local目录下的配置文件, 然后才会读取default目录下的
自定义的配置都要放在local 目录下
千万不要直接修改default目录下的文件
升级时default目录会被覆盖,local目录则不会
0×06 Splunk常用的CLI命令
一、Splunk启动/停止/重启
启动:splunk start
关闭:splunk stop
重启:splunk restart
查看状态:splunk status
查看版本:splunk version
二、配置端口号(splunkd 管理端口和Web端口)
查看端口:
splunk show splunkd-port
splunk show web-port
修改端口:
splunk set splunkd-port
splunk set web-port
三、服务器配置命令
splunk set servername 新的服务器名称 //设置服务器名称
splunk set default-hostname 新的主机名称 //设置默认主机名称
splunk enable web-ssl //启用SSL
splunk disable web-ssl //关闭SSL
四、修改用户密码
splunk edit user admin –password ‘newpassword’ –authadmin:oldpassword //修改用户密码
splunk add user //新增用户
./splunk add user 新的用户名 -password ‘新用户密码’ -full-name ‘设置它的全名’ –role User(这个是角色)

./splunk list user //列出用户
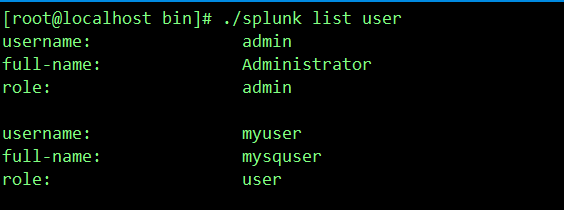
username: 用户名称
full-name :全名
role : 角色
./splunk remove user 被移除的用户名 //删除用户

五、索引操作
./splunk list index //列出所有索引
./splunk add index 新的索引名称 //添加索引

./splunk remove index 要删除索引的名称 //删除索引 #注意:处于已禁用状态无法删除

./splunk enable index 要启用的索引名称 //启用索引

./splunk disable index 被禁用的索引名称 //禁用索引

./splunk reload index //重新加载索引配置

六、启用监听端口
./splunk enable listen 要启用的端口号 // 开启splunk接收的指定端口
./splunk disable listen 要禁用的端口号 // 关闭splunk接收的指定端口
./splunk display listen // 显示已启用的splunk接收的端口

七、splunk show 命令
./splunk show web-port // 查看splunk web的端口
./splunk show splunkd-port // 查看splunkd的端口
./splunk show default-hostname // 查看默认的主机名称
./splunk show servername // 查看显示splunk服务器名称
./splunk show datastore-dir // 查看索引存储的目录

八、splunk search 命令
在命令行执行搜索命令:
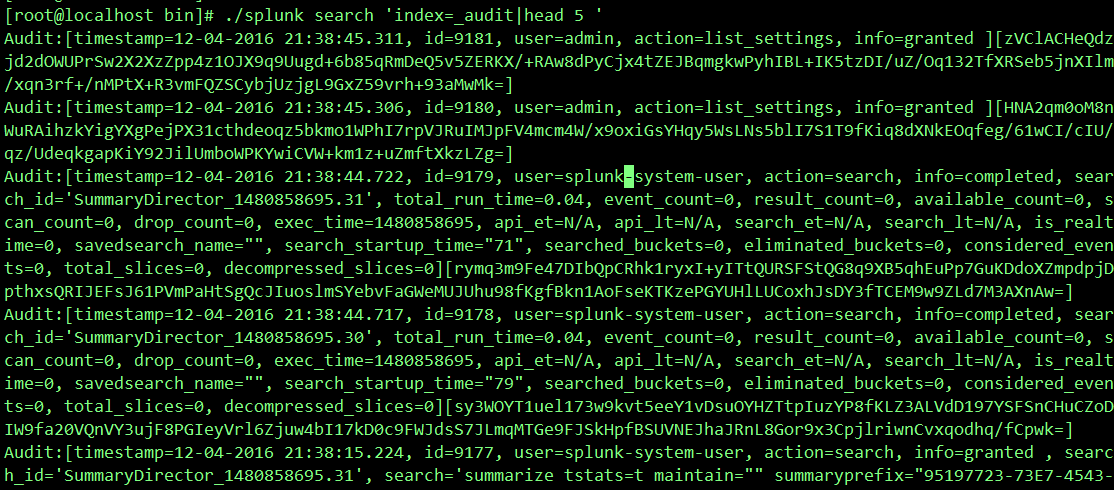
./splunk search ‘index=_audit| head 5′ //查看_audit索引前5条数据
九、转发器常用命令(切换到转发器的bin目录下)
#案例:(通过案例学习命令)
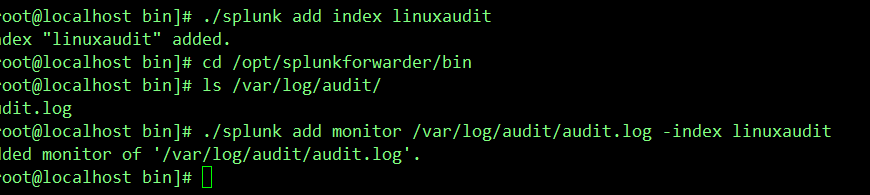
我们这里将Linux的审计日志 /var/log/audit/audit.log 作为监控目标,通过通用转发器,将其转发给Splunk enterprise,我们这里 通用转发器和Splunk Enterprise都是同一台服务器。
1)./splunk add monitor 监控日志的物理地址 -index 所转发到的索引 //添加一个监控项
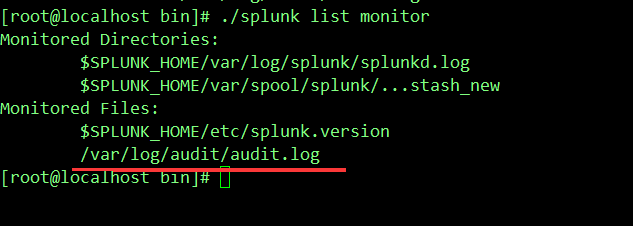
2)./splunk list monitor //列出当前的所有监控项
3)./splunk add forward-server 192.168.199.205:9997 【Splunk Enterprise的IP:接收的端口号】//添加转发服务器

4)./splunk list forward-server //列出转发服务器
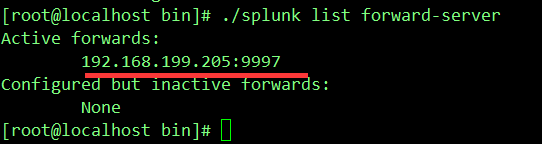
5)./splunk remove monitor ‘移除的监控文件路径’ //删除监控项

6)./splunk remove forward-server 192.168.199.205:9997 //删除

Web中查看linuxaudit索引:

十、splunk help 命令
splunk help //列出splunk常用命令列表
splunk help commands //列出更多的常用命令
splunk help index //列出索引的相关命令
splunk help monitor //列出监控相关的命令
splunk help show //列出信息显示的命令
splunk help forward-server //列出转发服务器的命令
splunk help set //列出设置相关命令
0×07 实战-导入数据前的准备
一、确定数据的存储和归类
确定数据存储在Splunk Enterprise中的哪个索引(index)中:针对不同类型的数据,建议分别存储在不同的索引中,便于数据的搜索和管理
为数据指定一个类型(sourcetype):对不同类型的数据进行归类
默认字段:index(指定特定索引), host(指定host 主机), sourcetype(数据源类型),source(日志文件路径)
二、确定编码类型
Splunk支持多种编码类型
默认编码UTF-8
中文字符编码HZ 如果包含中文字符,建议采用HZ编码
可以在数据预览时选择适合的编码
通过修改配置文件设定编码,设置全局默认编码,或为特定的数据类型设定编码:
编辑local 下的props.conf 文件(/opt/splunk/etc/system/default/props.conf):
(注:此类配置到Splunk enterprise中,非转发器中)
[default]
CHARSET=HZ
三、确定时间戳
时间戳非常重要。
如果被转发的日志中不带时间戳,则将当前索引这些数据进来的时间设置为时间戳。
时间戳是否可以正常识别,如无法正确识别,则需配置。
四、数据预览
最佳实践—通常在将数据导入Splunk之前,建议先取小部分来进行测试,通过Splunk提供的“数据预览”功能来验证数据是否可以正确导入,是否需要额外配置。这样做可以避免,如果数据未正确导入则可能需要重新导入数据的情况。
复制额外配置并保存到props.conf配置文件中。
五、实战导入Linux审计日志
Web页面的方式
1)、进入Splunk Web界面, 设置→数据:索引→新建索引→键入索引名称
2)、设置→添加数据→监视→文件和目录→文件或目录:浏览 需要导入的数据

#连续监视:不断实时地监控,一旦有新增记录则索引到splunk
#索引一次:只会将文件索引一次,后续新增的将不会被索引到splunk中
3)、单击下一步,进入来源类型;此处设置 来源类型。再进入一下在输入设置中设置索引为我们刚创建的索引。
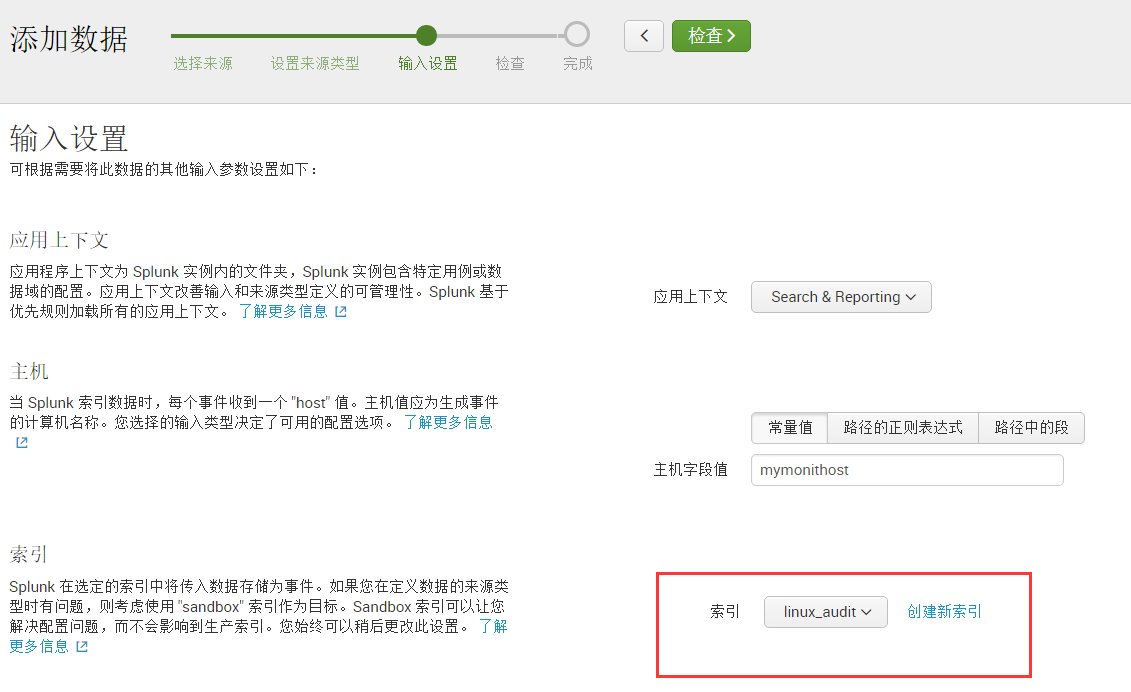
4)、最后提交完成,变可以再search & reporting中查询得到索引内容
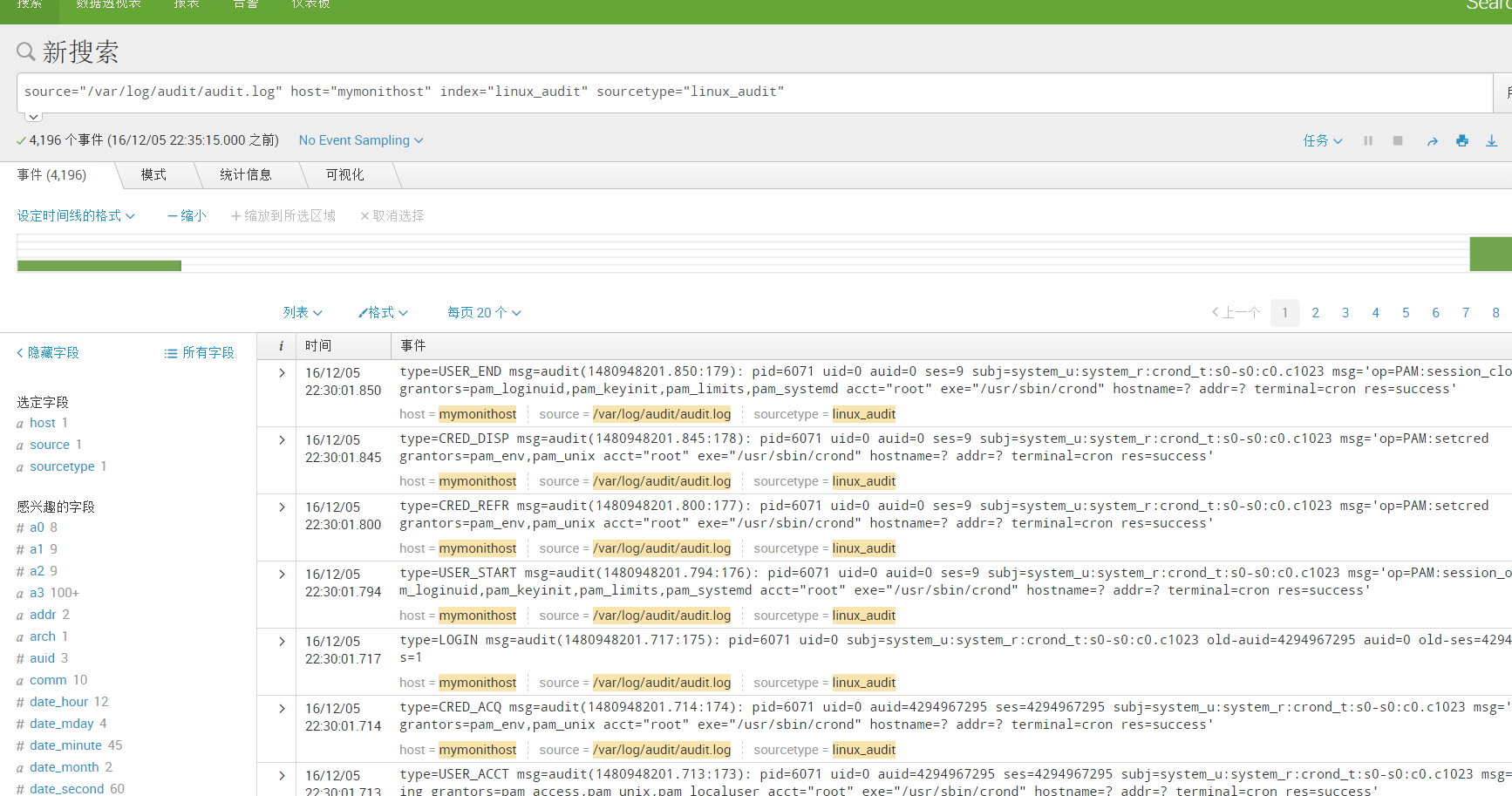
命令行方式执行
1)、切换到/opt/splunk/bin中,使用./splunk add index linux_audit命令新增索引。

2)、修改配置文件/opt/splunk/etc/apps/search/local/inpust.conf(如果没有请新建),添加如下:
[monitor:///var/log/audit/audit.log]
disabled = false
index = linux_audit
sourcetype = linux_audit
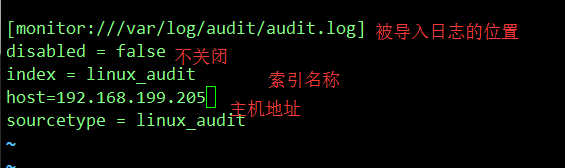
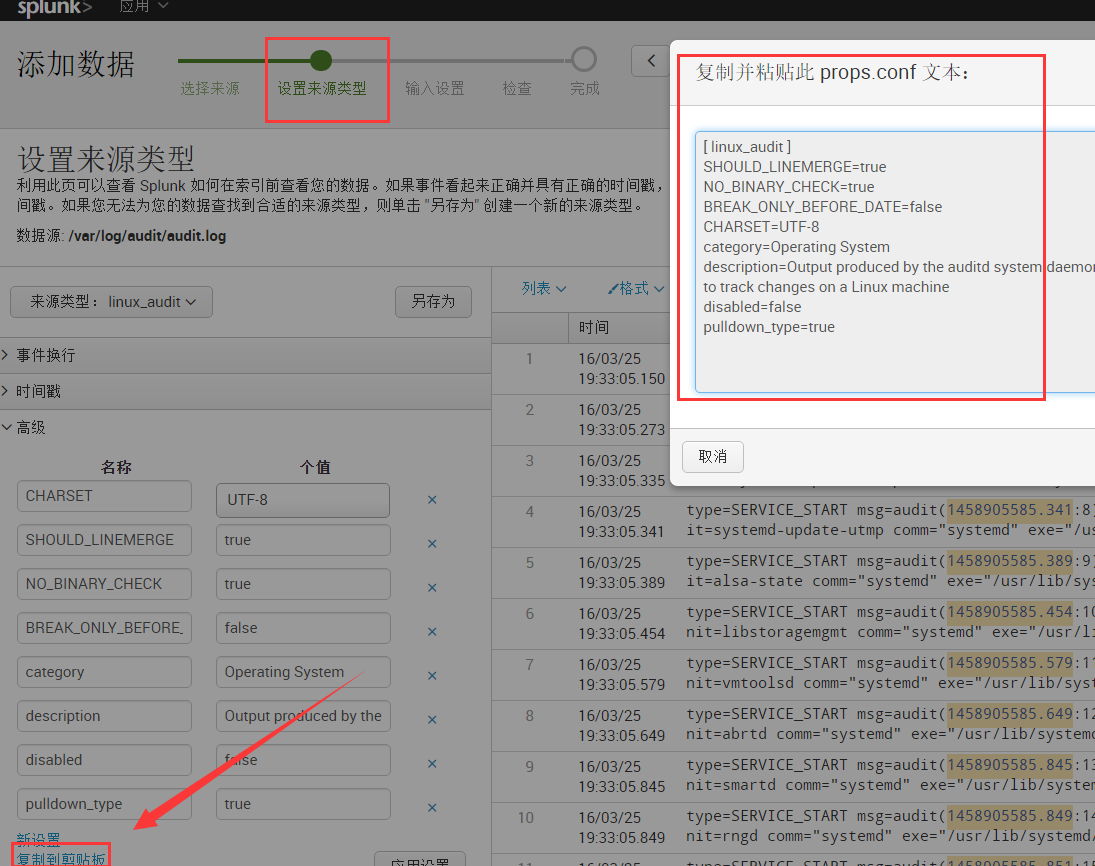
3)、同样在该目录下创建props.conf文件,填写如下信息:
[ linux_audit ]
SHOULD_LINEMERGE=true
NO_BINARY_CHECK=true
BREAK_ONLY_BEFORE_DATE=false
CHARSET=UTF-8
category=Operating System
description=Output produced by the auditd system daemon used to track changes on a Linux machine
disabled=false
pulldown_type=true

这些信息实际上和在Web设置来源类型中的参数配置是一样的:
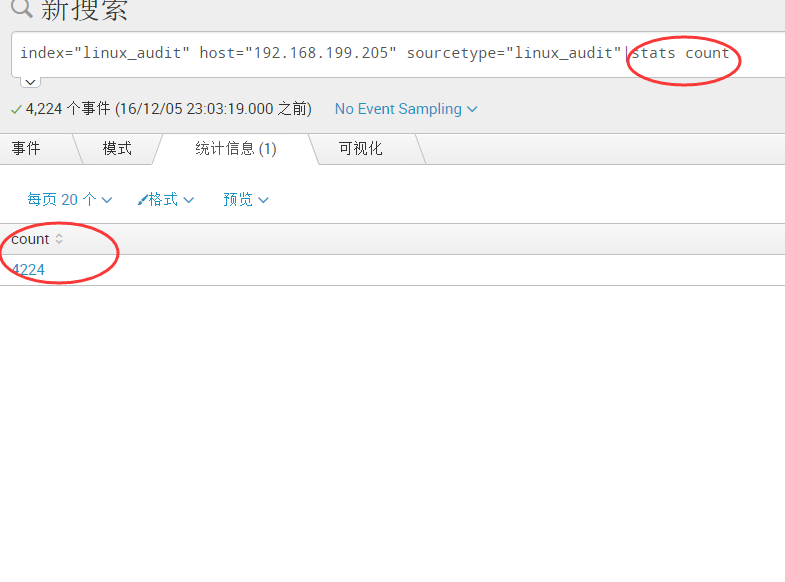
4)最后使用./splunk restart重启服务即可!在search & reporting上我们像之前我们提到的一样搜索日志信息,我们使用 “stats count” 来统计日志的数量:
0×08 实战-导入并分析本地数据-1
一、创建索引
创建名为tutorialdata 的索引
二、数据介绍
上传示例数据压缩包,Splunk支持.zip和.tar.gz等压缩包格式,splunk会对上传的压缩包自动解压缩
该压缩包包含三类数据(我当前测试的压缩包):
access.log,Apache访问日志
secure.log,安全日志
三、数据
采用上传(Upload)的方式从本地导入数据
// Splunk有 上传、监视本地、来自转发三种添加数据的方式
设定路径中的段为主机名,如压缩包:/waf/secure.log,我们可以取waf为主机host名称
Splunk会自动为它们确定数据源类型(sourcetype)
创建单独的App,名为TutorialData,并在该App中查看导入的数据
步骤:
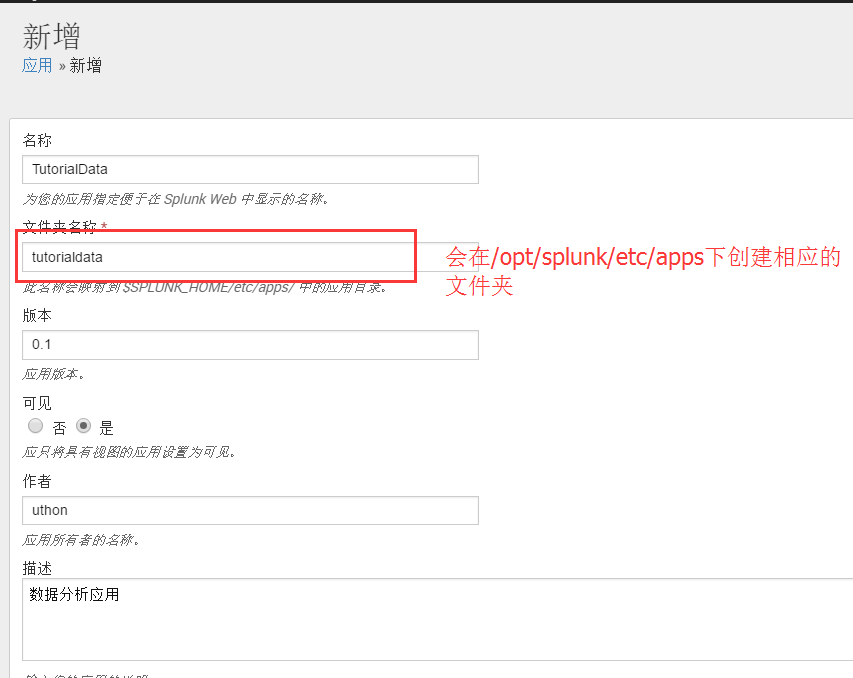
1)、 首先要创建APP,进入Splunk web界面,左上角点击“应用”→管理应用→创建应用
2)、 开始添加数据,左上角选择刚才创建的应用。然后设置→添加数据→上载→上传刚才的文件→
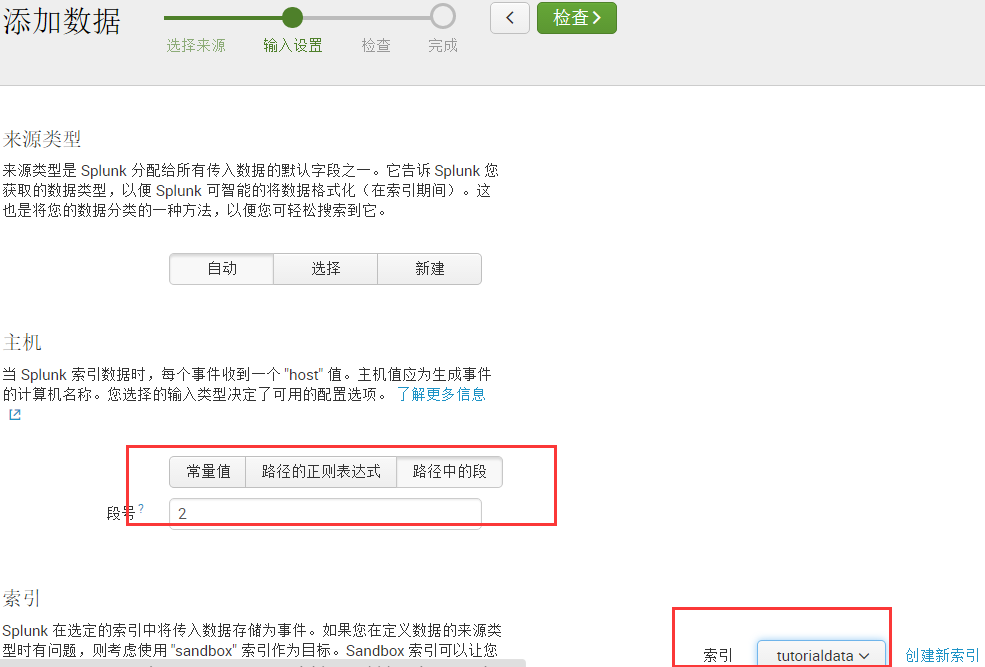
3 )、在输入设置中主机名称可设置为:路径中的段,此处输入“2”表示二级目录的名称命令主机,即可我压缩包中/logs/apache/access.log,则以apache作为主机名。索引则设置我们刚才设置的索引。
上载完毕之后可以开始搜索了。
四、搜索界面
搜索界面介绍
source="tutorialdata.zip:*" index="tutorialdata“字段列表
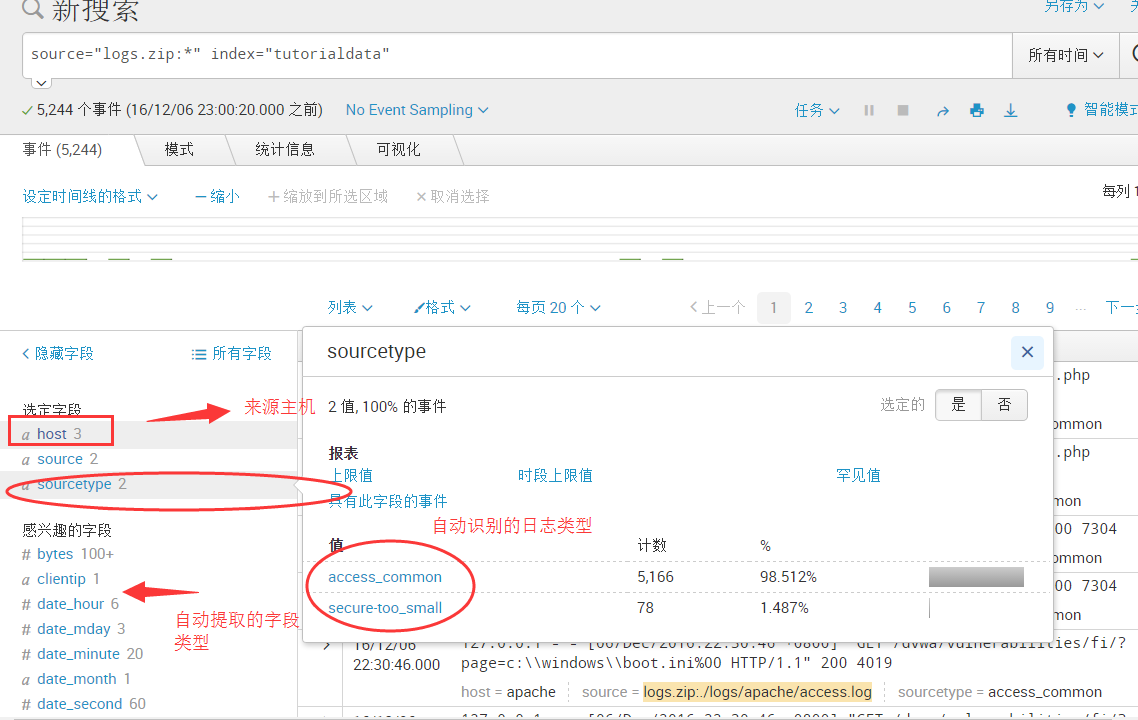
例如搜索:
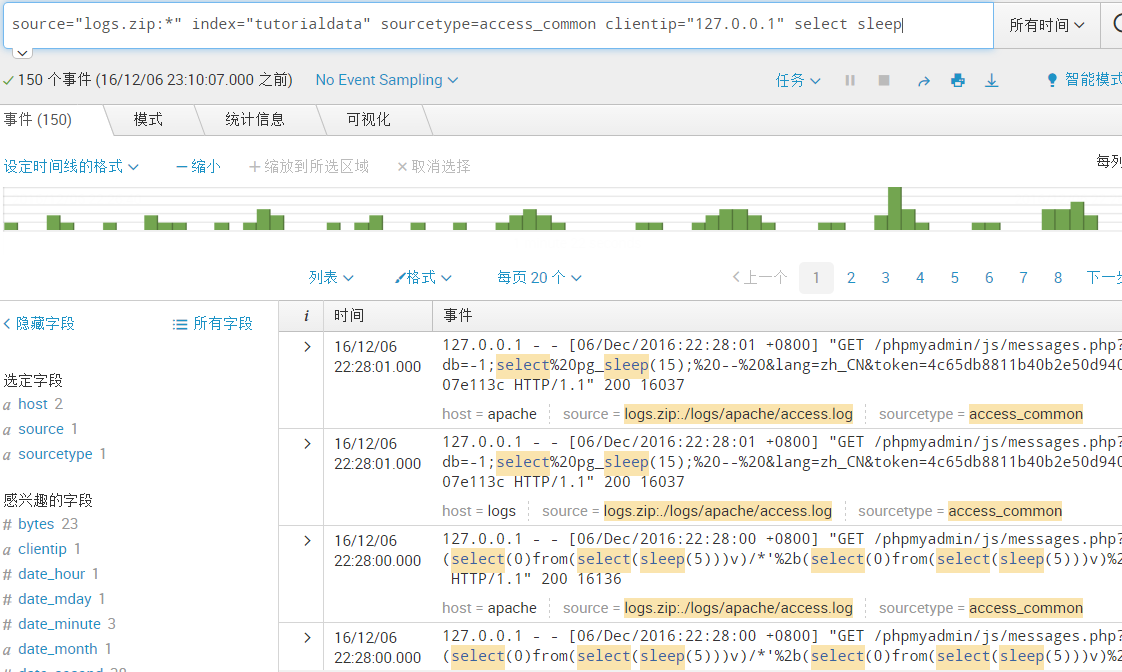
source="logs.zip:*" index="tutorialdata" sourcetype=access_common clientip="127.0.0.1" select sleep 解释: #来源logs.zip 索引为:tutorialdata 源类型为:通用访问日志 搜索日志中IP为:127.0.0.1 关键字包括select 和 sleep
其它语法:
source="logs.zip:*" index="tutorialdata" (script OR select)#: (select OR union) 逻辑或。满足一个即可。 关键字OR要大写
source="logs.zip:" index="tutorialdata" sele#:通配符*代表后面任意
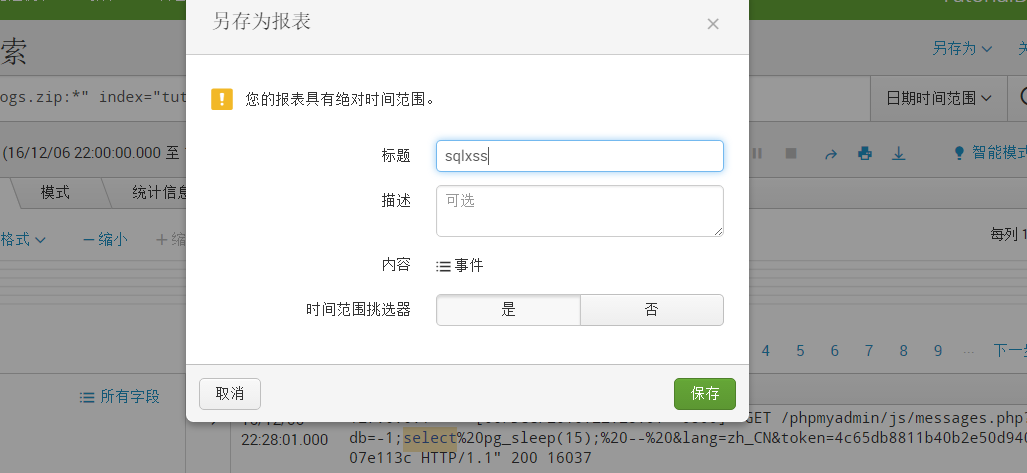
我们在在右上角 “另存为——>报表”,输入标题则可保存为报表。如果你后期想修改,可在“编辑——>在搜索中打开——>修改搜索语句——>保存” 重新保存之后即可。
还可以使用统计数量之后,可视化的形式进行查看、另存为:仪表板面板、报表、告警等等

五、Splunk的搜索语言(head&tail)
管道运算符(|),将管道左边搜索产生的结果作为右边的输入 head, 返回前n 个(离现在时间最近的)结果 tail, 返回后n 个(离现在时间最后的)结果,如
index="tutorialdata" sourcetype="access_common" select | head 2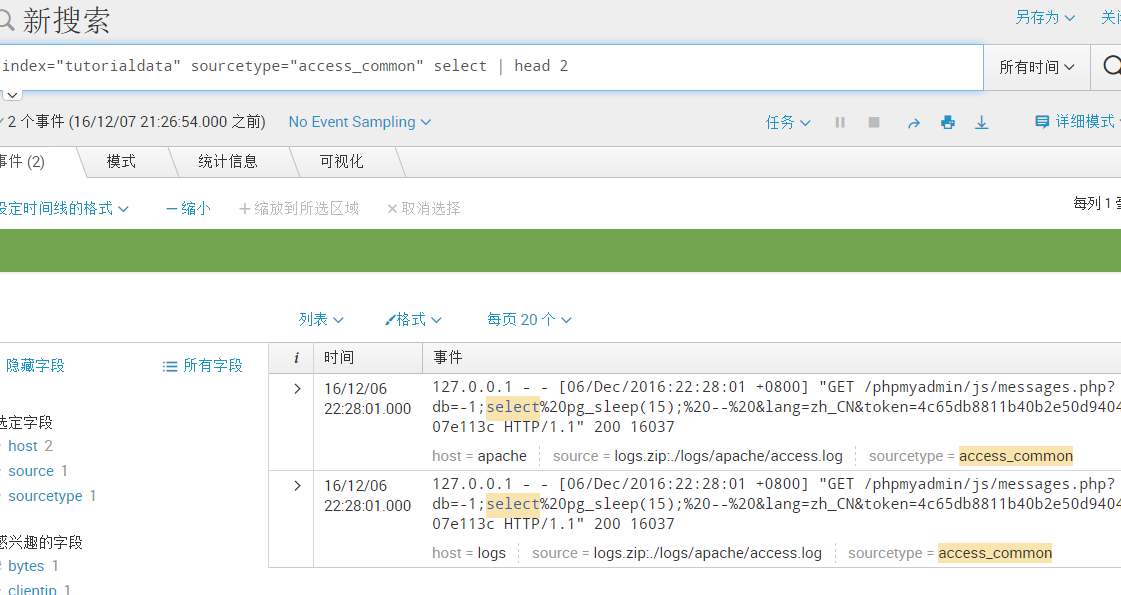
index="tutorialdata" sourcetype="access_common" select | tail 2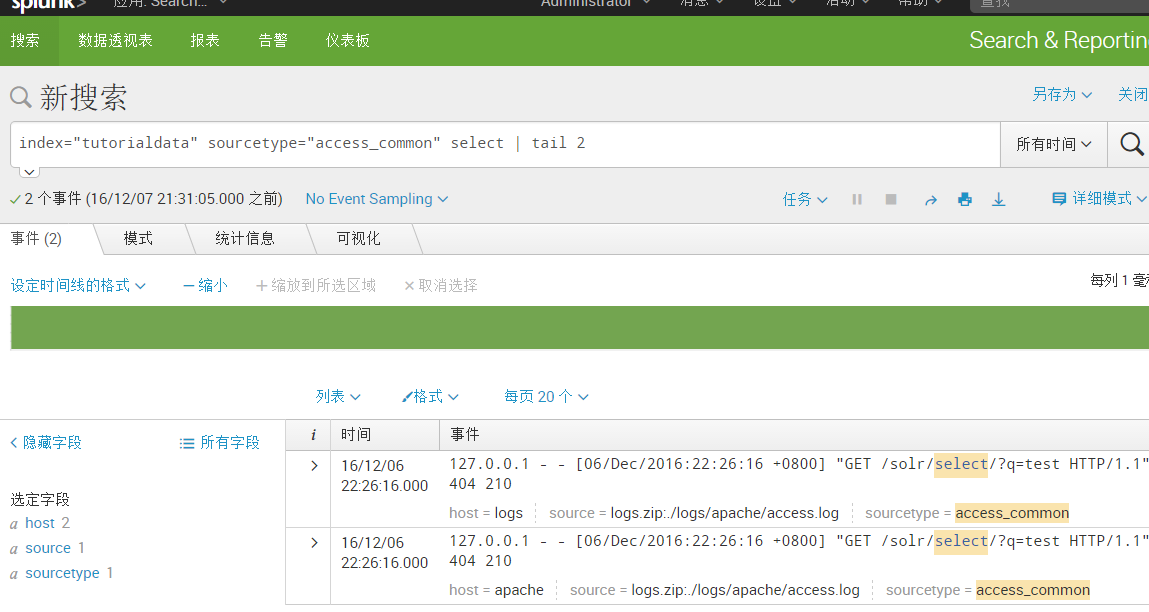
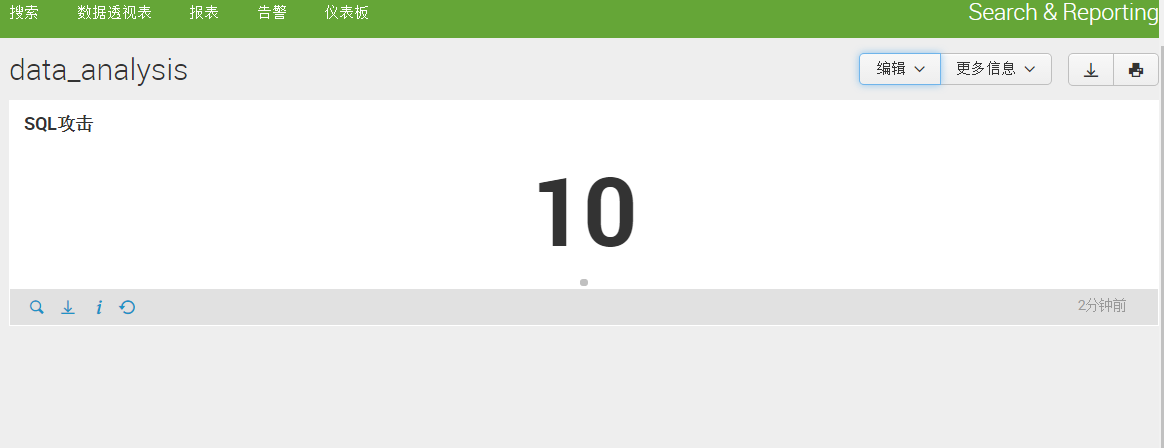
通过 SPL语言搜索、过滤的结果也可以保存为仪盘表,(此处我还做了单值型的可视化)。如下图:

六、Splunk的搜索语言(top、rare、rename as )
top, 显示字段最常见/出现次数最多的值
rare, 显示字段出现次数最少的值
limit,限制查询,如:limit 5,限制结果的前5条
rename xx as zz : 为xx字段设置别名为zz,多个之间用 ,隔开
fields :保留或删除搜索结果中的字段。fiels – xx 删除xx字段,保留则不需要 – 符号
source="tutorialdata.zip:*" index="tutorialdata" | top clientip (获取出现次数最多的IP,降序排列)
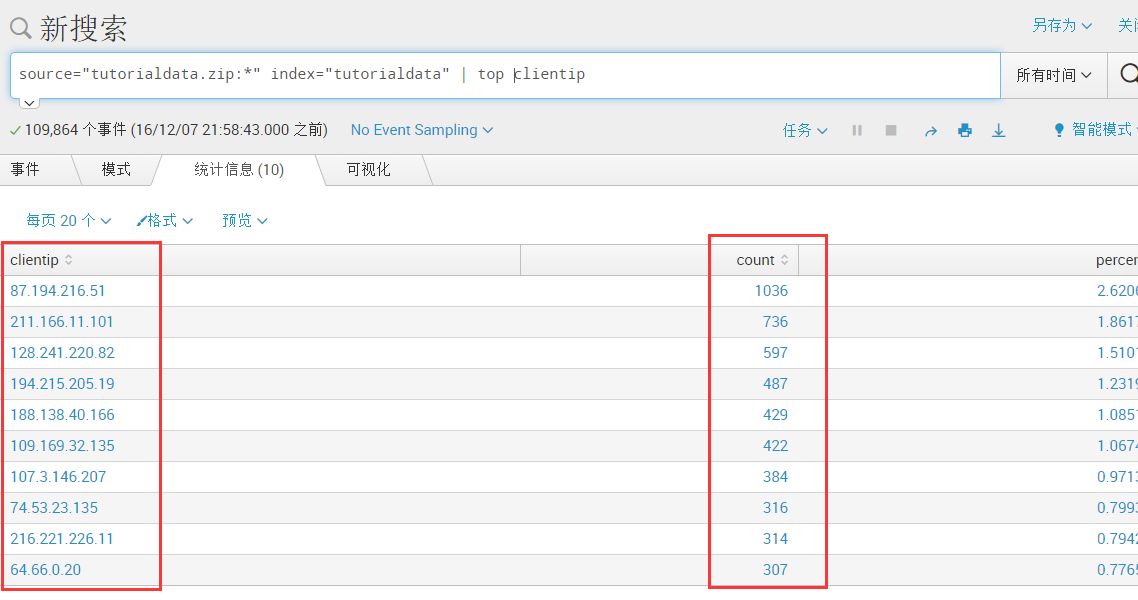
source="tutorialdata.zip:*" index="tutorialdata" | top clientip limit=5 (在上方结果中限制显示前5条)
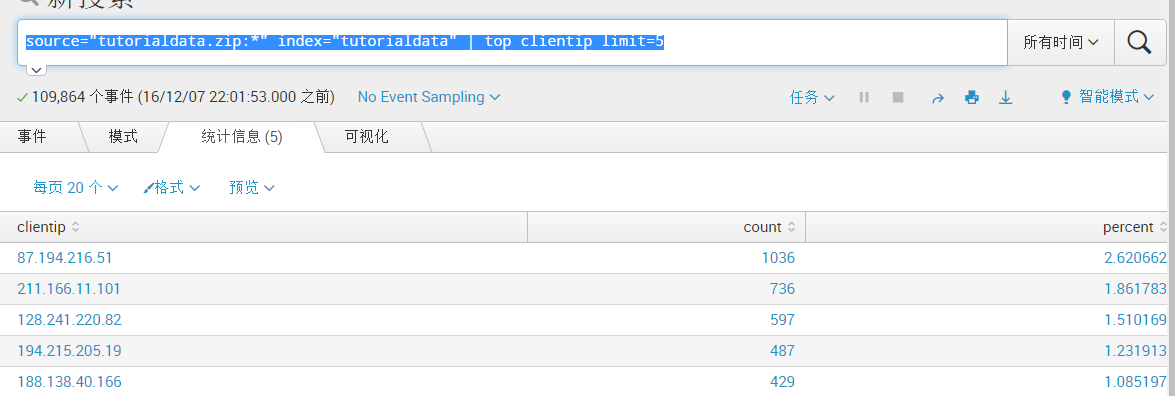
#source="tutorialdata.zip:*" index="tutorialdata" | top clientip |rename clientip as “攻击源” |rename count as "攻击次数" (为两个字段设置别名)
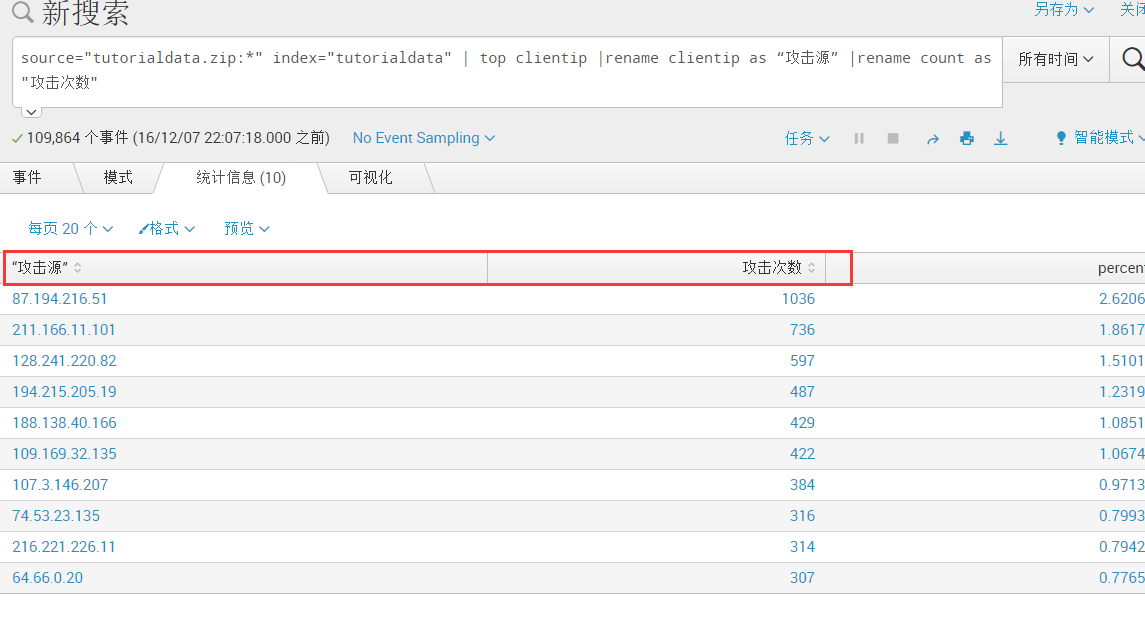

可以保存为饼状图的仪表盘
source="tutorialdata.zip:*" index="tutorialdata" | rare clientip (返回clientip最少的10个,升序排序)

0×09 实战-导入并分析本地数据-2
一、Splunk的搜索语言(table,sort)
table :返回仅由参数中指定的字段所形成的表。如:table _time,clientip,返回的列表中只有这两个字段,多个字段用逗号隔开
基于某个字段排序(升序、降序),降序的字段前面要使用-号,升序的使用+
sort -clientip, +status, 先基于clientip降序排列之后,再对这个结果基于status升序
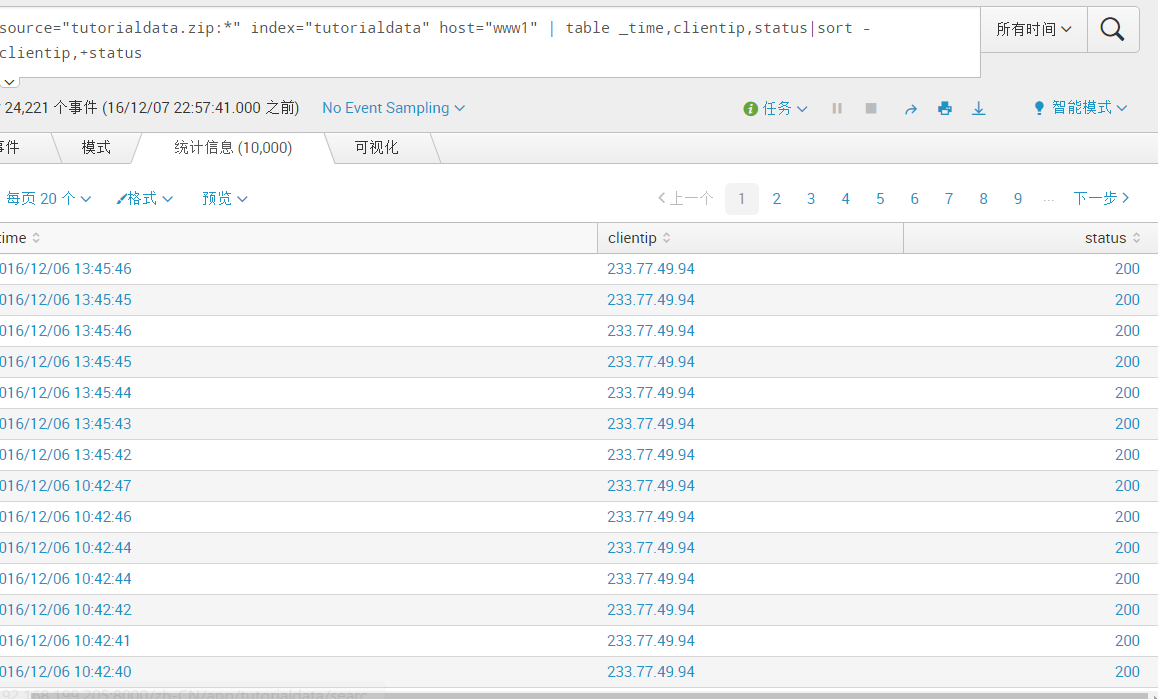
source="tutorialdata.zip:*" index="tutorialdata" host="www1" | table _time,clientip,status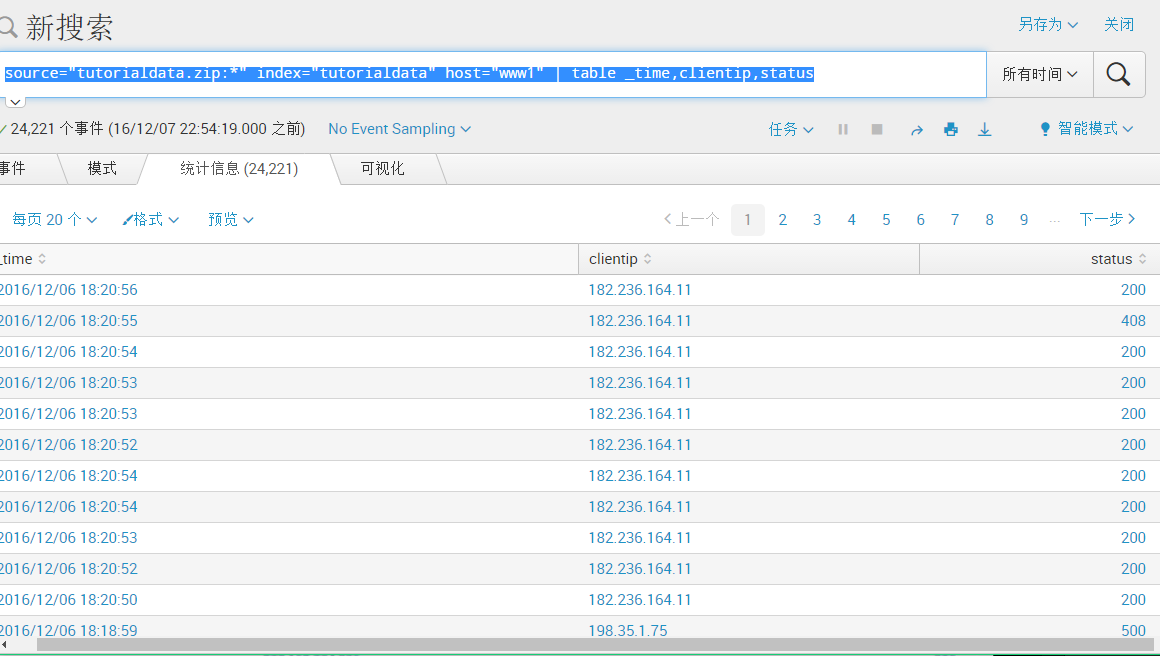
source="tutorialdata.zip:*" index="tutorialdata" host="www1" | table _time,clientip,status|sort -clientip,+status (针对上述中先基于clientip降序排列之后,再对这个结果基于status升序)
二、Splunk的搜索语言(stats)
对满足条件的事件进行统计
stats count() :括号中可以插入字段,主要作用对事件进行计数
stats dc():distinct count,去重之后对唯一值进行统计
stats values(),去重复后列出括号中的字段内容
stats list(),未去重之后列出括号指定字段的内容
stats avg(),求平均值
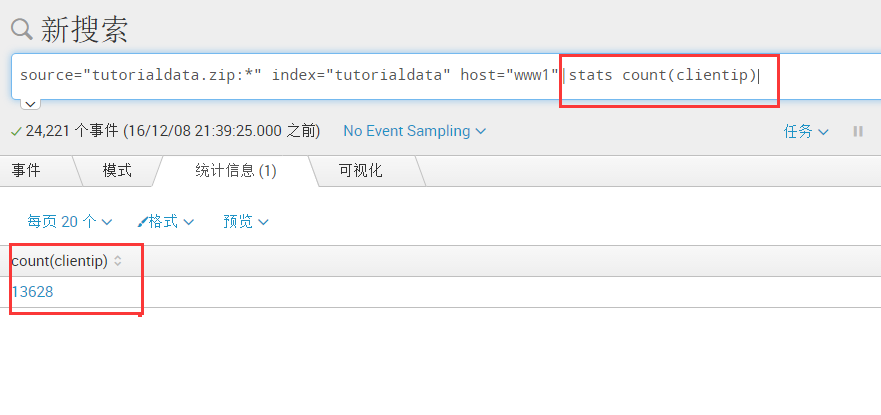
source="tutorialdata.zip:*" index="tutorialdata" host="www1"|stats count(clientip)[统计clientip数量]
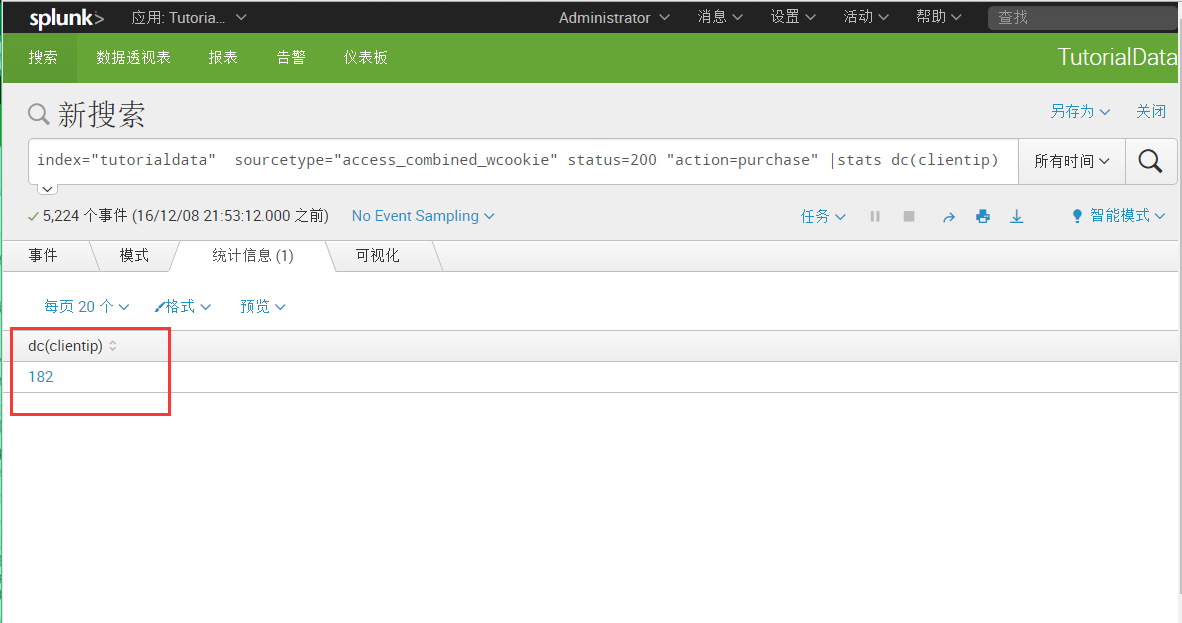
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" |stats dc(clientip) [dc去重复之后再进行统计]
可视化可以使用“径向仪表”,对满足一定数量进行不同颜色标记,可存为现有的仪表盘面板。

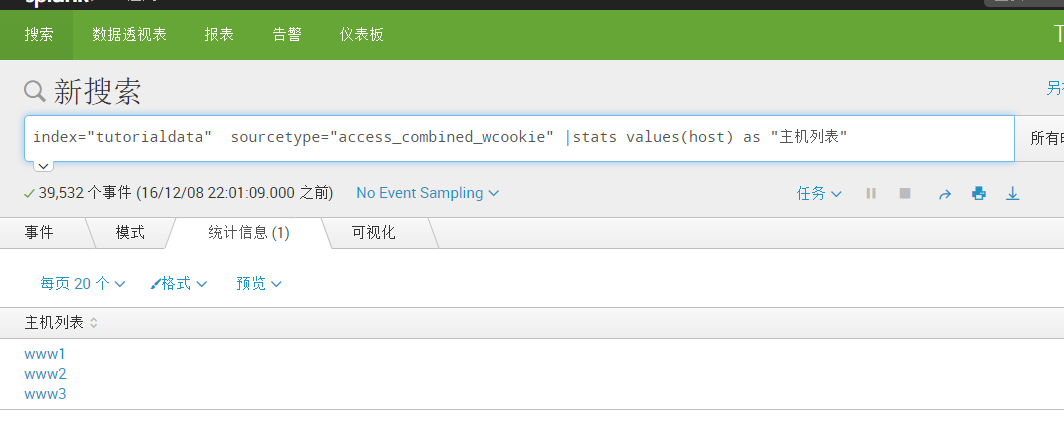
index="tutorialdata" sourcetype="access_combined_wcookie" |stats values(host) as "主机列表" [去除重复后列出字段的内容]
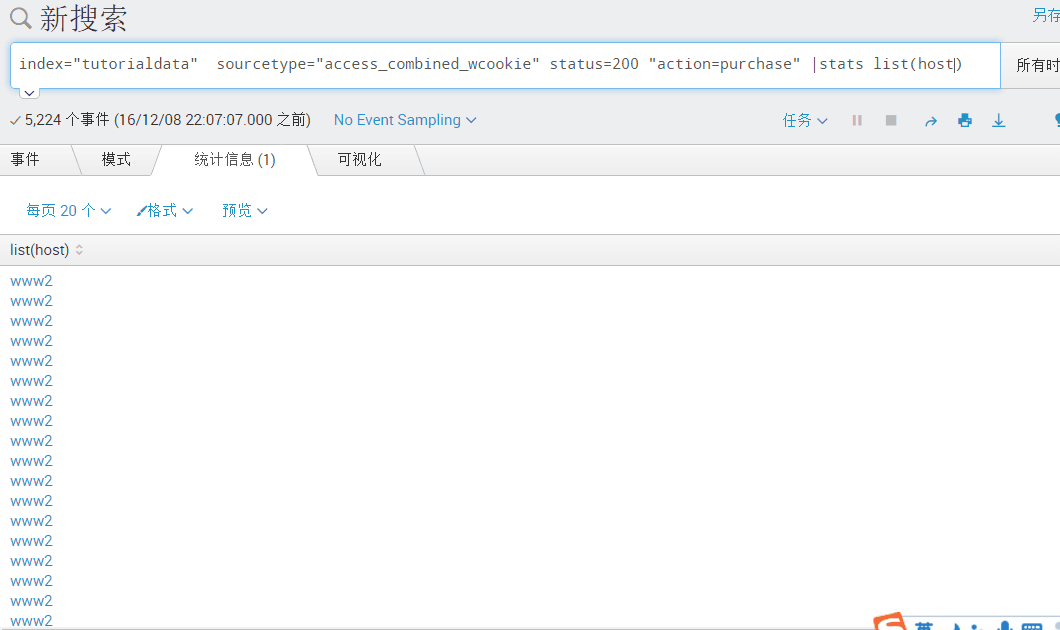
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" |stats list(host) [未去除重复列出括号中的内容]
三、Splunk的搜索语言(chart)
在用于制作图表的表格输出中返回结果。
chart count():
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | chart count by host[统计字段status=200以及action=purchase的事件,并且以host字段来进行排列显示]
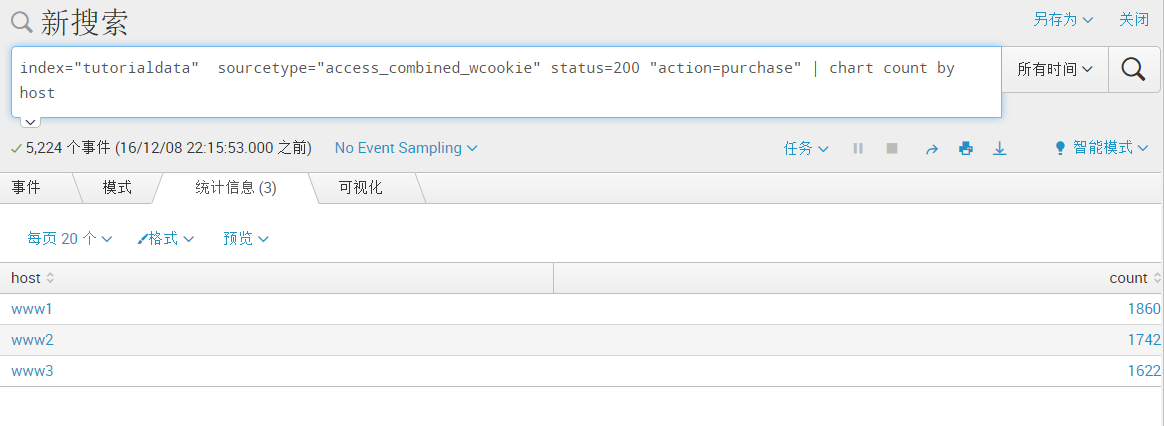
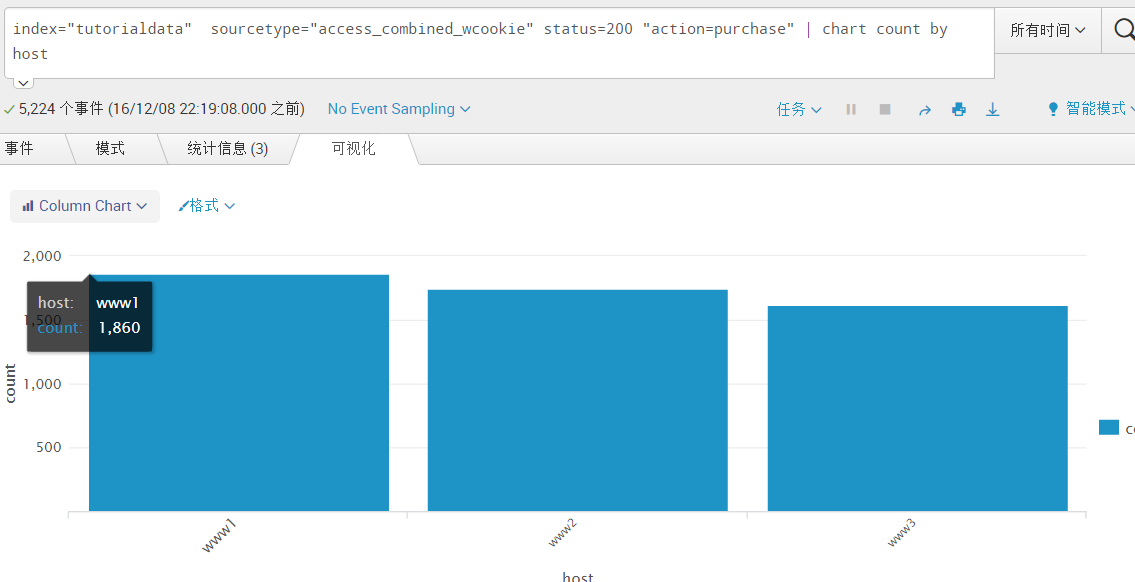
chart max()
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | chart count by host|chart max(count)[求出最大值]
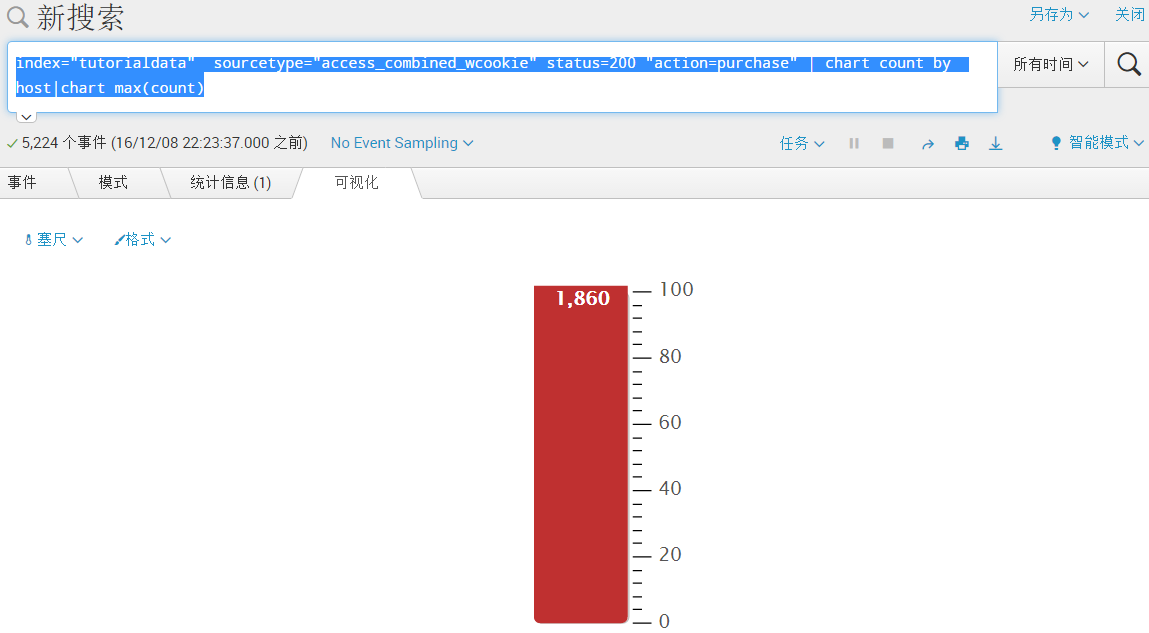
chart min()
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | chart count by host|chart min(count) [求出最小值]

chart avg()
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | chart count by host|chart avg(count)[根据第一次的结果求出平均值]
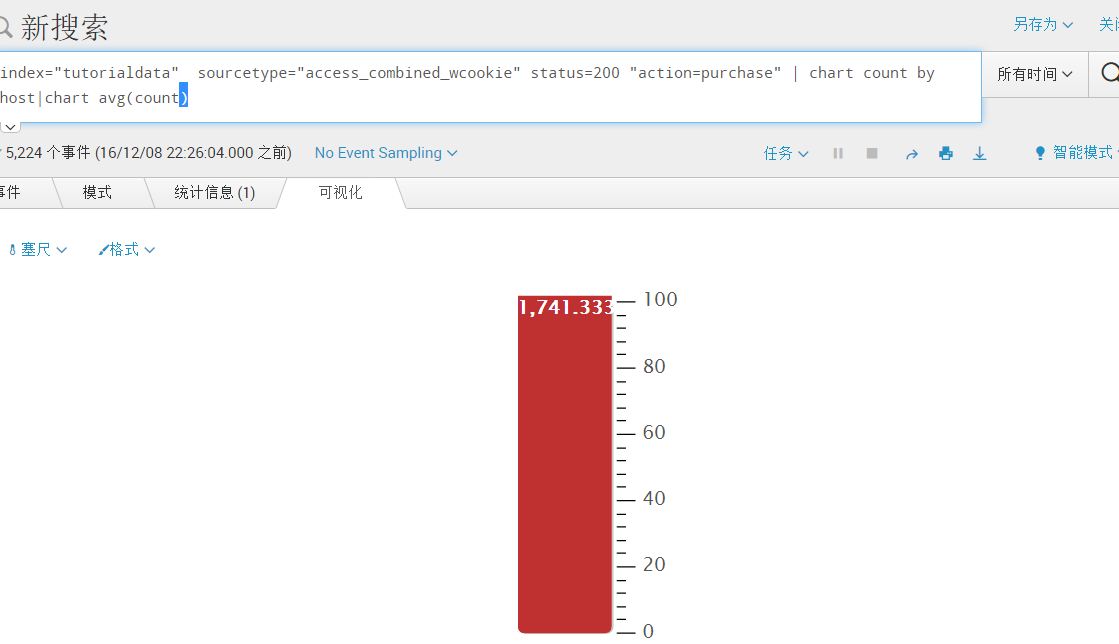
四、Splunk的搜索语言(timechart)
使用相应的统计信息创建时间系列图表
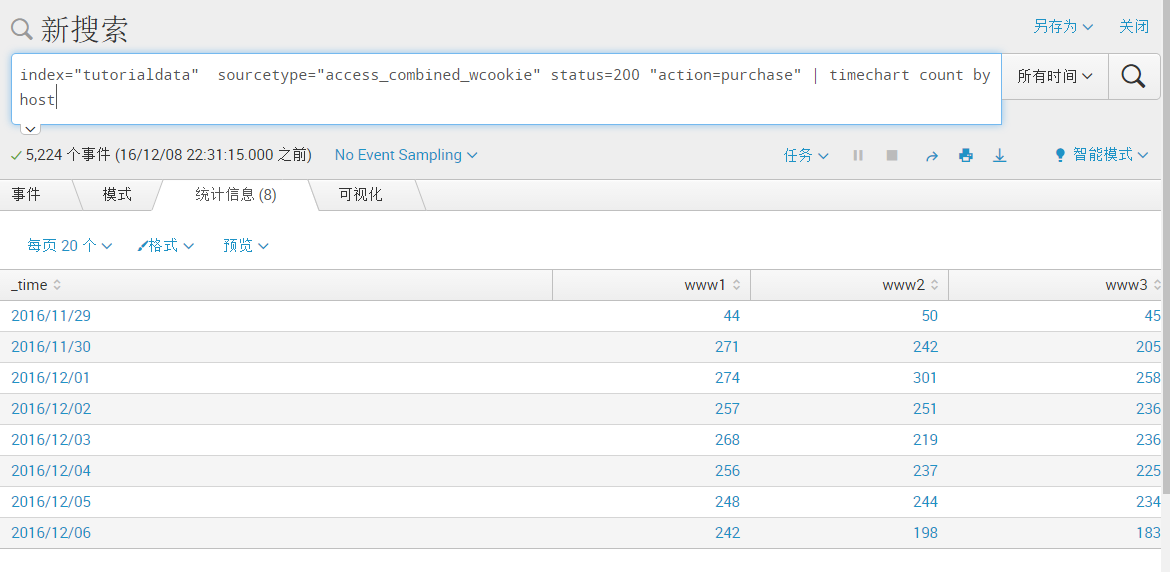
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | timechart count by host [可以看到以每天作为时间分隔统计,在每24小时中满足条件的通过host字段进行统计]
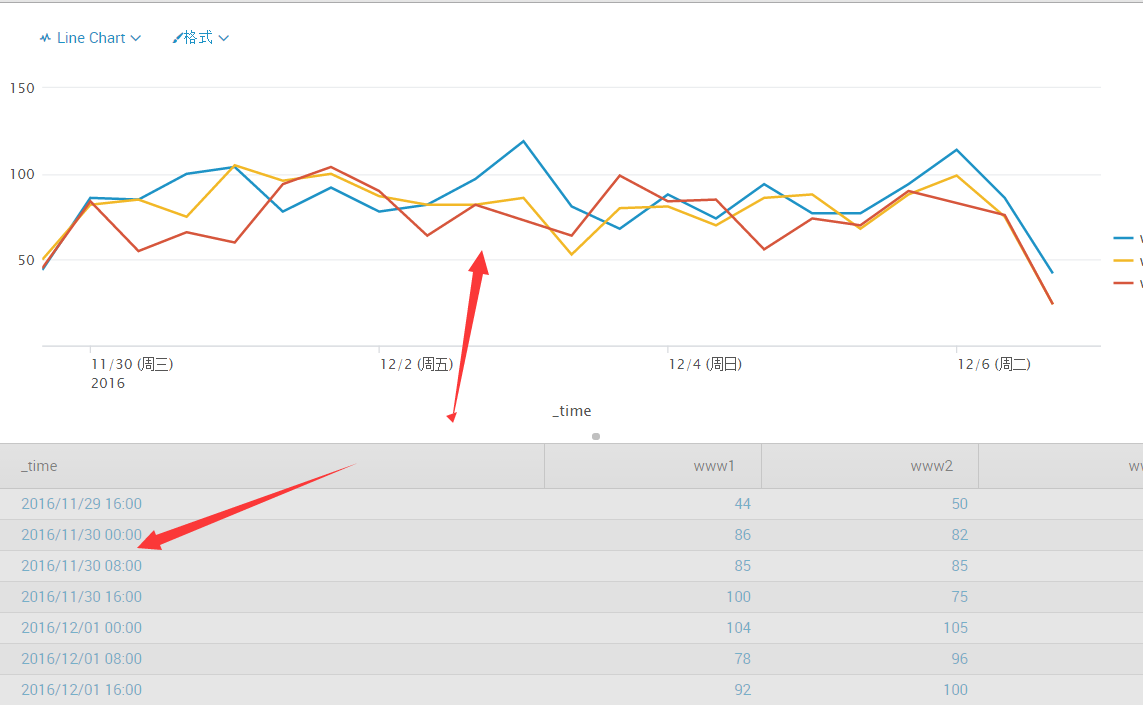
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | timechart span=8h count by host[加入span参数来定义时间间隔为8h一次分隔统计]
五、子搜索([search ])
子搜索包含在方括号[]中
注:以下字段中含义:action=purchase代表成功购买产品 status表示状态为200
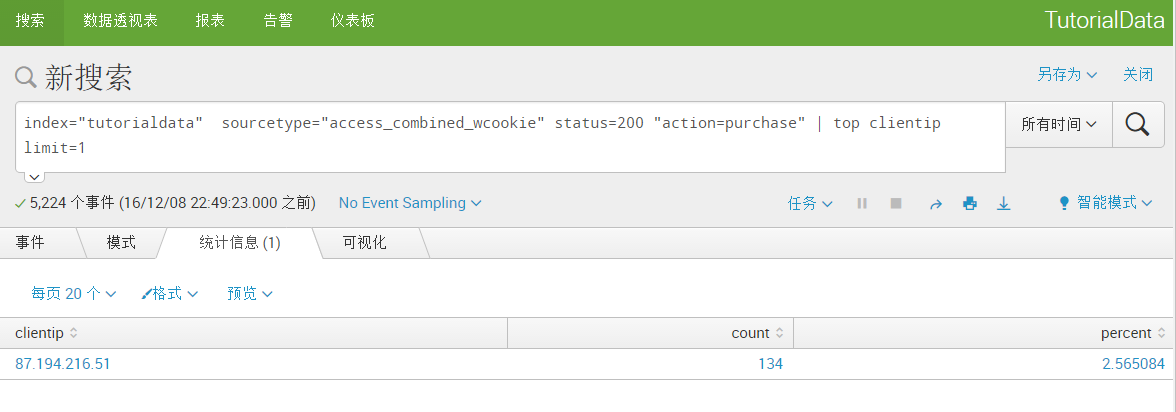
index="tutorialdata" sourcetype="access_combined_wcookie" status=200 "action=purchase" | top clientip limit=1(搜索满足成功购买产品、状态为200的,出现数量最多的IP,只取最高的那个)
index="tutorialdata" sourcetype="access_combined_wcookie" "action=purchase" status=200 clientip="87.194.216.51"|stats count dc(productId),values(productId) by clientip(搜成功购买,状态为200,IP为:87.194.216.51,统计购买产品的数量,并且去重复地列出具体的名称,最后通过clientip排序显示)
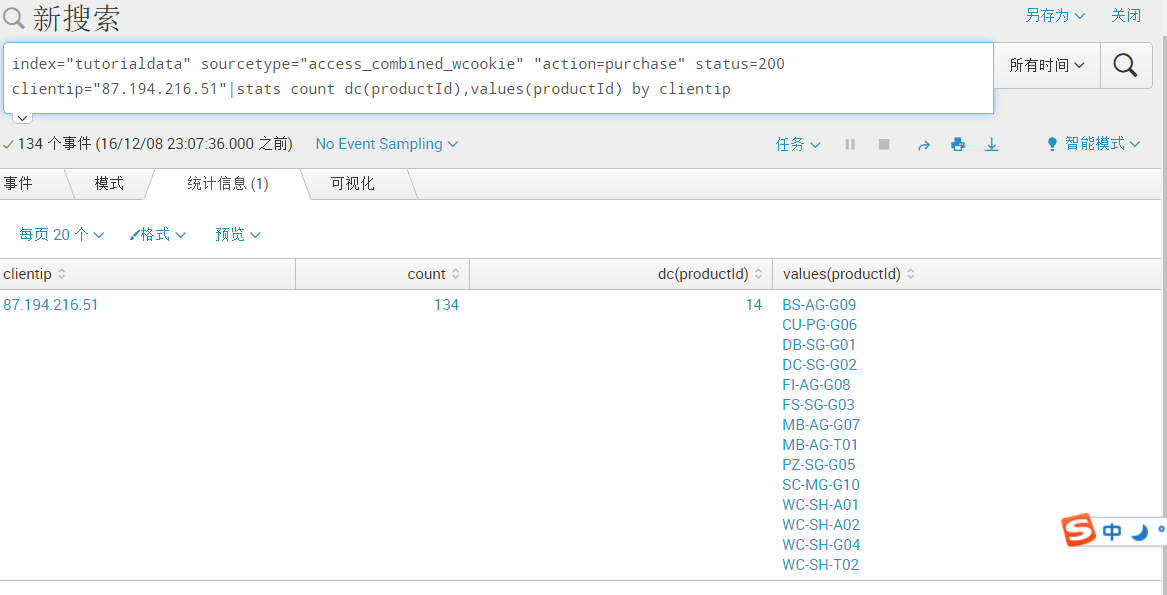
合并上面两个语句,子搜索放在[]中
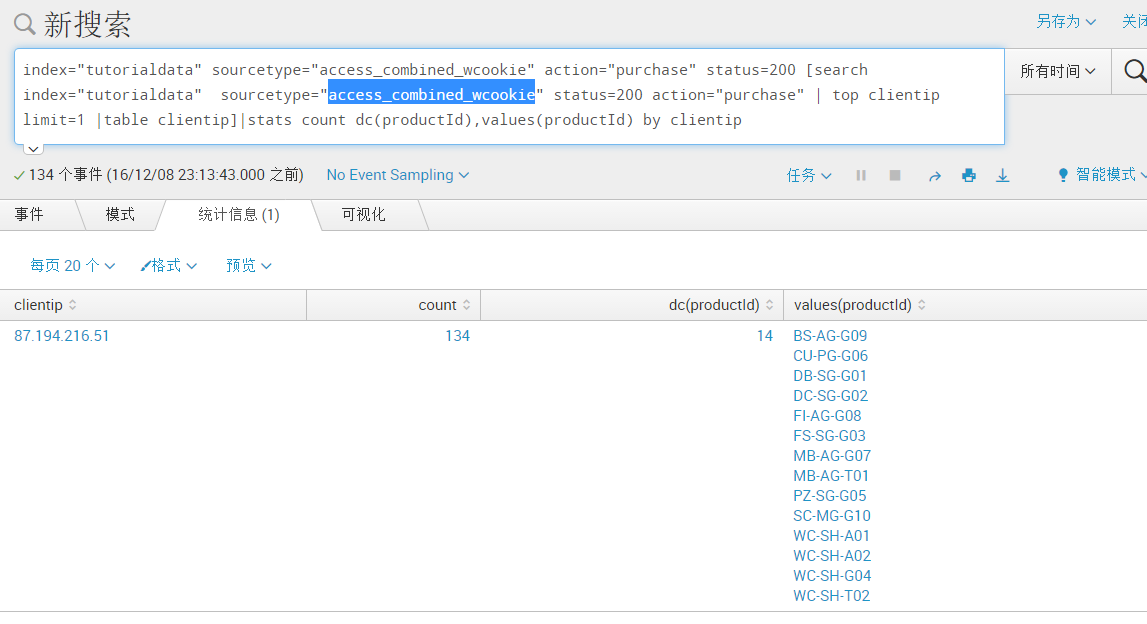
index="tutorialdata" sourcetype="access_combined_wcookie" action="purchase" status=200 [search index="tutorialdata" sourcetype="access_combined_wcookie" status=200 action="purchase" | top clientip limit=1 |table clientip]|stats count dc(productId),values(productId) by clientip(上面的clientip是通过子搜索 search 后面的结果,最后使用了“|table clientip”来只显示clientip字段,最后再进行如上次的统计数量和明细)
可视化后添加到仪表盘,可将现有仪表盘生成PDF。
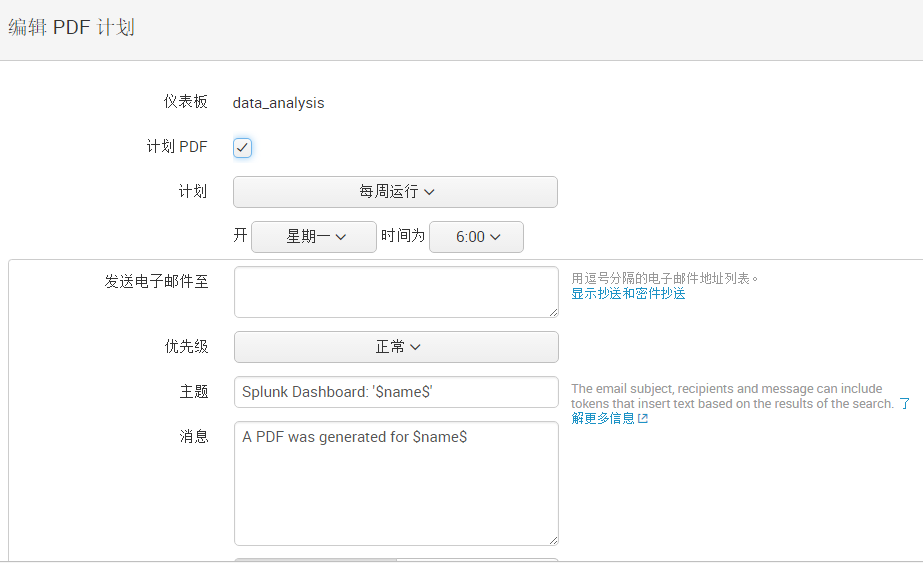
还可以通过“PDF计划交付”来定时通过邮箱将报表发送给指定用户。
0×10 使用转发器转发数据
一、数据准备
三个主机的Apache 访问日志,Splunk可以自动识别该类型
位于/opt/log目录下
日志文件来自三台服务器,因此需要区分三台服务器
预览数据:
/opt/log/BigDBbook-www1
/opt/log/BigDBbook-www2/opt/log/BigDBbook-www3
二、服务器端配置(Splunk Enterprise: Cent OS 7:192.168.199.205)
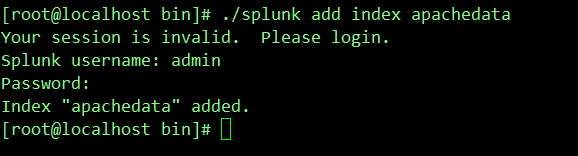
创建新索引apachedata
./splunk add index apachedata
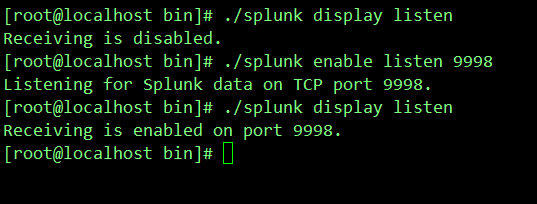
新增接收端口9998
./splunk enable listen 9998
三、客户端配置(ubuntu 192.168.213.129)
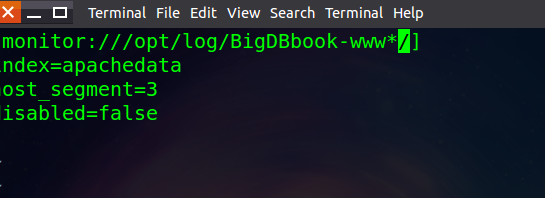
修改配置文件添加监控项
~ vim /opt/splunkforwarder/etc/apps/search/local 如果没有local则创建该目录
创建inputs.conf ,配置如下:
明确index,host,sourcetype字段
[monitor:///opt/log/BigDBbook-www/] //设置监控/opt/log/下的所有BigDBbook-www开头的目录下的日志,记得“/”符号
index=apachedata //设置索引名称为服务端创建的:apachedata
host_segment=3 // 为这三个日志设置主机名称,取名的方式将第三级目录作为名称命令,如:/opt/log/BigDBbook-www1
disabled=false //非关闭状态的监控
使用CLI命令添加转发服务器,转发端口9998
~ sudo ./splunk add forward-server 192.168.199.205:9998

查看监控状态,处于活动状态:
~sudo ./splunk list forward-server

重启服务器
~ sudo ./splunk restart
四、确认接收数据
确认数据已正确接收
验证host字段是否正确
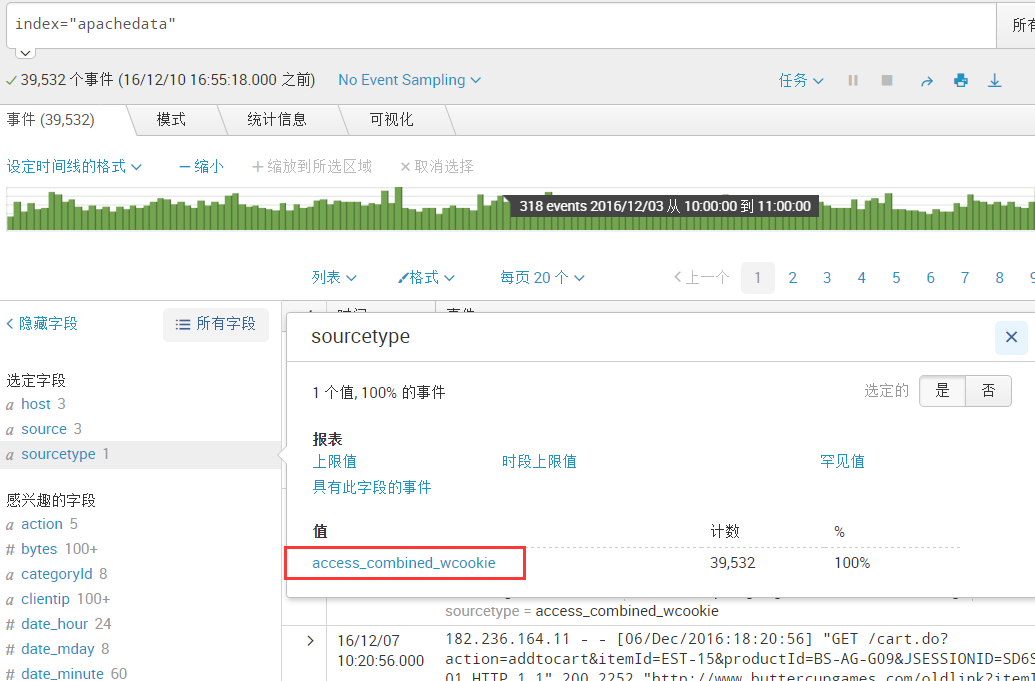
通过索引可以看到splunk已经接收了日志,host主机名称也已经以日志路径的第三级目录名字进行命名了

sourcetype 被splunk自动识别为access_combined_wcookie
0×11 实战- 数据分析和可视化-1
一、Apache日志中HTTP状态码分析
服务器响应客户端请求的状态码:
200表示请求成功
4xx表示客户端错误
5xx表示服务器错误
400-请求失败,服务器无法识别当前客户端请求;
401-未进行用户验证,当前客户端请求需要用户验证;
403-禁用,服务器已理解当前请求,但拒绝执行;
404-页面未找到;
500-内部服务器错误
503-服务不可用:由于服务器过载,服务器无法处理当前请求
#统计4xx和5xx事件数
index="apachedata" sourcetype="access_combined_wcookie" status > 200 | stats count by status 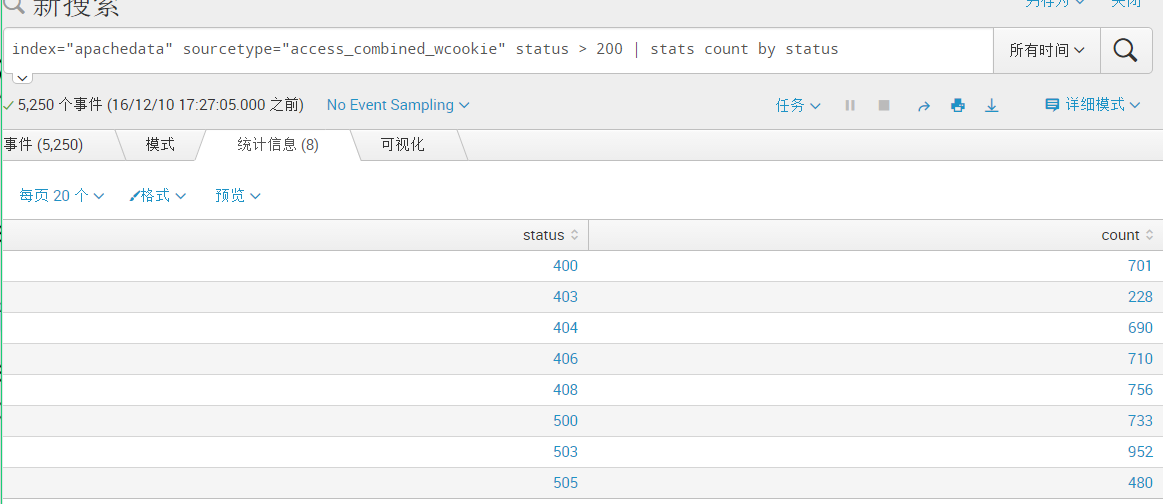
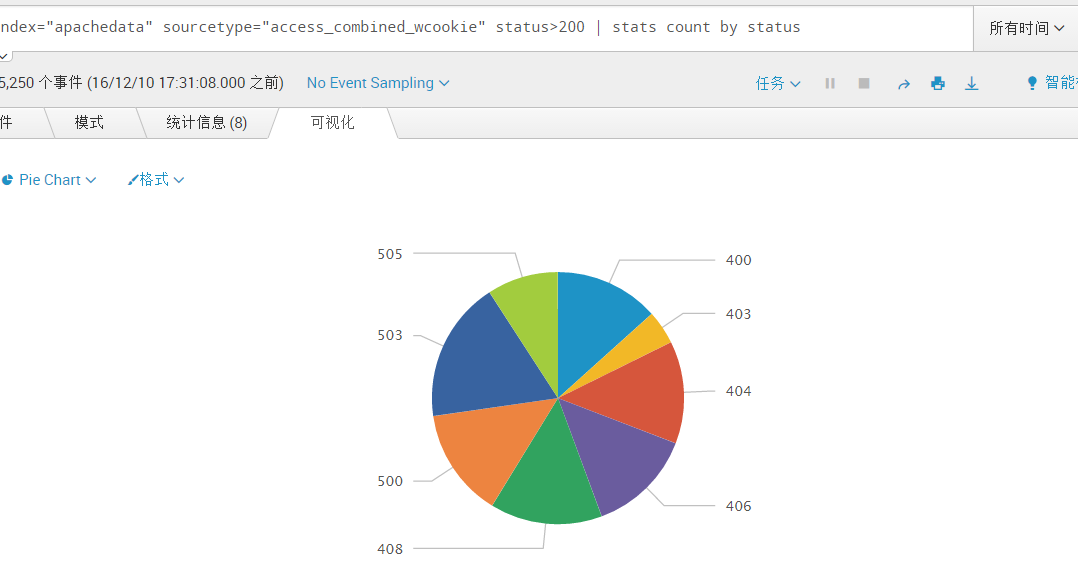
另存为饼状图,保存成一个新的仪表盘,仪表板标题我们取:Web日志分析,仪表板ID取:web_log,面板标题取:HTTP错误状态码分析。
统计4xx和5xx事件的时间趋势图(折线图、面积图、柱状图) ,可视化为line chart图形
index="apachedata" sourcetype="access_combined_wcookie" status>200 | timechart count by status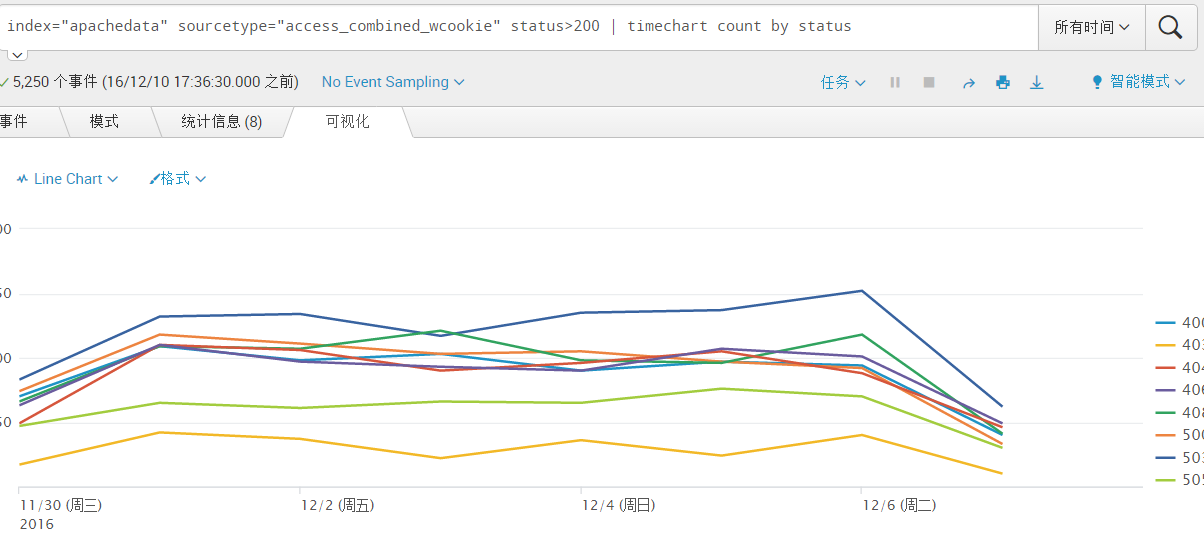
200表示“成功”,其他均为“错误”,统计事件数量
eval命令和if函数 eval-对表达式进行计算并将结果存储在某个字段中
if (条件,True的结果,False的结果)
index="apachedata" sourcetype="access_combined_wcookie" | eval success=if(status==200,"成功","错误")| timechart count by sucess解释:if函数判断status状态如果等于200则标记为成功字段,否则标记为错误字段,通过eval统计这些结果存储在sucess字段中,通过sucess字段排列,显示出成果与错误的数量

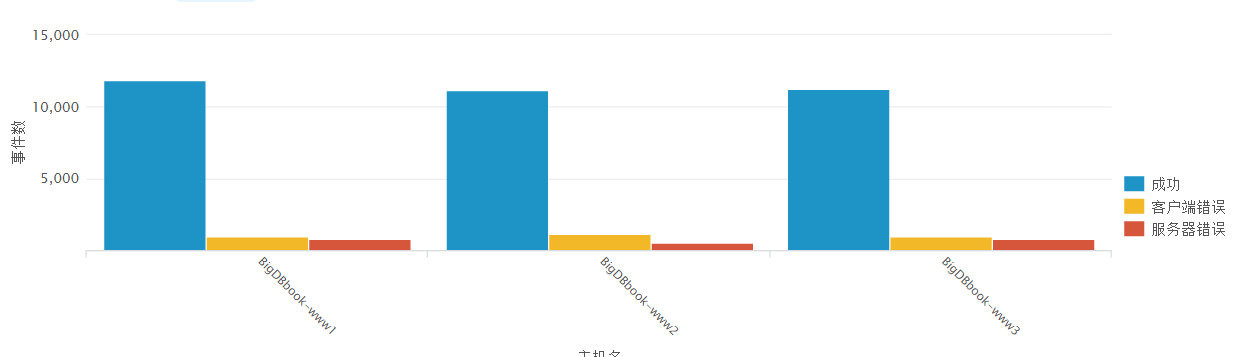
制作每一个主机的200、400和500事件数的对比图
200标记为“成功”,400标记为“客户端错误”,500标记为“服务器错误”,保存为column chart可视化图,另存现有仪表面板
index="apachedata" sourcetype="access_combined_wcookie" | chart count(eval(status==200)) as "成功", count(eval((400500 OR status==500)) as "服务器错误" by host解释: 统计status状态码等于200的别名则为成功,状态码大于400或者等于400,并且状态码要小于500则为 客户端错误,状态码大于500或者等于500的则为服务器错误,最后通过host字段排列

二、浏览器分析
.列出用户最常用的5种浏览器,可视化为Pie chart图,另存为现有仪表盘
index=apache sourcetype="access_combined_wcookie" | top useragentlimit=5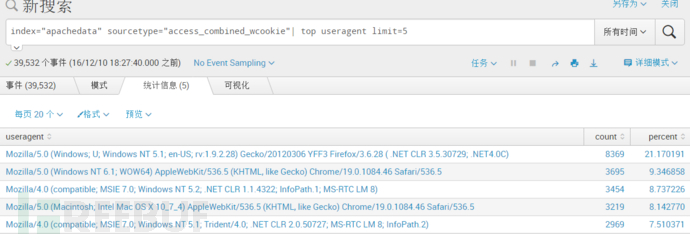

三、IP地址分析
排名前10的IP地址
index=apache sourcetype="access_combined_wcookie" | top clientiplimit=10
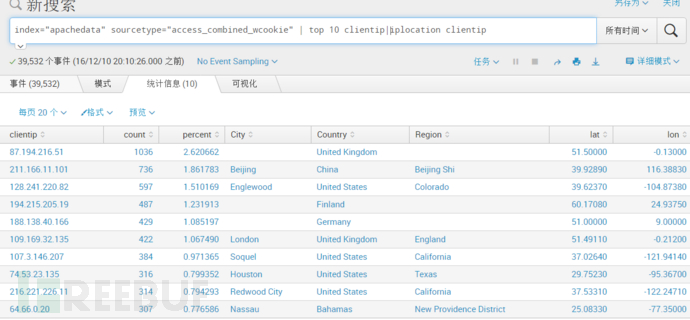
通过IP地址获取地区、国家、城市等信息
iplocation: 使用3rd-party数据库解析IP地址的位置信息
index="apachedata" sourcetype="access_combined_wcookie" | top 10 clientip|iplocation clientip解释:获取前十的IP,并且对前十IP所在地区进行解析显示
来自中国的IP有多少
where:条件查询
index="apachedata" sourcetype="access_combined_wcookie"|iplocation clientip | where Country="China"|stats count by Country|rename Country as "国家"四、IP地址分析
在世界地图上显示IP分布,使用Cluster Map可视化显示。
geostats命令:生成将在世界地图上呈现且群集化成地理数据箱的统计信息。
index="apachedata" sourcetype="access_combined_wcookie"|iplocation clientip | geostats count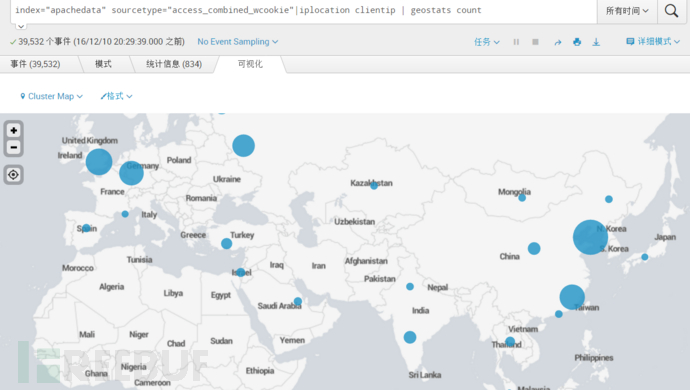
五、IP地址分析
每台服务器的GET和POST请求的对比图,并且另存为仪表板
index="apachedata" sourcetype="access_combined_wcookie"|timechart count(eval(method=="GET")) as "GET请求",count(eval(method=="POST")) as "POST请求" by host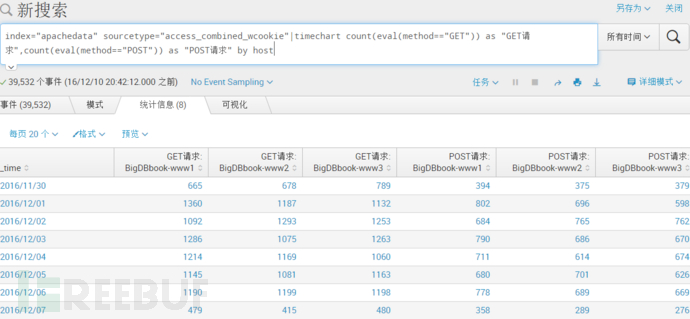
最后来看看我们的仪表盘——点击左上方仪表板——选定对应的仪表板标题,点击打开,由于没有进行编辑调整,看起来就没那么好看,我们可以编辑调整,包括调整图例。
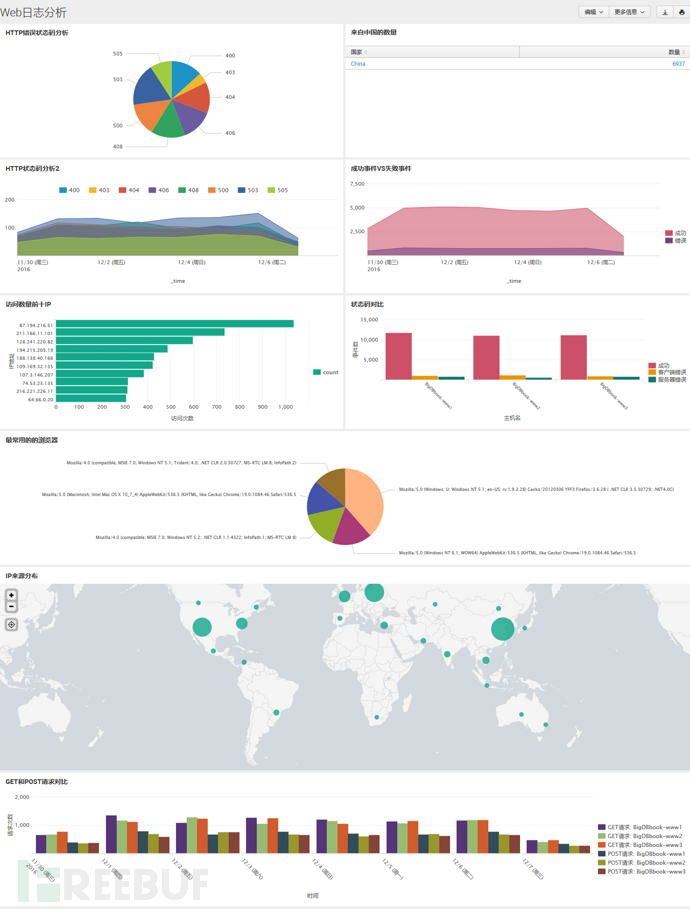
最终直观的仪表板
0×12 实战- 数据分析和可视化-2
一、数据分析-了解字段含义
Action 字段:
view:浏览
addtocart:添加到购物车
remove:删除
purchase:购买
changequantity:更改数量
购买:action=purchase
productId字段:后面跟着的是产品名称
二、最畅销的产品
最畅销的三款产品,另存为饼状图
index="apachedata" sourcetype="access_combined_wcookie" "action=purchase" |top 3 productId
产品的购买趋势图
index="apachedata" sourcetype="access_combined_wcookie" action=purchase|timechart count(eval(action="purchase")) by productId解释:查看action=purchase,即购买成功的记录,统计这个成功购买数量的记录,并且通过productId排序显示
改进,去除other、NULL的产品:
index="apachedata" sourcetype="access_combined_wcookie" action=purchase|timechart count(eval(action="purchase")) by productId usenull=false useother=false
三、页面的浏览率与购买数量
页面浏览:method=GET
购买:action=purchase
基于时间线的对比:timechart 命令
per_hour,不同于span,是一个汇总函数,用来获取比例一致的数据
index="apachedata" sourcetype="access_combined_wcookie" | timechart per_hour(eval(method=="GET")) as "浏览率" per_hour(eval(action=="purchase")) as "购买数量"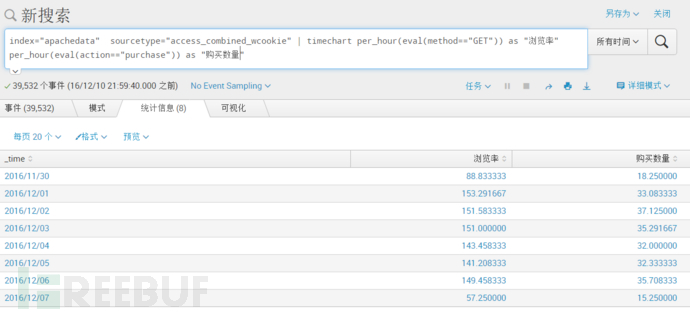
四、来源最多的网站
referer 字段表示来源地址,但站内地址应该排除
使用!=不等于排除某些,使用*通配符匹配
index="apachedata" sourcetype="access_combined_wcookie" referer !=MyGizmoStore | top referer |fields - percent| rename referer as "来源网址",count as "来源数量"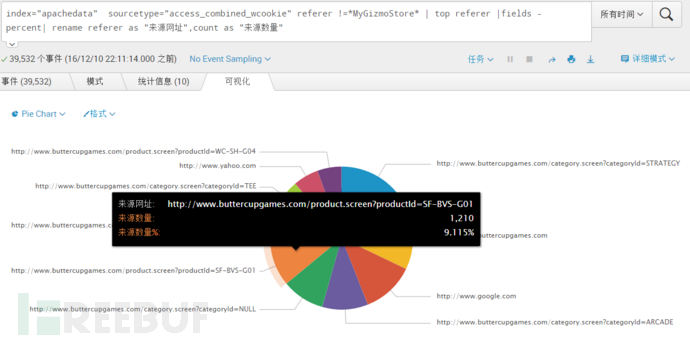
五、独立IP数
特定时间范围内的独立IP数
index="apachedata" sourcetype="access_combined_wcookie" | timechart span=2h dc(clientip) as "独立IP数" by host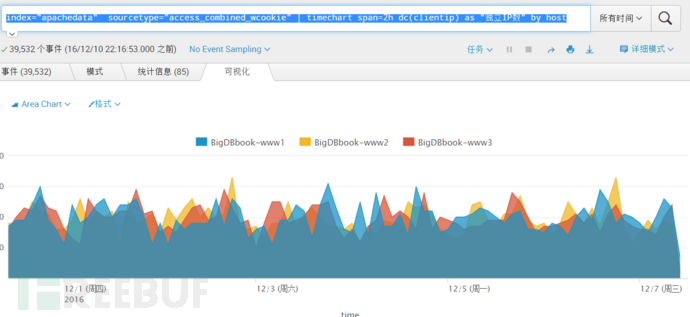
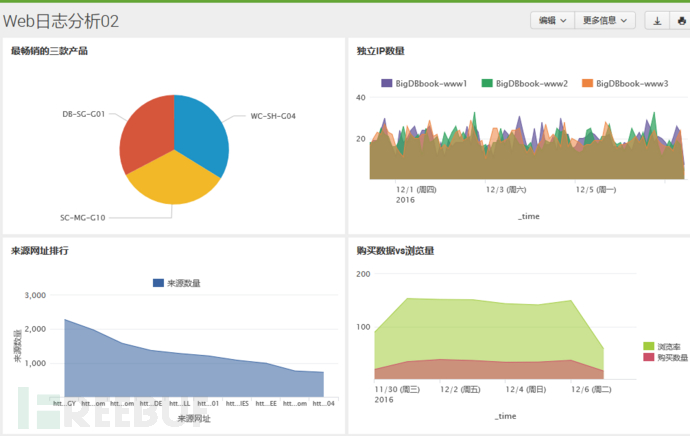
最后查看我们仪表板的布局
0×13 配置邮箱服务器
一、个人用户邮箱配置
设置用户邮箱:用户名->编辑用户->电子邮件地址
二、邮箱服务器配置
设置->服务器设置->电子邮件设置 ,在这里填写你发信邮箱的主机地址、用户名、密码
三、验证是否能正常发信
Web界面手工验证
打开Splunk→仪表板→选择某个仪表板→编辑→计划PDF交互→勾选“计划PDF”→发送邮件至“” 填写收件人地址→发送测试电子邮件
使用sendmail(SPL语言)验证邮件是否能正常发送
Index=_internal | sendemail to=“收件人邮箱地址" from=“发件人邮箱地址" server=“发件服务器" subjectsendresults=true sendpdf=true测试:
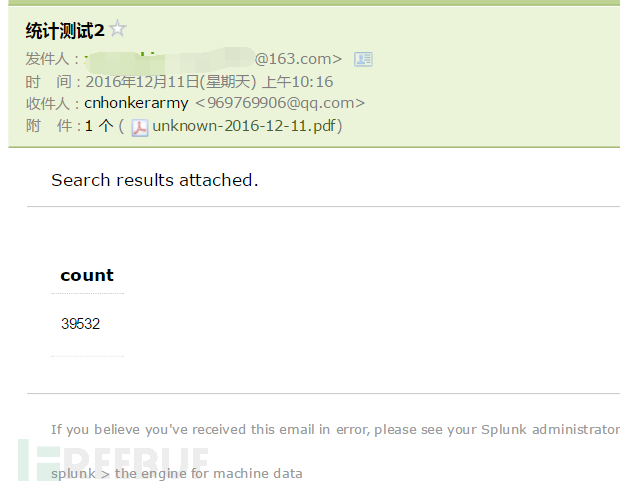
index="apachedata" sourcetype="access_combined_wcookie"|stats count|sendemail to="969769906@qq.com" from="xxxxx@163.com" server="smtp.163.com" sendresults=true sendpdf=true subject="统计测试2"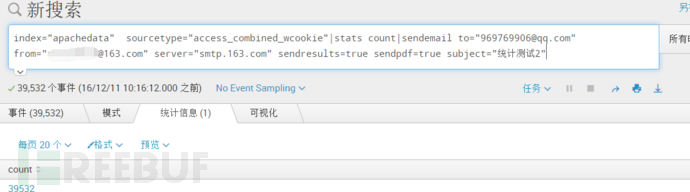
0×14 创建APP
一、在Splunk Web 中创建APP
进入Splunk Web页面→应用→管理应用。浏览更多的应用:浏览splunk APP页面获取更多应用。从文件安装应用:是指的从Splunk的官方网站下载APP以本地文件形式安装。创建应用:则是我们自行创建的应用。
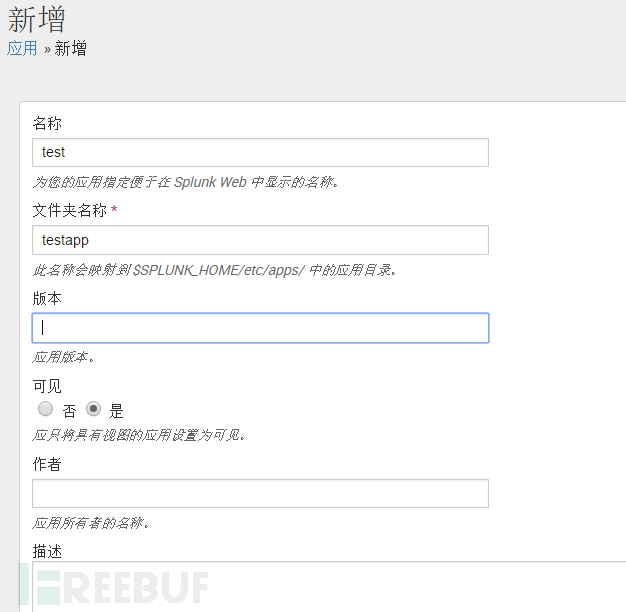
新增APP至少需要填写名称、文件夹名称,建议在创建APP的时候针对不同网络设备创建不同的APP
创建的APP在左窗口有显示

二、设置进入splunk首页视图、导航、颜色
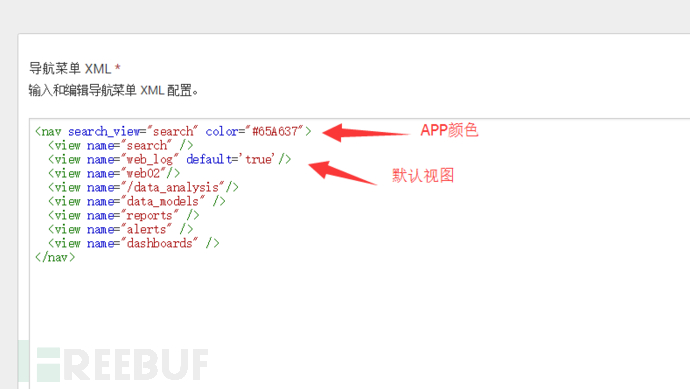
选择对应的应用→用户界面→default,编辑XML配置,例如:将之前的仪表板如:web_log(即当时保存为仪表板时的字段)加入视图。
注意:每个视图的顺序配置也决定splunk应用菜单上的顺序
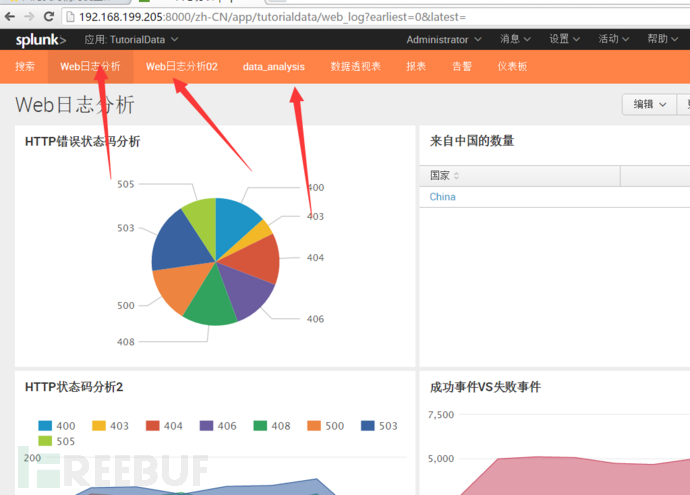
最后查看效果:
三、更新图标
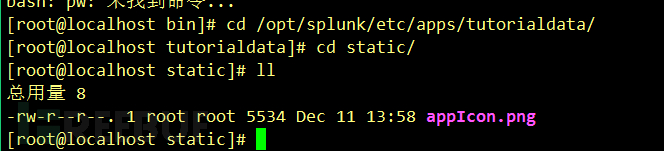
1、上传图标到相应APP的static目录中(如果没有请自行创建),如:/opt/splunk/etc/apps/tutorialdata/static
图标名称必须为:appIcon.png 36x36px
2、重启splunk生效
0×15 splunk技巧
一、忘记管理员密码怎么办
如果忘记管理员密码,可以重置。需要有服务器的访问权限。
方法
1)将$SPLUNK_HOME/etc/passwd文件重命名为passwd.bak

2)重新启动Splunk,此时登录Splunk Web之后,所使用的密码则为初始账号密码:admin changeme

二、_time时间字段的处理
格式化时间。
方法:
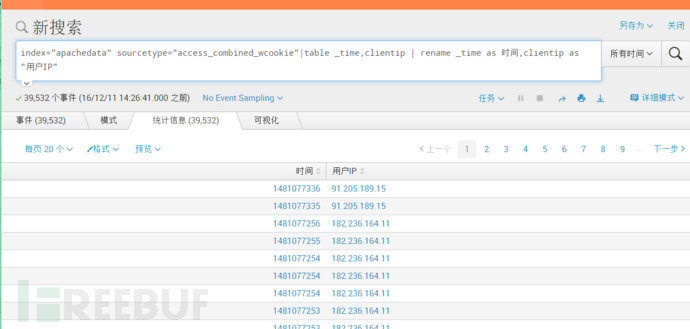
| eval my_time=_time | convert timeformat=“%Y-%m-%d %H:%M:%S” ctime(my_time) | rename my_time as “时间” index="apachedata" sourcetype="access_combined_wcookie"|table _time,clientip | rename _time as 时间,clientip as "用户IP"
这种类型的搜索,所显示的时间为时间戳,为了更好地展示给用户看,我们可对该时间进行格式化。
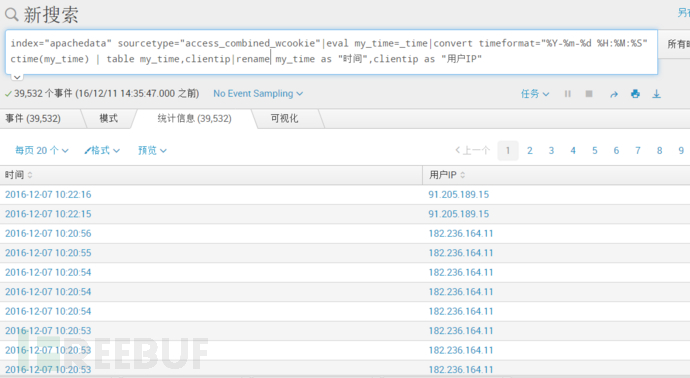
index="apachedata" sourcetype="access_combined_wcookie"|eval my_time=_time|convert timeformat="%Y-%m-%d %H:%M:%S" ctime(my_time) | table my_time,clientip|rename my_time as "时间",clientip as "用户IP"解释:将_time赋值给my_time,最后通过ctime进行格式化,格式为timeformat指定的格式。
三、是否可以删除数据
我索引的部分日志事件中包含敏感信息,或日志事件有乱码,是否可以删除这些事件?
Splunk不允许对索引后的数据进行修改。但可以使用delete 命令删除数据,删除后无法检索到这些数据,但其实这些数据并未被从磁盘上删除。
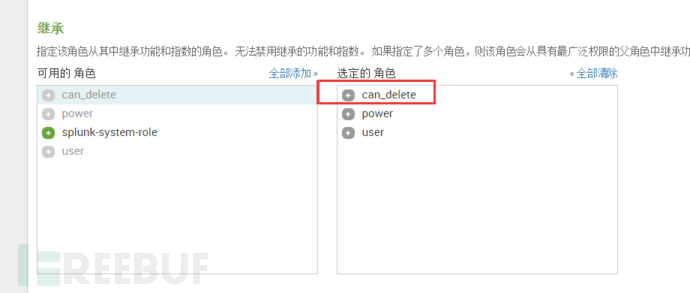
使用delete命令需要开启该角色的can_delete权限
1、 权限设置
打开→设置→访问控制→角色→角色名称:admin继承can_delete角色。
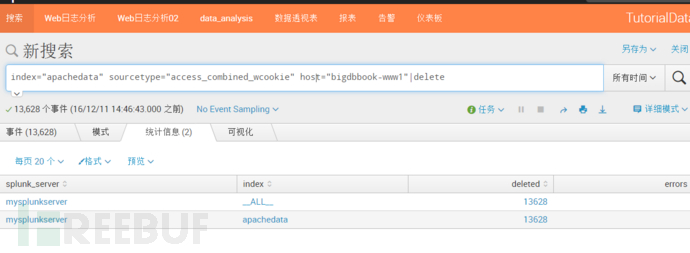
2、测试删除
index="apachedata" sourcetype="access_combined_wcookie" host="bigdbbook-www1"|delete删除bigDBbook-www1主机的日志信息,并打印出详细的删除信息
四、导入后的数据乱码了,是否可以重新再导入?
导入后的数据乱码了,是否可以重新再导入?
可以。在Splunk里,称为“重新索引(reindex)”。
方法:
1)重新索引所有数据:
splunk clean eventdata-index 索引名称
2)选择性重新索引某个文件:
splunk cmdbtprobe-d $SPLUNK_HOME/var/lib/splunk/fishbucket/splunk_private_db–file $FILE –reset
最后想说,有什么错误请指点,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号