
Hadoop及Mahout的安装
2014-03-28 16:12 Digging4 阅读(658) 评论(0) 收藏 举报本文描述了Hadoop及Mahout的安装。环境如下:
主机:win7 64位,4G内存(host为笔记本,通过无线路由上网)
虚拟机:两台,virtualbox,Linux版本为centos(机器名为bk01,bk02)
第一步:在虚拟机上安装centos
1、按照常规安装,由于实验环境对性能要求不高,每个虚拟机配置512M内存。centos在512M内存下默认不安装图形界面。
2、安装后的配置(两个虚拟机同样配置):
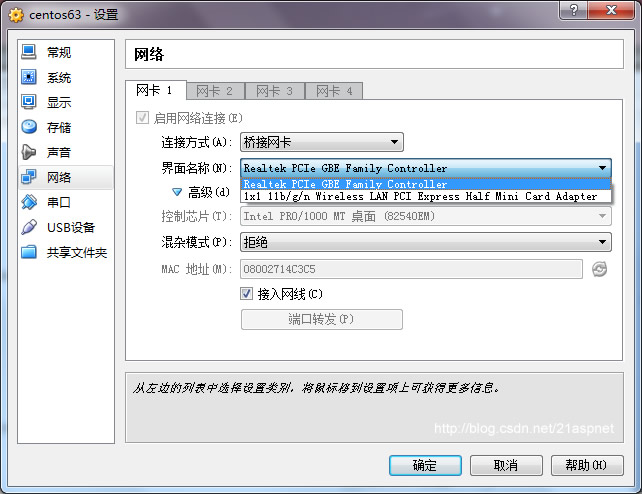
a)virtualbox 网卡设置为桥接,选择无线网卡
b)修改网络配置
vi /etc/sysconfig/network-scripts/ifcfg-eth0
按下图描述修改文件(该图非原创,当时匆忙没记下网址,在此谢谢原作者)
c)修改域名服务器
vi /etc/resolv.conf
nameserver 8.8.8.8 #google域名服务器 杭州首选DNS服务器地址,202.101.172.35
nameserver 8.8.4.4 #google域名服务器 也可以设施为当地ISP提供的DNS地址

d)修改配置
useradd grid #添加用户 grid
passward grid #为用户grid设定密码
service iptables stop #关闭防火墙
chkconfig iptables off #关闭防火墙
service sshd start #启动ssh服务
e)关闭SELINUX
修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
以上完成后,重启机器即可。
第二步:在虚拟机上安装jdk(两个虚拟机同样处理)
1、查看系统是64位/32位,对应的jdk不一样
getconf LONG_BIT 或者 getconf WORD_BIT
2、使用grid登录
[grid@localhost ~]$ su
Password:
[root@localhost grid]# wget --no-check-certificate http://download.oracle.com/otn-pub/java/jdk/7u51-b13/jdk-7u51-linux-i586.tar.gz?AuthParam=1390953709_424024baadd0a1274f4f0c42cf37cd3b
#注意:直接在oracle上得到的地址不行,要通过浏览器下载后,看到后面有AuthParam参数的下载地址才可以,这个地址最新生成的才可以,如果之前保存的地址是不行的。
tar -zxvf jdk-7u51-linux-i586.tar.gz #下载的文件解压缩
mv ./jdk1.7.0_51 /usr #移动文件夹到 /usr
第三步:配置ssh免密码
1、安装ssh客户端
[root@bk01 grid]# yum -y install openssh-clients
2、生成ssh文件(在home文件夹下生成 .ssh目录)
[grid@bk01 ~]$ ssh-keygen -t rsa
以上1-2在所有的虚拟机上执行
3、在其中一个机子上生成authorized_keys文件,并把所有机子上的id_rsa.pub中的内容复制到该文件中(含本机的id_rsa.pub)
4、把公钥文件authorized_keys复制到其他机器上
[grid@bk01 .ssh]$ scp ./authorized_keys grid@192.168.1.151:/home/grid/.ssh/authorized_keys
在bk02上查看拷入的文件,权限必须如下所示,否则要修改: chmod 644
-rw-r--r-- 1 grid grid 391 Jan 29 10:31 authorized_keys
注意,密码对本机也要设置
即把所有机器上id_rsa.pub公钥都考入到authorized_keys中,再分发到各个节点。
再从bk01上登录到bk02就不需要密码了
[grid@bk01 ~]$ ssh 192.168.1.151
第四步:安装Hadoop(只需在一台机子上安装配置,完成后整个hadoop文件夹分发到其他机子上)
1、下载hadoop
[grid@bk01 ~]$ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz
[grid@bk01 ~]$ tar -xzvf hadoop-1.2.1-bin.tar.gz
2、配置
----修改java_home---------------
[grid@bk01 ~]$ cd hadoop-1.2.1/conf
[grid@bk01 conf]$ vi hadoop-env.sh
export JAVA_HOME=/usr/jdk1.7.0_51
--------------------------------
[grid@bk01 conf]$ vi core-site.xml
修改如下
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bk01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/grid/hadoop-1.2.1/tmp</value> #指定临时目录
</property>
</configuration>
--------------------------------
[grid@bk01 conf]$ vi hdfs-site.xml
修改如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
--------------------------------
[grid@bk01 conf]$ vi mapred-site.xml
修改如下
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>bk01:9001</value>
</property
</configuration>
--------------------------------
[grid@bk01 conf]$ vi masters
指定master的主机名,修改如下
bk01
[grid@bk01 conf]$ vi slaves
指定slave的主机名,修改如下
bk02
-------------------------------
修改host文件
[grid@bk01 conf]$ su
Password:
[root@bk01 conf]# vi /etc/hosts
增加两条记录
192.168.1.150 bk01
192.168.1.151 bk02
3、配置好的Hadoop目录分发到其他机器
[grid@bk01 ~]$ scp -r ./hadoop-1.2.1 grid@192.168.1.151:/home/grid
4、其他节点要配置同样的hosts文件
[root@bk01 conf]# vi /etc/hosts
增加两条记录
192.168.1.150 bk01
192.168.1.151 bk02
5、格式化name节点(bk01)
[grid@bk01 ~]$ cd hadoop-1.2.1
[grid@bk01 hadoop-1.2.1]$ bin/hadoop namenode -format
6、启动Hadoop
$HADOOP_HOME/bin/start-all.sh
--查看是否启动-----
[grid@bk01 .ssh]$ /usr/jdk1.7.0_51/bin/jps 查看启动的进程
name节点bk01 应有如下四个jave进程
1358 NameNode
1693 Jps
1585 JobTracker
1515 SecondaryNameNode
数据节点bk02 应有如下三个java进程
10209 TaskTracker
10298 Jps
10143 DataNode
7、Hadoop安装总结
1、配置hosts文件
2、建立hadoop运行账号 linux账号
3、配置ssh免密码连接
4、现在并解压hadoop安装包
5、配置namenode,修改site文件
core-site.xml
hdfs-site.xml
mapred-site.xml
6、修改hadoop-env.sh 修改java home
7、配置master和slaves文件
8、向节点复制hadoop (每个节点的hadoop目录中的内容是一样的)
9、格式化namenode
10、启动hadoop
11、用jps检验各后台是否成功启动
第五步、安装Mahout(Mahout装到任一台机器上,可以是master,也可以是slave)
1、下载 解压
[grid@bk01 hadoop-1.2.1]$ wget http://mirrors.cnnic.cn/apache/mahout/0.9/mahout-distribution-0.9.tar.gz
[grid@bk01 hadoop-1.2.1]$ tar xzf ./mahout-distribution-0.9.tar.gz
2、配置环境变量
export HADOOP_HOME=/home/grid/hadoop-1.2.1
export HADOOP_CONF_DIR=/home/grid/hadoop-1.2.1/conf
export MAHOUT_HOME=/home/grid/hadoop-1.2.1/mahout-distribution-0.9
export MAHOUT_CONF_DIR=/home/grid/hadoop-1.2.1/mahout-distribution-0.9/conf
export PATH=$PATH:$MAHOUT_HOME/conf:$MAHOUT_HOME/bin
export JAVA_HOME=/usr/jdk1.7.0_51/
3、下载测试数据
[grid@bk01 ~]$ wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
将测试数据上传上HDFS
[grid@bk01 ~]$ hadoop-1.2.1/bin/hadoop fs -mkdir ./testdata #创建目录
[grid@bk01 ~]$ hadoop-1.2.1/bin/hadoop fs -put ./synthetic_control.data ./testdata #上传测试数据
[grid@bk01 ~]$ hadoop-1.2.1/bin/hadoop fs -ls ./testdata #查看上传的文件
[grid@bk01 ~]$ mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job #执行测试
[grid@bk01 ~]$ hadoop-1.2.1/bin/hadoop fs -ls ./output #查看输出文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号