python 抓取优财网Libor利率数据,并使用BeautifulSoup解析
需求背景:需求是用程序抓取优财网Libor 查询 伦敦银行同业拆借利率-数据中心-优财网-优财金融数据金融资讯门户官方网站-UCAI123.COM Libor数据,USD的
实现思路:没找到优财网的开放API,只能通过读取网页数据,用BeautifulSoup来解析数据,至于为啥不用pandas来解析,是因为pandas适合解析有table标签的网页,而这次抓取到的网页没用到table标签,咱们要的数据都在div标签里面,所以只能用BeautifulSoup,BeautifulSoup的安装过程就不介绍了。优财网对网站做了反爬虫处理,常规的requests.get得不到我需要的网页数据,所以需要给headers加一些参数,伪装成电脑浏览器去抓数据,具体参数设置看以下代码,其中cokkie必不可少,但cookie参数的有效期还不得而知,有可能你看到这篇文章时,cookie已经失效了,时间有限,也没去研究在程序里刷新cookie的方法。
另:由于这次抓取数据用了些伪装技巧,这篇文章发布后,优财网可能会针对这类伪装再做一些防范,到时候这种方法就失效了。
import requests from bs4 import BeautifulSoup url = "http://www.ucai123.com/datas-libor" headers1 = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,ga;q=0.5', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Cookie': 'Hm_lvt_328b28d304b056f7ecfb26c54a32d979=1676562778; t=025ac93247f76e98fe2ca476a45b6572; r=7681; JSESSIONID=86D37BB6296478E089267F3208B9F263; Hm_lvt_3fce8580f2e4a5e9b06a9fd55e6a8a67=1698218384; __utma=19472828.1133157907.1698218384.1698218384.1698218384.1; __utmc=19472828; __utmz=19472828.1698218384.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; Hm_lpvt_3fce8580f2e4a5e9b06a9fd55e6a8a67=1698218721; __utmb=19472828.4.10.1698218384', 'Host': 'www.ucai123.com', 'Referer': 'http://www.ucai123.com/datas-libor', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46' } r = requests.get(url, headers=headers1) soup = BeautifulSoup(r.text, "lxml") data_content = "每日Libor播报\n" + "货币:USD " + "\n" \ "日期:" + soup.select("#times")[0].string + "\n" \ + "隔夜期:" + soup.select("#datas2")[0].string + "\n" \ + "1周期:" + soup.select("#datas2")[1].string + "\n" \ + "2周期:" + soup.select("#datas2")[2].string + "\n" \ + "1个月:" + soup.select("#datas2")[3].string + "\n" \ + "2个月:" + soup.select("#datas2")[4].string + "\n" \ + "3个月:" + soup.select("#datas2")[5].string + "\n" \ + "4个月:" + soup.select("#datas2")[6].string + "\n" \ + "5个月:" + soup.select("#datas2")[7].string + "\n" \ + "6个月:" + soup.select("#datas2")[8].string + "\n" \ + "7个月:" + soup.select("#datas2")[9].string + "\n" \ + "8个月:" + soup.select("#datas2")[10].string + "\n" \ + "9个月:" + soup.select("#datas2")[11].string + "\n" \ + "10个月:" + soup.select("#datas2")[12].string + "\n" \ + "11个月:" + soup.select("#datas2")[13].string + "\n" \ + "12个月:" + soup.select("#datas2")[14].string print(data_content)
运行效果:
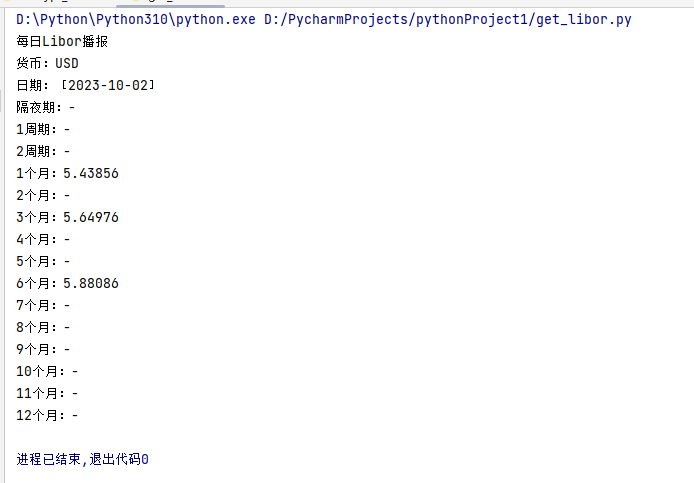
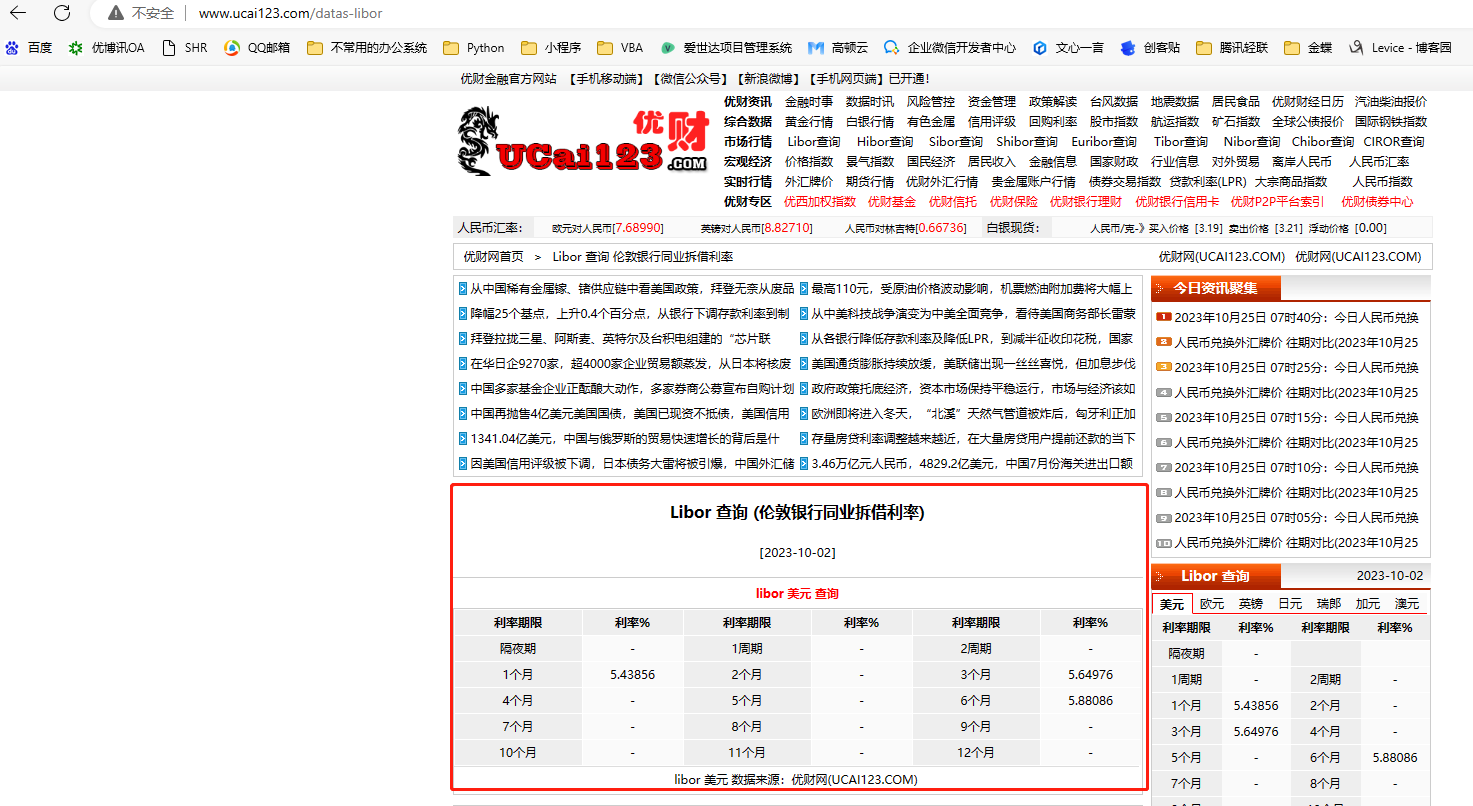
这个与网站上显示的数据是一致的:
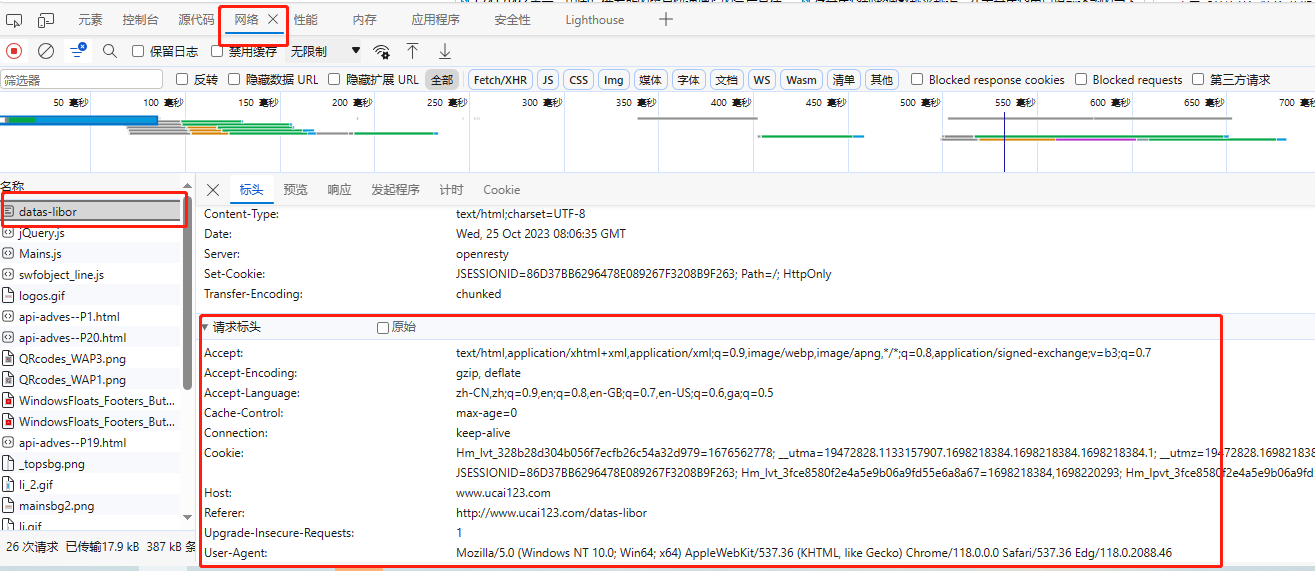
补充说一下怎么得到模仿浏览器访问的这些Headers参数,以Edge浏览器为例,先在浏览器中打开上面的网页,按F12打开开发人员工具栏,在网络标签下,刷新下页面,选择左侧的页面链接,右边就会显示请求标头,这个标头就是Headers参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号