RocketMQ
应用场景
主要作用解耦、滑峰填谷
-
异构系统的整合,这个问题比较容易理解,在原阿里SOA ESB比较火的年代,很多异构系统需要进行互联互通。
-
应用和应用之间的松耦合,这个在阿里巴巴内部很多的同步链路到异步链路里面,使用的非常多。
-
事件驱动机制和复杂事件架构模型里面的Backbone,底层的机制可以通过MQ来玩转。
-
数据复制通道,这个有很多比较典型的应用场景,比如模拟MySQL的binlog解析,将数据的变更封装为消息,进而复制到远端的另外一个数据源。
-
与流计算引擎的整合,像和Apache Storm、Spark、Flink等框架进行整合,很好的服务于大数据通道。
思路总结
-
作为中国进入Apache极少量成员之一,其肯定是Niubility的,跟其他MQ一样,用于解耦、削峰填谷
-
关键质量因素有:性能、可靠性、可排障性、顺序、重复、事务性支持
-
整体设计上使用了常见的分布式设计方案,拆分成NameSvr(服务管理,如meta信息管理、ha管理等)、Broker(存储)、Producer(消息生产者)、Comsumer(消息消费者)4个均可水平扩展的逻辑组件
-
在解决关键质量因素上,RocketMQ其核心模块Broker Strore从Mysql innodb上借鉴了许多:
-
comsumerlog顺序写+queuelog索引表提高写速度
-
comsumerlog存储上使用定长(tag hash)
-
redolog提高写能力
-
undolog解决事务问题
-
定制索引树(msgKey)
-
零拷贝
5.在读性能提速上,按官方文档当前最高效的是使用批量,批量指在fetch msgs时,采用批量缓存至本地(默认1k),这样能大大提高comsumerlog的单次转盘查数据命中率。当然,当单条消息过大时,不建议拉取那么多缓存于本地,容易引起运行内存占用过多
6.在可靠性支持上,采取了双向确认
7.在重复、顺序问题上,采取了折中方案
8.在性能上,与大数据的宠儿kafka实验室数据128kb以下消息,对比性能为15:20(w单位),略逊,主要由于为支持多topic扩展及可追踪/事务特性(如多了msgKey索引树)。从设计角度上看,合适是第一要义,15与20在w级别上,普通的业务项目来说,选择rocketmq更为理智的选择,你总不想在关键问题排障上,某个环节哑了。而在大数据对丢失排障几近无诉求的情况下,用高吞吐的kafka更为合适。
9.看17年的成就上,有很多高级的CPU级别优化事项是我未清楚的高端优化。想起褚霸的文章提到“把软件中相对成熟稳定的部分转变为硬件进行固化,比如用MOC卡承载虚拟化引擎以及网络和存储offloading,带来更高的性能和更低的成本”。Niubility
10.未来规划上,电商、金融已是阿里的2块领地,metaq,notify对其诉求已覆盖基本能力。开始向物联网、大数据靠拢。如物联网上,通过网关技术做协议Proxy。拭目以待
架构
领域模型
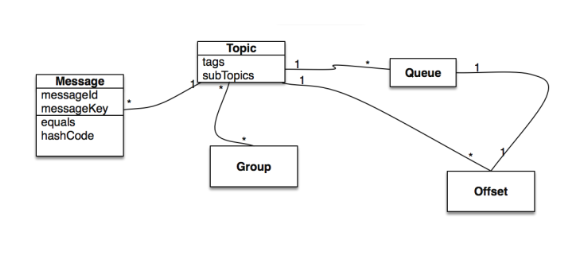
topic为逻辑概念,Queue为物理概念
tag: 标识某一类消息
msgKey:消息唯一标识,用于trace与幂等处理
逻辑架构
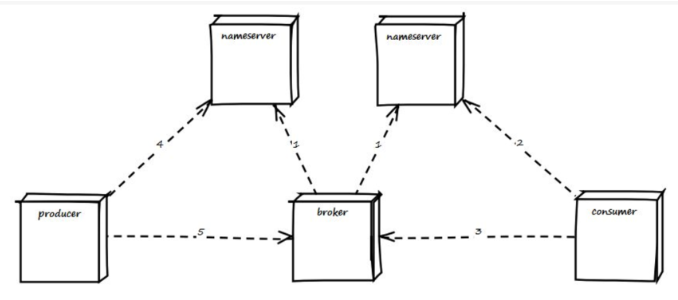
nameserver
producer
broker
consumer
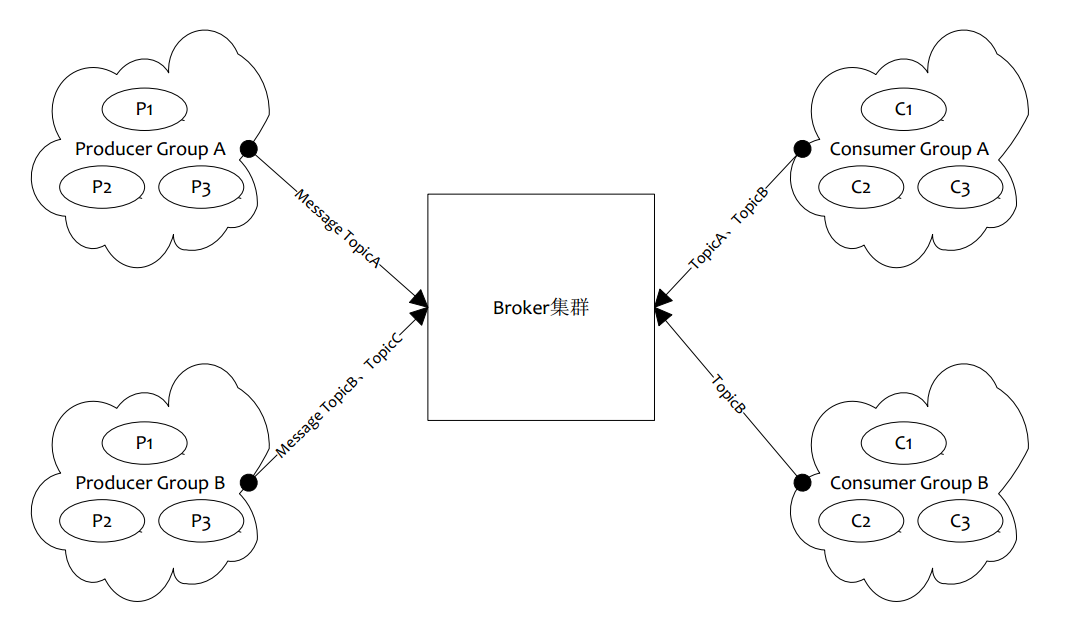
上图是一个典型的消息中间件收发消息的模型,RocketMQ也是这样的设计,简单说来,RocketMQ具有以下特点:
-
是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点。
-
Producer、Consumer、队列都可以分布式。
-
Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的队列集合。
-
能够保证严格的消息顺序
-
提供丰富的消息拉取模式
-
高效的订阅者水平扩展能力
-
实时的消息订阅机制
-
亿级消息堆积能力
-
较少的依赖
集群消费模式:
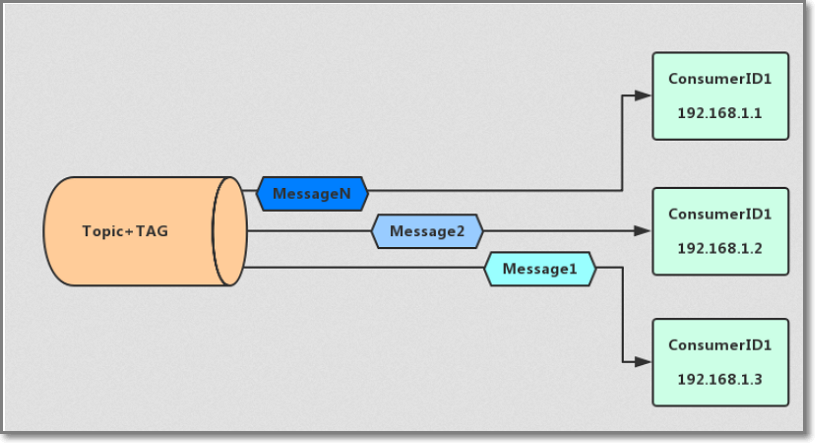
广播消费模式:
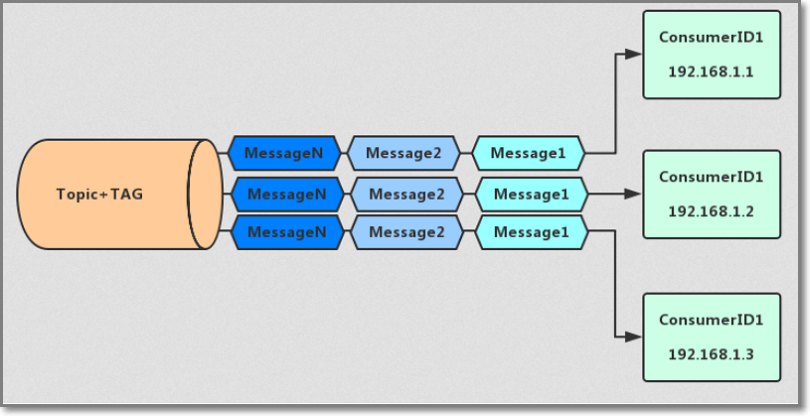
使用集群模式模拟广播:
如果业务需要使用广播模式,也可以创建多个 Consumer ID,用于订阅同一个 Topic。
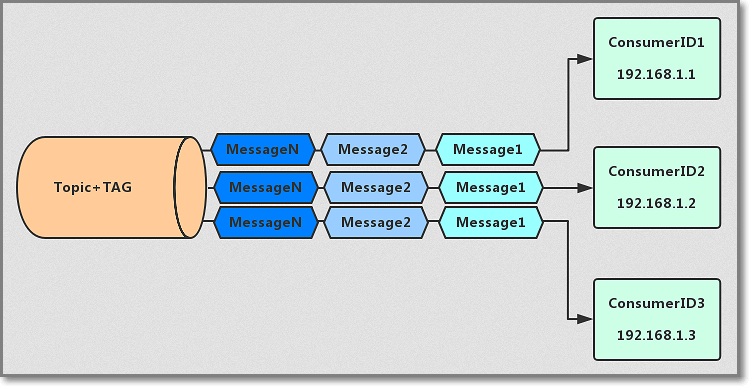
-
producer仅支持同集群提交,consumer支持跨集群消费
运行架构
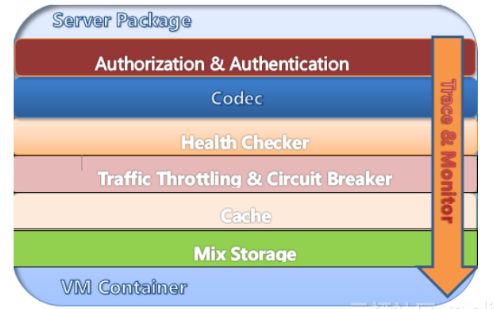
下图为RocketMQ服务端的整体架构设计。首先最上层是授权和认证部分,因为RocketMQ是基于TCP的自行研发的一套线路层协议
http://jaskey.github.io/blog/2016/12/19/rocketmq-network-protocol/),所以它需要编解码以及序列化。再接下来可这一层是健康检查,在健康检查之后是流控和熔断措施,因为再好的系统也需要流量保护,RocketMQ也是一样,为了良好的可用性,RocketMQ提供了针对于不同维度的流量控制。再往下就是存储,总体而言RocketMQ服务端对于部署运维是非常友好的,目前阿里巴巴内部也有很多系统在进行Docker容器化。
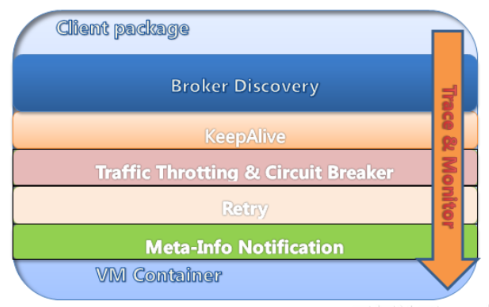
下面这幅图展示的是SDK的架构图。毋庸置疑第一步需要做的事情是服务发现,需要去找到发消息或者收消息具体的broker以及broker上的Topic,在此之外SDK还会需要做的事情就是长连接的保活。接下来与服务端相同,要有流量控制以及熔断机制,另外为了保证实现高可用性,就需要提供补偿机制,这种补偿机制表现在发送端的Retry和接收端的Redelivery,也就是重投和重发。接下来,在SDK层还存在元信息通知更新消息,比如nameserver上数据变更就需要进行通知。
部署架构
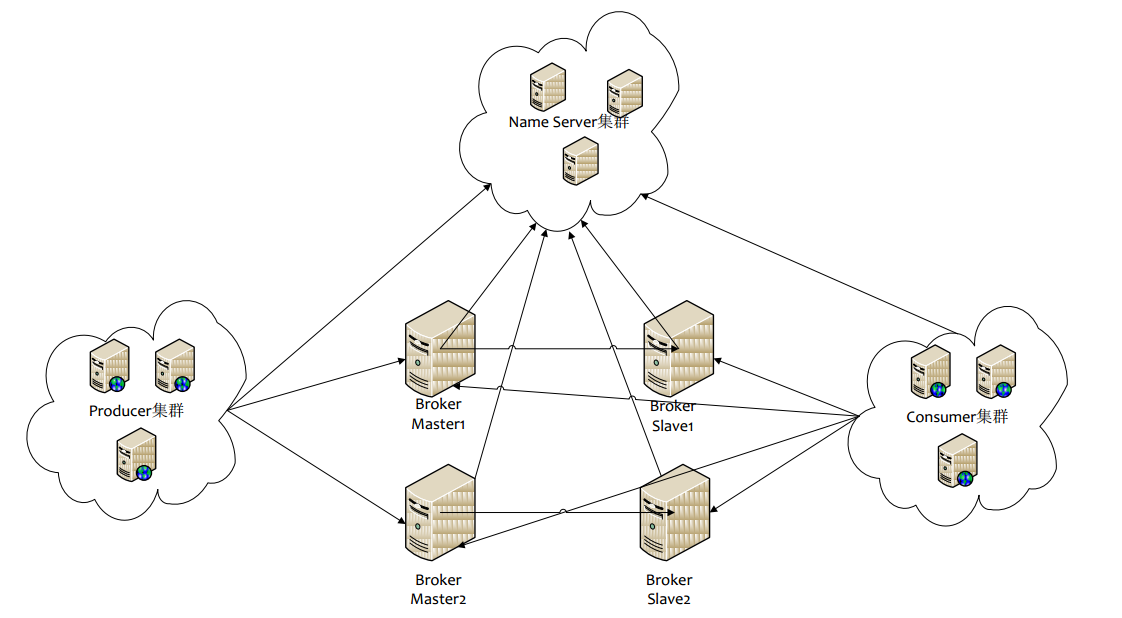
如上图所示, RocketMQ的部署结构有以下特点:
-
Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
-
Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与Name Server集群中的所有节点建立长连接,定时注册Topic信息到所有Name Server。
-
Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
-
Consumer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
关键设计
消息存储
consume queue与commit log
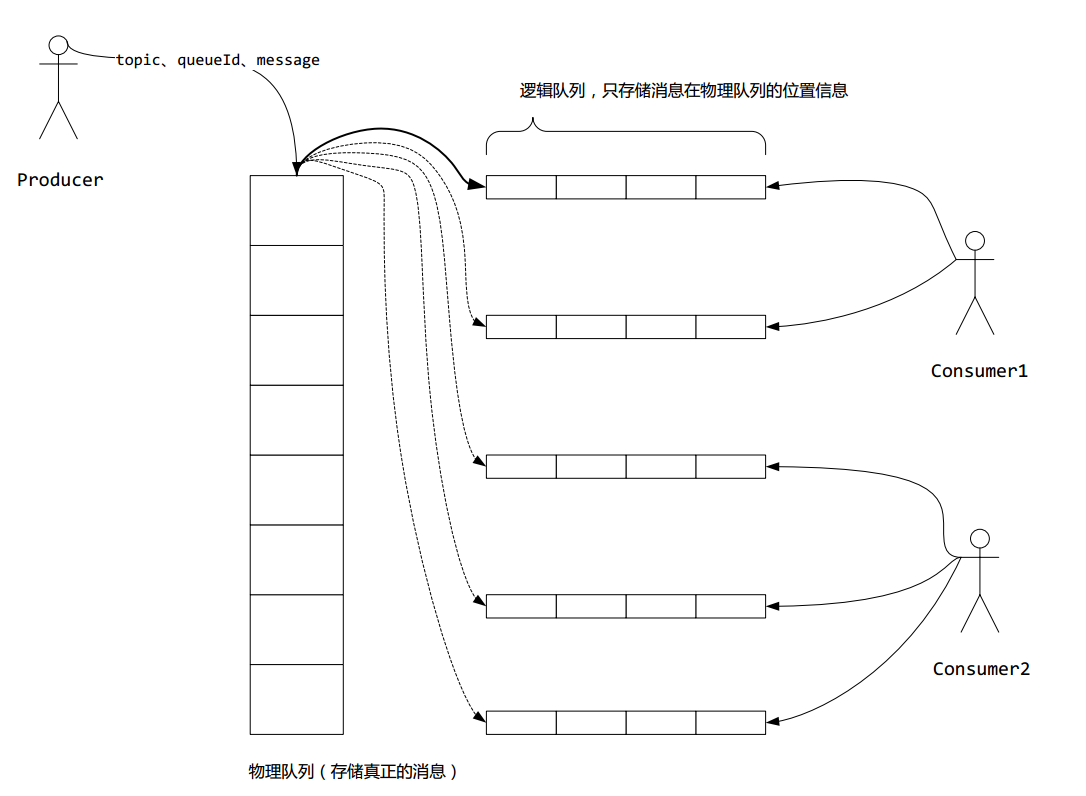
RocketMQ的消息存储是由consume queue和commit log配合完成的。
consume queue是消息的逻辑队列,相当于字典的目录,用来指定消息在物理文件commit log上的位置。
Commit Log的消息是真实的消息数据,存储单元长度不固定,文件顺序写,随机读。消息的存储结构如下表所示,按照编号顺序以及编号对应的内容依次存储。
consume queue是消息的逻辑队列,相当于字典的目录,用来指定消息在物理文件commit log上的位置。
Commit Log的消息是真实的消息数据,存储单元长度不固定,文件顺序写,随机读。消息的存储结构如下表所示,按照编号顺序以及编号对应的内容依次存储。

这种存储设计,最大的好处是写速度很快,多toipc共享顺序写commit log,又平衡了topic维度拆分的读操作。
而读性能优化方面,使用了二次查询(topic queue log -> commit log)有所折损性能,使用了零拷贝、客户端批量查(默认1k条消息)以提高转盘命中率。

以上是commit queue的主要字段,定长设计避免碎片化,定长设计上特别要说的是Tag使用了Hash code的设计,在需使用tag来get消息的场景下,可快速先过滤掉hashcode不匹配的消息(一层过滤大大减少了二次查询的数据量),再通过commit log获取到的完整tag进行精确匹配。

运维能力支持基础--其他检索方案
rocketMQ支持业务指定key(一般建议使用业务唯一ID)。
如果一个消息包含key值的话,会使用IndexFile存储消息索引,这样就很方便大家在MQ环节排障时,可以快速定位问题
文件的内容结构如图:

Producer如何发送消息
Producer轮询某topic下的所有队列的方式来实现发送方的负载均衡,如下图所示:
消息订阅
RocketMQ消息订阅有两种模式,一种是Push模式,即MQServer主动向消费端推送;另外一种是Pull模式,即消费端在需要时,主动到MQServer拉取。但在具体实现时,Push和Pull模式都是采用消费端主动拉取的方式。

消费端的Push模式是通过长轮询的模式来实现的,就如同下图:

性能
1、JSON序列化 2、IO mmap文件映射技术、PageCache、 清理文件、顺序写(单独的线程专门做刷盘的操作) 3、Batch:Group Commit、Consumer
4、系统层面的高级优化:CPU的亲和特性(线程/内存/网卡)、突破内存锁限制,无锁设计、NUMA架构Disable(如打开NUMA的交叉分配方案)、磁盘I/O调优-Deadline最后期限调度算法,避免I/O写请求饿死情况出现
可靠性
文件存储,多份备份
MQ 消息重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
影响消息可靠性的几种情况:
-
Broker正常关闭
-
Broker异常Crash
-
OS Crash
-
机器掉电,但是能立即恢复供电情况。
-
机器无法开机(可能是cpu、主板、内存等关键设备损坏)
-
磁盘设备损坏。
(1)、(2)、(3)、(4)四种情况都属于硬件资源可立即恢复情况,RocketMQ在这四种情况下能保证消息不丢,或者丢失少量数据(依赖刷盘方式是同步还是异步)。
(5)、(6)属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失。RocketMQ在这两种情况下,通过异步复制,可保证99%的消息不丢,但是仍然会有极少量的消息可能丢失。通过同步双写技术可以完全避免单点,同步双写势必会影响性能,适合对消息可靠性要求极高的场合,例如与Money相关的应用。
RocketMQ从3.0版本开始支持同步双写。
顺序消息
方案一:严格顺序消息

存在问题:1)并发量、阻塞 2)重复消息
事实上:
-
不关注乱序的应用实际大量存在
-
队列无序并不意味着消息无序
方案二:从业务层面来保证消息的顺序
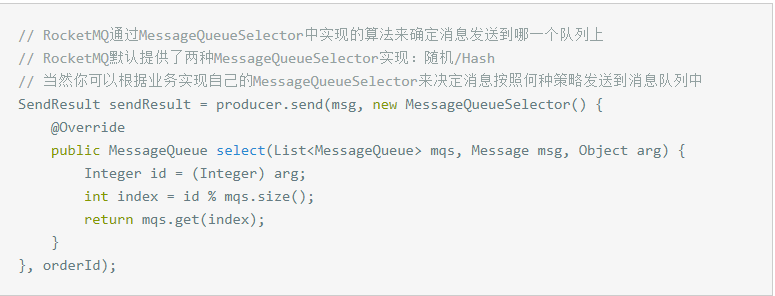
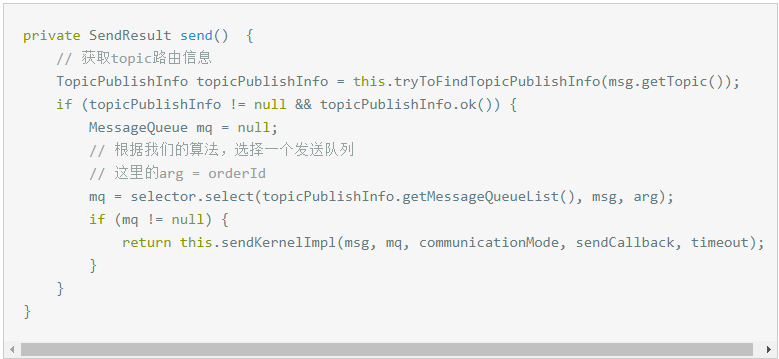
RocketMQ通过轮询所有队列的方式来确定消息被发送到哪一个队列(负载均衡策略)
消息重复
造成消息重复的根本原因是:网络不可达。只要通过网络交换数据,就无法避免这个问题。所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
可选方案:
-
消费端处理消息的业务逻辑保持幂等性
-
MQ保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现
RocketMQ考虑分布式保障服务带来对吞吐量影响,不支持消息重复处理
事务消息

1、消息发送方:RocketMQ第一阶段发送
Prepared消息时,会拿到消息的地址,第二阶段执行本地事物,第三阶段通过第一阶段拿到的地址去访问消息,并修改消息的状态。细RocketMQ会定期扫描消息集群中的事物消息,如果发现了
Prepared消息,它会向消息发送端(生产者)确认,Bob的钱到底是减了还是没减呢?如果减了是回滚还是继续发送确认消息呢?RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。2、消费方:Smith端开始消费这条消息,这个时候就会出现消费失败和消费超时两个问题
1)解决超时问题的思路就是一直重试,直到消费端消费消息成功,整个过程中有可能会出现消息重复的问题,按照前面的思路解决即可
2)消费端超时问题,但是如果消费失败怎么办?解决方法是:低概率问题,人工解决
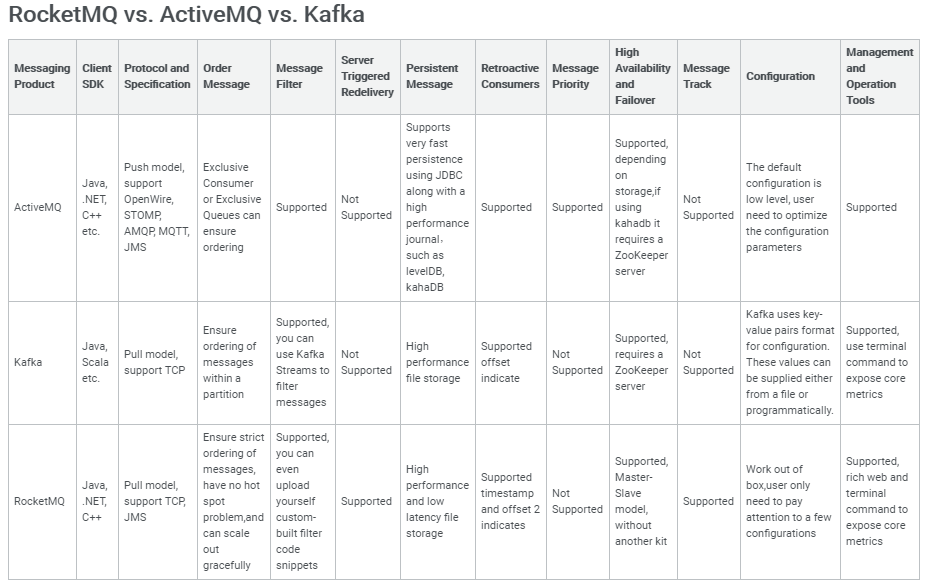
业界标杆对比
Kafka最初被设计用来做日志处理,是一个不折不扣的大数据通道,追求高吞吐,存在丢消息的可能。其背后的研发团队也围绕着Kafka进行了商业包装,目前在一些中小型公司被广泛使用,国内也有不少忠实的拥捧着。
RocketMQ天生为金融互联网领域而生,追求高可靠、高可用、高并发、低延迟,是一个阿里巴巴由内而外成功孕育的典范,除了阿里集团上千个应用外,不完全统计,国内至少有上百家单位、科研教育机构在使用。关于这几个MQ产品更详细的特性对比:
未来展望

 浙公网安备 33010602011771号
浙公网安备 33010602011771号