倒排索引
广告引擎之索引介绍 —— 倒排索引
最近两周对广告引擎索引技术进行了一些了解,主要了解了一下索引的构成方式以及构建过程,感觉这一部分还是有一些深度,加上文档可能贫乏,了解起来需要花费一定的时间,所以结合自己的理解,我想把这个过程纪录下来,算是作为一份补充的参考文档,其中可能会存在一些错漏,希望对此部分更为熟悉的同学能予以批评指正。
![]() 图一:信息检索中倒排索引
但是,在我们的广告引擎中索引却并不是这样,其实我们的索引更类似于传统的数据库索引,你可以把我们的业务场景想象为从很多的数据表中查询符合条件的纪录,为了加速这种查询,我们需要给表的各个字断建立索引。
图一:信息检索中倒排索引
但是,在我们的广告引擎中索引却并不是这样,其实我们的索引更类似于传统的数据库索引,你可以把我们的业务场景想象为从很多的数据表中查询符合条件的纪录,为了加速这种查询,我们需要给表的各个字断建立索引。
![]() 图二:字段倒排信息总体结构图
图二:字段倒排信息总体结构图
索引设计目的
索引设计的目的是为了方便(加速)检索。在一般的检索系统一次检索由以下两步组成:- 根据关键词(token)检索包含token的文档Id
- 根据文档ID检索到文档内容
在我们的广告引擎中,第1步主要用到了倒排索引(Inverted Index),第二步主要用到了正排索引(在我们的系统这部分叫做Profile)。本文主要对广告引擎中的倒排索引进行介绍,正排索引的介绍将留到下一篇文章。
倒排索引结构
在广告引擎中的倒排索引并不是一般信息检索意义上的倒排索引,这也是让我一开始的时候觉得难以理解的地方。首先介绍下传统信息检索的倒排索引,传统的倒排索引主要是为了服务于文档检索,其目的是为了从存储的众多的文档中检索与检索词相关的文档。你可以将传统的检索类比为一次SQL like查询,对应的数据表documents包含两个字段<doc_id, document>, 一次检索相当于执行SQL语句“SELECT doc_id, document FROM documents where document LIKE ‘%<token>%’”。为了加速检索过程,传统的信息检索会形成一个倒排索引,其目的是为了能快速的检索到包含某个词(Token)或者词组(Term)的文档及在文档中的位置,你可以将这种结构想象为一个Key为字符串,Value为链表的HashMap(记得某位同学说过倒排太麻烦了,小公司搞个HashMap就解决了,笑)。图一为常见的信息检索中的倒排索引。 图一:信息检索中倒排索引
图一:信息检索中倒排索引广告引擎索引结构有两部分组成,索引元数据信息(Index Meta data)以及索引字段(Index Field)信息构成。
索引元数据信息
索引元数据信息包含索引配置信息(Index Info)以及索引资源信息(Index Resources)构成。索引配置信息
索引配置信息主要是对所有所有索引字段的描述信息,这是根据事先准备的xml配置文档生成,有三级,分别是SIndexInfo、SIndexFiledInfo、SpayLoadFieldInfo,他们的定义见下面的代码中的三个结构体。从代码中可见,SIndexInfo描述了索引的总数目,提供了到每个索引字段的指针;SIndexFieldInfo描述了索引的字段的信息,包括字段名称,来源表名,负载信息。SPayloadFieldInfo描述了字段负载信息,这些负载主要包含了一些额外的信息,比如Bidword字段的Payload信息包含出价(BidPrice),折扣(Discount),最后价格(FinalPrice)等等。/**
** @brief 倒排配置信息全集
*/
struct SIndexInfo {
SIndexFieldInfo *_pFieldInfos[MAX_INDEX_FIELD_NUM]; // 字段信息数组
int32_t _nFieldNum; // 字段个数
int32_t _nHasClassicField;
};
/**
** @brief 倒排字段配置信息
*/
struct SIndexFieldInfo {
char _szFieldName[MAX_FIELD_NAME_LEN]; // 字段名
char _szCompress[MAX_FIELD_NAME_LEN]; // 压缩方法名
INDEX_TYPE _eIndexType; // 倒排索引类型
uint32_t _nMaxDocCount; // 倒排最大长度,0为不限制
int32_t _nIndexFieldIdx;
FIELD_SPREAD_TYPE _nSpreadType; //平铺类型
char _szSourceTableName[MAX_TABLE_NAME_LEN]; // 来源表名
struct { //平铺来源字段信息
int32_t _nSourceTableIdx;
int32_t _nSourcePackageIdx;
int32_t _nSourceFieldIdx;
};
SPayloadFieldInfo *_pPayloadFieldInfos[MAX_PAYLOAD_FIELD_NUM];
int32_t _nPayloadFieldNum;
};
/**
** @brief payload字段配置信息
*/
struct SPayloadFieldInfo {
char _szFieldName[MAX_FIELD_NAME_LEN];
FIELD_STORE_TYPE _eStoreType;
int32_t _nFieldBitCount;
int32_t _nFieldIdx;
int32_t _nIndexFieldIdx;
bool _bKeyField;
};索引资源信息
索引资源信息描述了索引文件信息 ,在build索引文件的时候,我们会将索引结构(内存)以Mmap的方式同步到文件中,在索引装载的时候,我们又会将文件以Mmap的方式映射到内存中。索引的资源信息定义如下文的代码所示。从代码可以看出,索引资源信息分为两级,第一级的SIndexResource提供了到第二级的SIndexFieldResource的指针。SIndexFieldResource描述了具体的字段索引资源信息,包含一级索引文件句柄(指向一个HashMap的mmap映射),二级索引文件句柄(这个地方根据索引类型有不同的实现,有可能是B+树,BitMap或者一般的链表)。/**
** @brief index资源信息
*/
struct SIndexResource {
SIndexFieldResource *_pFieldResource[MAX_INDEX_FIELD_NUM];
int32_t _count;
};
/**
** @brief index field资源信息
*/
struct SIndexFieldResource {
util::CMMapMempoolInterface *_pIdxFile; // 一级索引文件句柄
util::CMMapMempoolInterface *_pInvertListFile; // 二级索引文件句柄
util::CMMapMempoolInterface
*_pHashFilePtr; // payload string字段的去重表(hash表部分)
util::CMMapMempoolInterface
*_pDataFilePtr; // payload string字段的去重表(data部分)
SIndexFieldInfo *_pFieldInfo; //字段倒排配置信息
SGlobalInfo *_pGlobalConf; //全局配置信息
SIndexFieldResource() {
_pIdxFile = NULL;
_pInvertListFile = NULL;
_pHashFilePtr = NULL;
_pDataFilePtr = NULL;
_pFieldInfo = NULL;
_pGlobalConf = NULL;
}
~SIndexFieldResource() {}
};索引字段信息
索引字段(IndexFiled)信息描述了索引的具体构成,包含一级索引(token的HashMap),二级索引(doc id的集合、具体表现形式因索引类型不同而不同)。这部分主要包含四个结构,分别是SIdx1Unit(一级索引)、SIdx2Unit(二级索引)、IndexField(索引字段)以及CIndexTerm,具体定义见下面的代码。// 一级倒排结构
struct SIdx1Unit {
uint64_t sign; // token 签名
union {
struct {
uint64_t num:26; // doc数量, 最多1.3亿
int64_t beginOffset:38; // 二级倒排起始偏移,最多64G
};
uint64_t numOffset;
};
};
// 二级倒排基本结构
typedef struct SIdx2Unit {
uint32_t docId; // doc-id
} SIdx2Unit;
// 二级倒排结构,带occ
typedef struct SIdx2UnitOcc: public SIdx2Unit {
uint16_t occ; // token在docid中的位置occ
} SIdx2UnitOcc;
struct SIndexFieldMergeInfo {
uint64_t nDocCount;
CIndexField *pIndexField;
};
// 字段倒排管理器,内部,基类
class CIndexField {
protected:
// deletemap 管理器
CDeleteMap *_pDelMap;
// 一级索引
util::CHashTable<SIdx1Unit> *_pIdx;
util::CMMapMempoolInterface *_pIdxFile;
// 二级索引
util::CMMapMempoolInterface *_pInvertListFile;
};
class CIndexTerm {
public:
// 获取倒排长度
virtual uint32_t getDocNum() = 0;
// 获取倒排链,做deletemap过滤
virtual int32_t getDocList(uint32_t *pDocList, char **pPayloadList) = 0;
// 获取倒排链地址
virtual const void *getDocList() = 0;
// 根据当前传入的docid取出第一个等于或大于的docid,用于外层归并
virtual uint32_t seek(uint32_t nDocId, char *&pPayload) { return INVALID_DOCID; }
// 设置deletemap管理器
void setDeleteMap(CDeleteMap *pDelMap);
protected:
CDeleteMap *_pDelMap;
uint32_t _nDocNum;
const char *_pInvertList;
int32_t _nDocUnitLength;
uint32_t _pos;
};
- 上文说一级索引实际上一个关于Token/Term的HashMap(实际用使用的是HashTable),SIdx1Unit就是这个HashMap的Key,它包含Token/Term的hash值,以及倒排链中的文档个数(num)以及二级索引起始地址(beginOffset),注意这里beginOffset指向的是内存偏移位置量,我们自己实现内存的分配器MemPool。
- SIdx2Unit和SIdx2UnitOcc用于描述倒排链中的单元,包含文档Id和Token/Term位置信息。
- CIndexFiled描述了字段索引的信息,包含删除映射表(CDeleteMap),用于维护被删除的文档id,一级索引映射表(_pIdx,一个key为token的hash表)以及_pIdxFile和_pInvertListFile两个mmap文件句柄。
- CIndexTerm描述相应的Token的倒排链,在CIndexFiled包含一个getTermReader用于获取指定Token的CIndexTerm倒排链。该结构包含删除映射表(_pDelMap)、token/term对应文档数量、倒排表(可能问线性表或者树),单位文档字节长度,当前指针位置。
总体结构图
图二为字段信息所有的结构的总体结构图。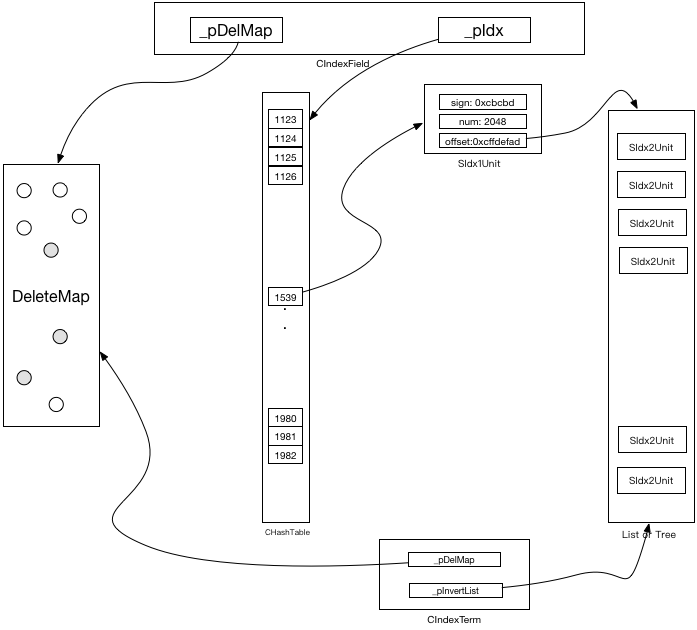 图二:字段倒排信息总体结构图
图二:字段倒排信息总体结构图一次检索过程
从图二可以看出,只要找到要检索字段所对应的CIndexField结构,检索就会变得非常简单。前文提到CIndexInfo维护了到所有的CIndexField的指针,因此只需要遍历一遍就可以轻松获取目标CIndexFiled结构。比如我们检索title字段为iphone的所有文档,我们先要获取title字段的CIndexFiled结构,然后根据iphone的hash值获取一级索引(_pIdx)对应的结构SIdxUnit1 su1,再根据su1的offset值获取到倒排链,倒排链中包含了所有符合条件的文档及相关信息。索引类型
前文提到,我们广告引擎系统的索引和传统数据库系统非常类似,因此对应传统数据库索引类型,我们广告引擎中也存在三种类型的索引,分别是:一般索引、Bitmap索引、B+树索引,他们适用的场景也和传统数据库系统一般无二。一般索引
在这种索引中,二级倒排链按关键字(一般为docId)顺序组成顺序表(可能是一块连续的存储也有可能是链式结构,不过一般情况下应该为顺序表)。这种索引适用于倒排表的较小,比如可以放进一页内存的情况下,这种情况下使用这种连续存储的顺序表的一般索引应该是非常理想的,因为这个时候我们可以对单个关键字方便的进行二分查找,并且查询一段范围(range)的关键字只要做两次二分查找就可以了,因此查找性能非常优秀。同时,在采用连续存储的情况下,这种索引避免了其他指针开销,也很节省内存空间。但是,当倒排链非常大的情况下,这种索引就不使用,这个时候查找需要在很大范围内进行,内存页cache命中变低以及寻址带来的开销会导致查找性能变低。Bitmap索引
在字段取值范围比较固定的时候,比较适用采用Bitmap(位图)索引。比如Sex字段只有Man和Women两种,我们可以给每个关键词建立一个位图数组,用指定位置的一个bit位表示对应docId是否在相应的关键字倒排链中。采用Bitmap索引可以非常有效的节省存储空间,同时由于检索只要进行bit运算,因此效率也会非常高,但是bitmap不适合取值范围较大且较为均匀的字段索引(因为bitmap会为每个关键字建立一个完整的bitmap数组,取值范围大会使得空间消耗巨大),同时bitmap也不适合更新平凡的字段索引(因为采用bitmap索引,同一时间对于一个bitmap数组的写入是互斥的)。B+树索引
当字段取值较为分散,且二级倒排链规模较大的时候我们一般采用B+树索引。B+树有几个特点,首先它是平衡的(通过结点的装载度保证),其次B+树的内部结点(叶子结点之外的结点)不存储数据,使得内部结点可以最大限度的存储更多的key,从而是树有更多的分支,从而使得树更加的扁平(高度一般不超过10),最后B+树的叶子结点形成一个构成一个链表,使得便利B+树变得很容易(范围检索更容易),对B+树感兴趣的可以参见B+Tree。在广告引擎索引设计中,我们保证每个B+树内部结点为占用空间为一页以内,这样每一次我们都可以在一页内进行二分关键字检索,同时树高度很低使得我们需要遍历的结点数目少。B+树使得内存查找局部化请参考文章。索引构建过程
在我们的广告引擎中,索引(全量)构建分为三个阶段,分别是数据准备阶段、小索引建立阶段、索引合并阶段。数据准备
在此阶段,主要是将数据库中的表数据dump出来,同时完成相关的数据的拼接组装,比如广告数据可能存在多张表中,需要将这些表按关键字拼接起来形成一张大表。这个阶段会产生几个描述几个xml文件,分别代表几种业务类型的数据,数据格式见下面。<doc>
adgroupId=100083699
catId=11,110207
defPrice=30
expire=2114380800
goodsPrice=120.00
goodsId=8248681432
campaignId=3481560
custId=1103154803
price=0
modTime=1334573076
catStatus=1
nonsearchMaxPrice=0
propertyId=21511,21943,120173,21940,32999,65235,65262,65266,21517,65256,65268,21385,21456
adgExtension=ordinaryPostFee:1200;isCommend:1;transitFee:10.00;vipDiscountRate:goldCard~100$platinaCard~100$diamondCard~100;location:北京;isNew:1;isPostFree:0;isSupportVip:0;spuId:44086;skuPrice:
adgTitle=全新库存希捷硬盘120G台式机IDE接口1年包换 元送3件礼品
adgTags=0
sell=0
sell1=0
sell7=0
score=0
adgroupStatus=1
doPrice=30
rankScore=0
postage=10.00
location=北京
locationId=19
catIdIdx=11 110207
catPropIds=110207
keywords=价格便宜11907686613,0,4,319163397一年质保11907686617,0,4,252054788硬盘11907686623,0,4,1645298193120G11907686625,0,4,1594966545全新 库存11907686620,0,4,1611743761台式机并口硬盘11907686615,0,4,1074869777希捷11907686628,0,4,1662074897
templateStatus=0
</doc>
<doc>
adgroupId=110083699
catId=11,110207
defPrice=30
expire=2114380800
goodsPrice=120.00
goodsId=8248681432
campaignId=3481560
custId=1103154803
price=0
modTime=1334573076
catStatus=1
nonsearchMaxPrice=0
propertyId=21511,21943,120173,21940,32999,65235,65262,65266,21517,65256,65268,21385,21456
adgExtension=ordinaryPostFee:1200;isCommend:1;transitFee:10.00;vipDiscountRate:goldCard~100$platinaCard~100$diamondCard~100;location:北京;isNew:1;isPostFree:0;isSupportVip:0;spuId:44086;skuPrice:
adgTitle=全新库存希捷硬盘120G台式机IDE接口1年包换 元送3件礼品
adgTags=0
sell=0
sell1=0
sell7=0
score=0
adgroupStatus=1
doPrice=30
rankScore=0
postage=10.00
location=北京
locationId=19
catIdIdx=11 110207
catPropIds=110207
keywords=价格便宜11907686613,0,4,319163397一年质保11907686617,0,4,252054788硬盘11907686623,0,4,1645298193120G11907686625,0,4,1594966545全新 库存11907686620,0,4,1611743761台式机并口硬盘11907686615,0,4,1074869777希捷11907686628,0,4,1662074897
templateStatus=0
</doc>
小索引建立
第一阶段产生的数据文件,会被切分成许多小文件(以doc为单元,保证每个doc的完整性)。这些小文件会被很多hadoop实例加载并build成许多的小索引,小索引是构建在内存中,并通过mmap文件映射的方式写入到磁盘文件中。在build开始程序会读入两份配置文件,配置文件1指定了建立索引的表名,对应文件存储位置,文件数量等信息;配置文件2指定了建立索引的字段名称,字段存储类型等信息。build文件会依次处理第一阶段产生数据文件中的doc,将其转换成kv结构,并插入到倒排结构中,具体过程可以阅读下面一段核心代码。//倒排
if (_pIndexInfo) {
SIndexFieldInfo *pIndexFieldInfo = NULL;
SPayloadFieldInfo *pPayloadFieldInfo = NULL;
for (nIndexFieldIdx = 0; nIndexFieldIdx < _pIndexInfo->_nFieldNum;
++nIndexFieldIdx) {
pIndexFieldInfo = _pIndexInfo->_pFieldInfos[nIndexFieldIdx];
for (nPayloadFieldIdx = 0;
nPayloadFieldIdx < pIndexFieldInfo->_nPayloadFieldNum;
++nPayloadFieldIdx) {
pPayloadFieldInfo =
pIndexFieldInfo->_pPayloadFieldInfos[nPayloadFieldIdx];
it = record.find(string(pPayloadFieldInfo->_szFieldName));
if (it == record.end()) {
LOG_ERROR("Field %s is required.", pPayloadFieldInfo->_szFieldName);
return -1;
}
_pFields[nFieldPtr].szName = pPayloadFieldInfo->_szFieldName;
_pFields[nFieldPtr].szValues = getIndexFieldValue(it->second.c_str(),
&_pFields[nFieldPtr].nValueCount,
pPool);
if (!_pFields[nFieldPtr].szValues) {
LOG_ERROR("getIndexFieldValue() failed.");
return -1;
}
++nFieldPtr;
}
it = record.find(string(pIndexFieldInfo->_szFieldName));
if (it == record.end()) {
LOG_ERROR("Field %s is required.", pIndexFieldInfo->_szFieldName);
return -1;
}
_pFields[nFieldPtr].szName = pIndexFieldInfo->_szFieldName;
_pFields[nFieldPtr].szValues = getIndexFieldValue(it->second.c_str(),
&_pFields[nFieldPtr].nValueCount,
pPool);
if (!_pFields[nFieldPtr].szValues) {
LOG_ERROR("getIndexFieldValue() failed.");
return -1;
}
++nFieldPtr;
}
}
//判断总数是否相符
if (nFieldPtr != _nTableFieldNum + _nIndexFieldNum) {
LOG_ERROR("%d fields parsed, but %d fields required.",
nFieldPtr,
_nTableFieldNum + _nIndexFieldNum);
return -1;
}
//去重
qsort(_pFields, nFieldPtr, sizeof(update::SField), fieldCmp);
for (int i = 1; i < nFieldPtr;) {
if (strcmp(_pFields[i].szName, _pFields[i - 1].szName) == 0) { //相同字段
for (int j = i; j < nFieldPtr - 1; ++j) {
memcpy(&_pFields[j], &_pFields[j + 1], sizeof(update::SField));
}
nFieldPtr--;
} else {
++i;
}
}
//call indexupdate
ret = _indexUpdate.add(_pTableInfo->_szTableName, _pFields, nFieldPtr, pPool);
if (ret != 0) {
LOG_ERROR("IndexUpdate::add() failed.");
return -1;
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号