
为什么需要设计数据库
这里我们思考两个问题:
修建茅屋需要设计吗?修建大厦需要设计吗?
结论是:当数据库比较复杂(如数据量大,表较多,业务关系复杂)时,我们需要先设计数据库;
因为,良好的数据库设计能够:
q 节省数据的存储空间
q 能够保证数据的完整性
q 方便进行数据库应用系统的开发
糟糕的数据库设计:
q 数据冗余、存储空间浪费
q 内存空间浪费
q 数据更新和插入的异常
软件项目开发周期
我们再来看看软件项目的开发周期:
• 需求分析阶段:分析客户的业务和数据处理需求;
• 概要设计阶段:设计数据库的E-R模型图,确认需求信息的正确和完整;
• 详细设计阶段:将E-R图转换为多张表,进行逻辑设计,并应用数据库设计的三大范式进行审核;
• 代码编写阶段:选择具体数据库进行物理实现,并编写代码实现前端应用;
• 软件测试阶段:……
• 安装部署:……
设计数据库
• 在需求分析阶段,设计数据库的一般步骤为:
– 收集信息
– 标识对象
– 标识每个对象的属性
– 标识对象之间的关系
• 在概要设计阶段和详细设计阶段,设计数据库的步骤为:
– 绘制E-R图
– 将E-R图转换为表格
– 应用三大范式规范化表格
下面我们以一个BBS简易论坛的数据库设计为例来看看设计数据库的步骤:
• 收集信息:
与该系统有关人员进行交流、坐谈,充分理解数据库需要完成的任务
BBS论坛的基本功能:
l 用户注册和登录,后台数据库需要存放用户的注册信息和在线状态信息;
l 用户发贴,后台数据库需要存放贴子相关信息,如贴子内容、标题等;
l 论坛版块管理:后台数据库需要存放各个版块信息,如版主、版块名称、贴子数等;
• 标识对象(实体-Entity)
标识数据库要管理的关键对象或实体
实体一般是名词:
l 用户:论坛普通用户、各版块的版主。
l 用户发的主贴
l 用户发的跟贴(回贴)
l 版块:论坛的各个版块信息
• 标识每个实体的属性(Attribute)

• 标识对象之间的关系(Relationship)
l 跟贴和主贴有主从关系:我们需要在跟贴对象中表明它是谁的跟贴;
l 版块和用户有关系:从用户对象中可以根据版块对象查出对应的版主用户的情况;
l 主贴和版块有主从关系:需要表明发贴是属于哪个版块的;
l 跟贴和版块有主从关系:需要表明跟贴是属于哪个版块的;
• 绘制E-R图
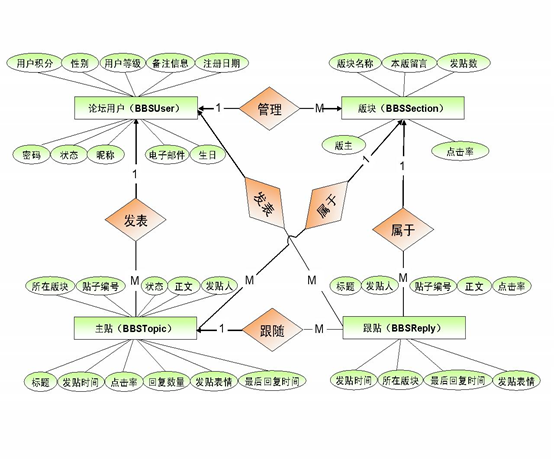
• 将E-R图转化为表格
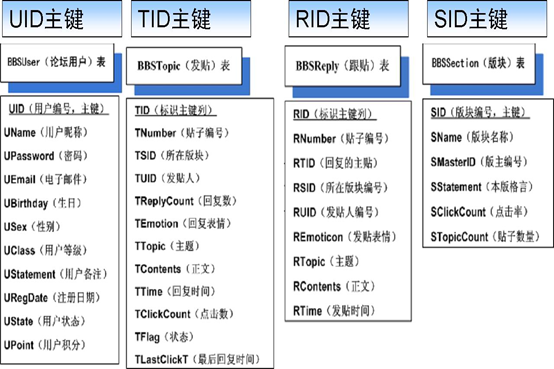
• 将各实体转换为对应的表,将各属性转换为各表对应的列
• 标识每个表的主键列,需要注意的是:没有主键的表添加ID编号列,它没有实际含义,用于做主键或外键,例如用户表中的“UID”列,版块表中添加“SID”列,发贴表和跟贴表中的“TID”列
• 在表之间建立主外键,体现实体之间的映射关系
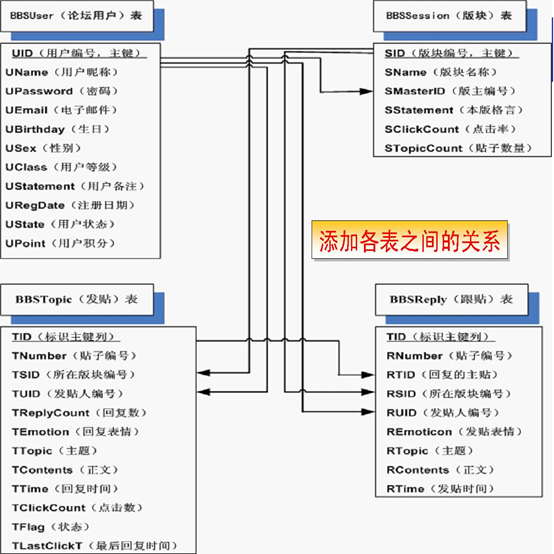
这里我们绘制ER图可以使用微软的Word或VISIO以及Sybase公司的PowerDesigner,它主要用于和客户沟通交流意见,并反复修改,直到客户确认。客户确认后,再将E-R图转换为表。上面我们已经做好了这个工作。那接下来就是最后一步:应用三大范式对设计的多张表进行审核并规范化表的结构。
数据规范化
• 仅有好的RDBMS并不足以避免数据冗余,必须在数据库的设计中创建好的表结构。表设计后,很可能结构不合理,出现数据重复保存,简称数据的冗余,这对数据的增删改查带来很多后患,所以我们需要审核是否合理,就像施工图设计后,还需要其他机构进行审核图纸是否设计合理一样。
• 如何审核呢?需要一些有关数据库设计的理论指导规则,这些规则业界简称数据库的范式。Dr E.F.codd 最初定义了规范化的三个级别,范式是具有最小冗余的表结构。这些范式是:
– 第一范式(1st NF -First Normal Fromate)
– 第二范式(2nd NF-Second Normal Fromate)
– 第三范式(3rd NF- Third Normal Fromate)
• 如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)。第一范式的目标是确保每列的原子性。
• 如果一个关系满足1NF,并且除了主键以外的其他列,都依赖于该主键,则满足第二范式(2NF)。第二范式要求每个表只描述一件事情,确保表中的每列,都和主键相关。
• 如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF)。第三范式确保每列都和主键列直接相关,而不是间接相关。
下面我们来看个形象的例子吧!假设某建筑公司要设计一个数据库。公司的业务规则概括说明如下:
• 公司承担多个工程项目,每一项工程有:工程号、工程名称、施工人员等
• 公司有多名职工,每一名职工有:职工号、姓名、性别、职务(工程师、技术员)等
• 公司按照工时和小时工资率支付工资,小时工资率由职工的职务决定(例如,技术员的小时工资率与工程师不同)
• 公司定期制定一个工资报表,如图-1所示
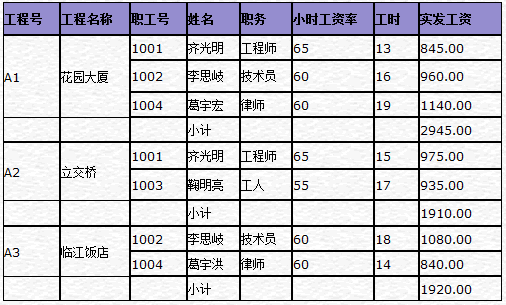
图-1 某公司打印的工资报表
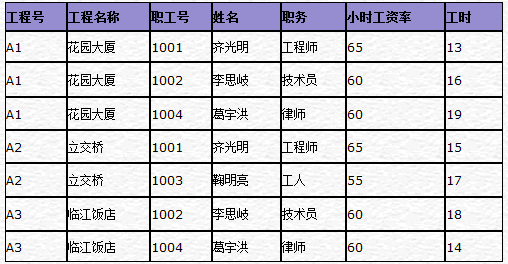
图-2 某公司的项目工时表
大家都看到,上面这样设计的表会有很多问题:
1.表中包含大量的冗余,可能会导致数据异常:
• 更新异常
例如,修改职工号=1001的职务,则必须修改所有职工号=1001的行
• 添加异常
若要增加一个新的职工时,首先必须给这名职工分配一个工程。或者为了添加一名新职工的数据,先给这名职工分配一个虚拟的工程。(因为主关键字不能为空)
• 删除异常
例如,1001号职工要辞职,则必须删除所有职工号=1001的数据行。这样的删除操作,很可能丢失了其它有用的数据
2.采用这种方法设计表的结构,虽然很容易产生工资报表,但是每当一名职工分配一个工程时,都要重复输入大量的数据。这种重复的输入操作,很可能导致数据的不一致性。

我们用第二范式规范一下:
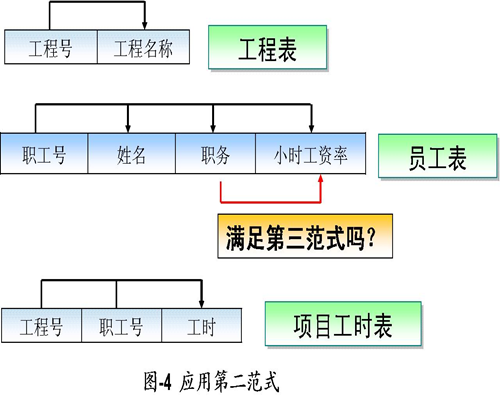
我们再用第三范式规范一下,是不是明晰了很多?!
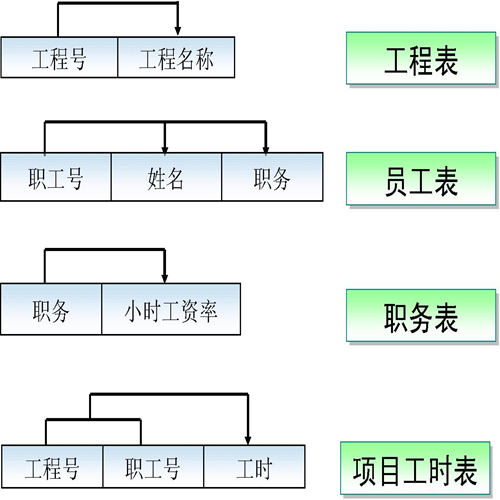
规范化和性能的关系
• 为满足某种商业目标,数据库性能比规范化数据库更重要
– 通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间
– 通过在给定的表中插入计算列(如成绩总分),以方便查询
• 进行规范化的同时,还需要综合考虑数据库的性能。数据库的三大范式和数据库的性能有时是矛盾的。
打个比方:大家都知道,环境保护非常重要,西方总是拿环保问题和中国刁难,说中国为了发展不顾环境保护、生态自然等。可中国目前的经济实力不够强大,如果人都吃不饱,空谈环保还有什么用呢?所以我们只能是在保持地区经济发展的前提下,尽量注重环保问题。这就是一种折中处理问题的典型。本例同样如此:为了满足三大范式,我们在规范化表格时就会拆分出越来越明细的表格。但客户喜欢综合的信息,为了满足客户,我们又需要把这些表通过连接查询还原为客户喜欢的综合数据。这和从一张表中读出数据相比,大大影响了数据库的查询性能。所以有时为了性能,需要做适当折中,适当牺牲规范化的要求,来提高数据库的性能。再如:在成绩表中添加一列-“成绩总分”,属于数据冗余,因为总分在查询时可由各门成绩求出来。但频繁查询成绩总分,并希望保存下来,所以有时表中就干脆添加总分这一列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号