Python网络爬虫规则之实例
(1).实例一:京东商品页面爬取
首先随机选取一款商品,这里我选择了“【一加新品】一加 OnePlus 9R 5G 120Hz 柔性屏12GB+256GB 蓝屿 骁龙870 65W快充 专业游戏配置 超大广角拍照手机【行情 报价 价格 评测】-京东 (jd.com)”,这款商品的URL链接是“https://item.jd.com/100020542894.html”。
注意下京东商城的robots协议,可以在浏览器中输入“https://item.jd.com/robots.txt”即可查看(注意:robots协议随时都有可能改变,根据实际情况选择相应的User-agent),具体如下:
User-agent: Googlebot #抓取网页文字的谷歌机器人 Disallow: User-agent: AdsBot-Google #抓取网页文字,用于Google AdWords的谷歌机器人 Disallow: User-agent: Googlebot-Image #抓取网页图片的谷歌机器人 Disallow:
接着我们用IDLE来进行初步尝试,代码如下:
>>> import requests
>>> url = "https://item.jd.com/100020542894.html"
>>> user = {'user-agent':'Mozilla/5.0'} #伪装成浏览器,当然这里也可以伪装成谷歌机器人
>>> r = requests.get(url,headers=user) #将header包中的用户代理信息变更为浏览器
>>> r.status_code #返回码状态
200 #状态码200表示返回的信息正确,并且获得了这个链接相应的内容
>>> r.encoding #从HTTP header中猜测的响应内容编码方式
'utf-8'
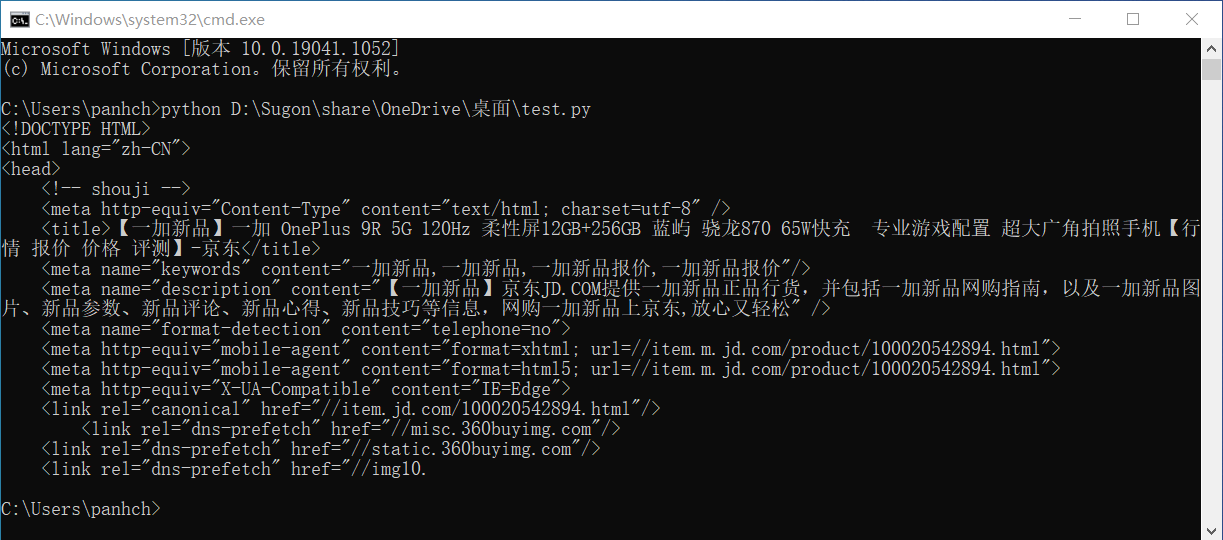
>>> r.text[:1000] #查看前1000个字符
'<!DOCTYPE HTML>\n<html lang="zh-CN">\n<head>\n <!-- shouji -->\n <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
\n <title>【一加新品】一加 OnePlus 9R 5G 120Hz 柔性屏12GB+256GB 蓝屿 骁龙870 65W快充 专业游戏配置 超大广角拍照手机【行情 报价 价格 评测】-京东</title>\n
<meta name="keywords" content="一加新品,一加新品,一加新品报价,一加新品报价"/>\n <meta name="description" content="【一加新品】京东JD.COM提供一加新
品正品行货,并包括一加新品网购指南,以及一加新品图片、新品参数、新品评论、新品心得、新品技巧等信息,网购一加新品上京东,放心又轻松" />\n <meta name="format-detec
tion" content="telephone=no">\n <meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/100020542894.html">\n
<meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/100020542894.html">\n <meta http-equiv="X-UA-Compatible
" content="IE=Edge">\n <link rel="canonical" href="//item.jd.com/100020542894.html"/>\n <link rel="dns-prefetch" href="//misc.360buy
img.com"/>\n <link rel="dns-prefetch" href="//static.360buyimg.com"/>\n <link rel="dns-prefetch" href="//img10.'
注意:如果不对Python爬虫进行伪装,那么它的用户代理信息为“python-requests/x.x.x”,可以通过r.request.headers查看请求的header包,部分将会对此进行限制。
下面将零散的命令转换为脚本文件,这里我将脚本文件命名为test.py,详细内容如下:
import requests
url="https://item.jd.com/100020542894.html"
user = {'user-agent':'Mozilla/5.0'}
try:
r = requests.get(url,headers=user)
r.raise_for_status() #判断返回值是否为200,如果不是200则抛出异常
r.encoding = r.apparent_encoding #将编码方式更改为从响应内容文本中分析出来的编码方式
print(r.text[:1000]) #输出前1000个字符
except:
print("爬取失败")
test.py脚本文件编辑完成后,在Window系统下,我们打开命令提示符(cmd),输入“python [test.py绝对地址]”即可运行测试。
(2).实例二:百度/360搜索关键词提交
首先在百度搜索和360搜索中输入搜索内容,然后可以得到搜索内容的URL。然后查看URL可以发现,百度搜索的关键词接口为“http://www.baidu.com/s?wd=keyword”(https无法获取),360搜索的关键词接口为“https://www.so.com/s?q=keyword”
接着我们用IDLE进行初步尝试,代码如下:
>>> import requests
>>> baidu = {'wd':'迪迦奥特曼'}
>>> tsz = {'q':'迪迦奥特曼'}
#百度搜索
>>> r = requests.get("http://www.baidu.com/s",params=baidu)
>>> r.status_code
200
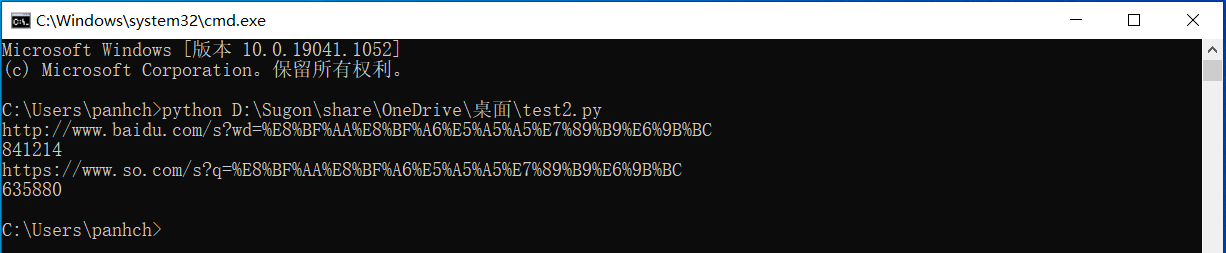
>>> r.request.url #发送的URL链接
'http://www.baidu.com/s?wd=%E8%BF%AA%E8%BF%A6%E5%A5%A5%E7%89%B9%E6%9B%BC'
>>> len(r.text) #文本长度
844513
#360搜索
>>> r = requests.get("https://www.so.com/s",params=tsz)
>>> r.status_code
200
>>> r.request.url #发送的URL链接
'https://www.so.com/s?q=%E8%BF%AA%E8%BF%A6%E5%A5%A5%E7%89%B9%E6%9B%BC'
>>> len(r.text) #文本长度
538407
下面将零散的命令转换为脚本文件,这里我将脚本文件命名为test2.py,详细内容如下:
import requests
baidu = {'wd':'迪迦奥特曼'}
tsz = {'q':'迪迦奥特曼'}
try:
r = requests.get('http://www.baidu.com/s',params = baidu)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
r2 = requests.get('https://www.so.com/s',params = tsz)
print(r2.request.url)
r2.raise_for_status()
print(len(r2.text))
except:
print('爬取失败')
test2.py脚本编辑完成后,在Window系统下,我们打开命令提示符(cmd),输入“python [test.py绝对地址]”即可运行测试。
(3).实例三:网络图片的爬取和存储
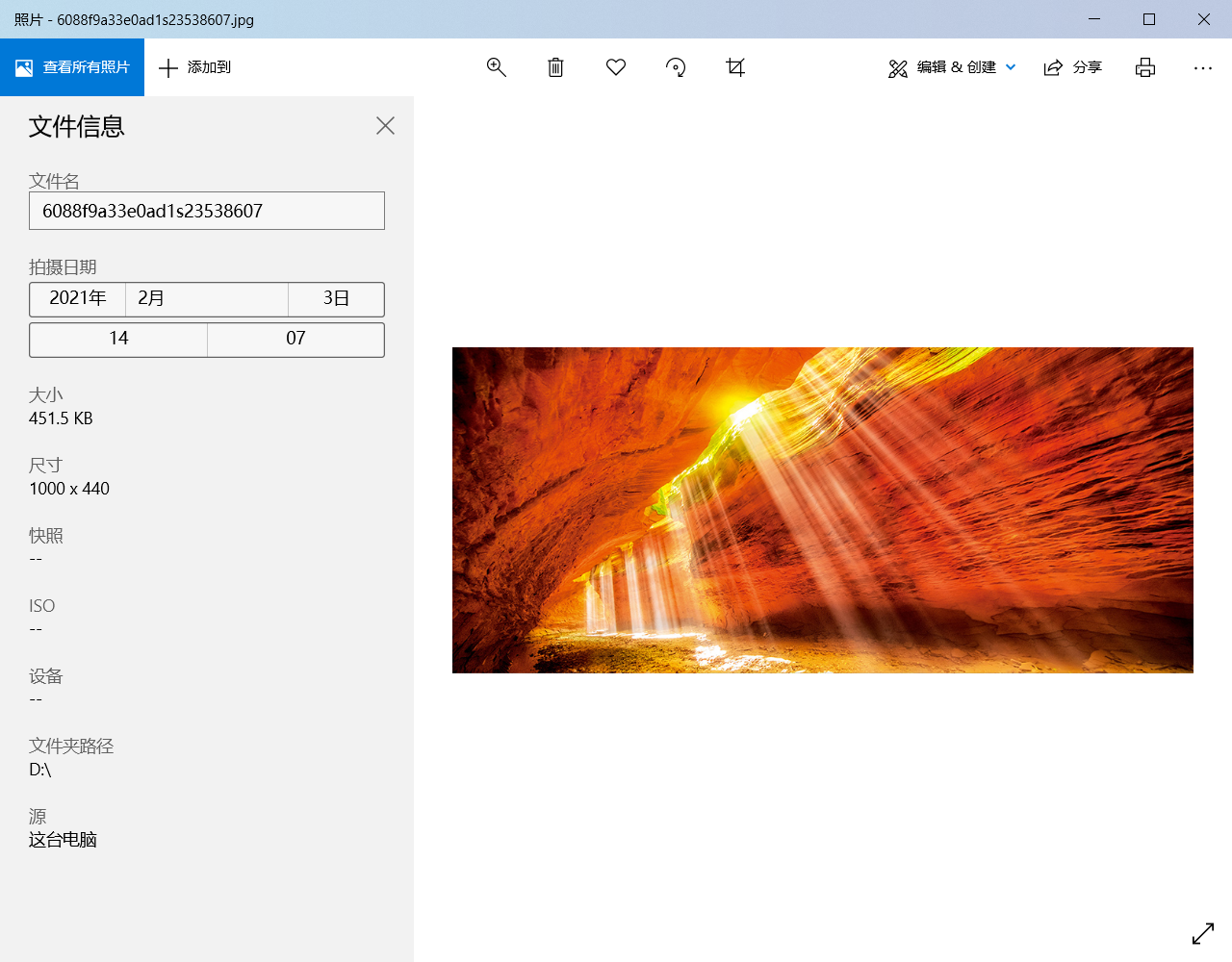
首先找一个网站去获取一个图片的网址,这里我原本准备使用京东的网络图片,但由于京东的图片对于部分人来说不是很好找,所以这里采用中国国家地理网的图片,详细地址为http://img0.dili360.com/pic/2021/04/28/6088f9a33e0ad1s23538607.jpg。
接着我们使用IDLE进行初步尝试,代码如下:
>>> import requests >>> url = "http://img0.dili360.com/pic/2021/04/28/6088f9a33e0ad1s23538607.jpg" >>> path = "D:/abc.jpg" >>> r = requests.get(url) >>> r.status_code 200 >>> with open(path,'wb') as f: #以二进制文本写的形式打开文件,文件标识为f f.write(r.content) #r.content表示返回内容的二进制形式,f.write()表示将内容写入文件 462310 >>> f.close() #关闭文件
这样就可以在D盘找到一个名为abc.jpg的图片文件,可以打开试试是否正常。
下面将零散的命令转换为脚本文件,这里我将脚本文件命名为test3.py,详细内容如下:
import requests
import os #导入os基础交互库
url = "http://img0.dili360.com/pic/2021/04/28/6088f9a33e0ad1s23538607.jpg"
root = "D:/"
path = root + url.split('/')[-1] #这里采用了图片的原名称
try:
if not os.path.exists(root): #判断父目录是否存在
os.mkdir(root) #如果不存在,那么创建父目录
if not os.path.exists(path): #判断文件是否存在
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
else:
print('文件已存在')
except:
print('爬取失败')
test3.py脚本编辑完成后,在Window系统下,我们打开命令提示符(cmd),输入“python [test.py绝对地址]”即可运行测试。这里我就直接演示下拉取下来的图片
(4).实例四:IP地址归属地的自动查询
这里我们借用“https://www.ip138.com”,搜索IP地址后URL链接变为“https://www.ip138.com/iplookup.asp?ip=144.144.144.144&action=2”。
首先使用IDLE进行初步尝试,代码如下:
>>> import requests
>>> url = "https://www.ip138.com/iplookup.asp?ip=144.144.144.144&action=2"
>>> r = requests.get(url)
>>> r.status_code #返回码为404
404
>>> user = {'user-agent':'Mozilla/5.0'} #伪装成浏览器访问
>>> r = requests.get(url,headers=user)
>>> r.status_code #返回码正常
200
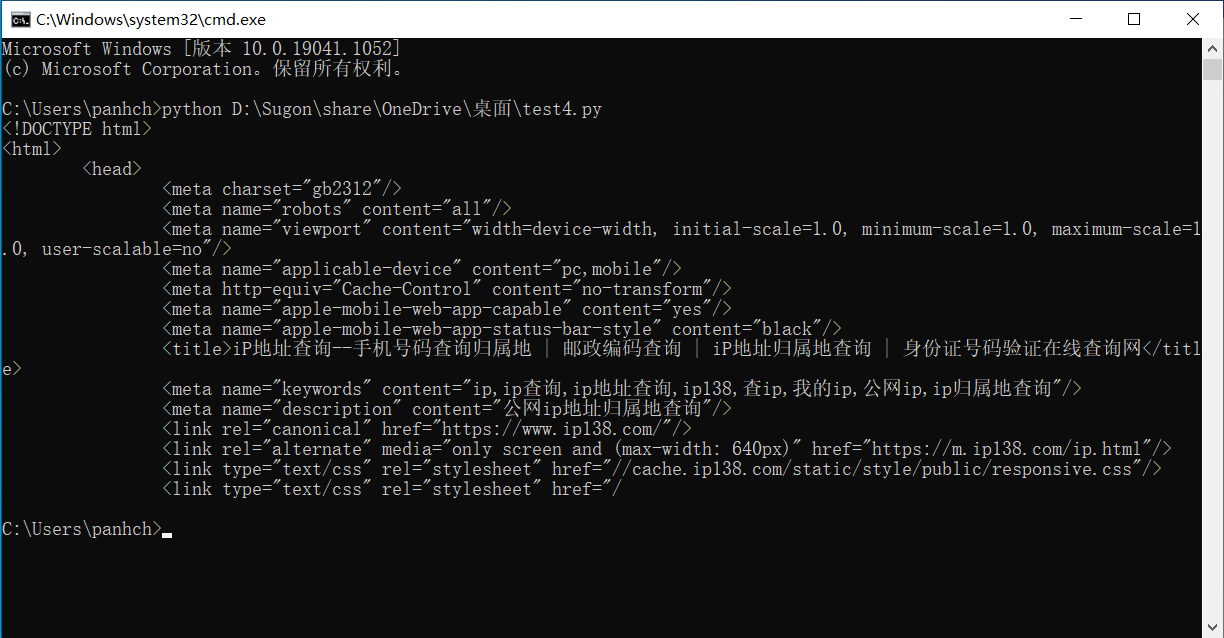
>>> r.text[:1000] #发现有乱码
'<!DOCTYPE html>\r\n<html>\r\n\t<head>\r\n\t\t<meta charset="gb2312"/>\r\n\t\t<meta name="robots" content="all"/>\r\n\t\t<meta name="viewport"
content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no"/>\r\n\t\t<meta name="applicable-devic
e" content="pc,mobile"/>\r\n\t\t<meta http-equiv="Cache-Control" content="no-transform"/>\r\n\t\t<meta name="apple-mobile-web-app-capable" con
tent="yes"/>\r\n\t\t<meta name="apple-mobile-web-app-status-bar-style" content="black"/>\r\n\t\t<title>iPµØÖ·²éѯ--ÊÖ»úºÅÂë²éѯ¹éÊôµØ | ÓÊÕþ±à
Âë²éѯ | iPµØÖ·¹éÊôµØ²éѯ | Éí·ÝÖ¤ºÅÂëÑéÖ¤ÔÚÏß²éѯÍø</title>\r\n\t\t<meta name="keywords" content="ip,ip²éѯ,ipµØÖ·²éѯ,ip138,²éip,ÎÒµÄip,¹«Íø
ip,ip¹éÊôµØ²éѯ"/>\r\n\t\t<meta name="description" content="¹«ÍøipµØÖ·¹éÊôµØ²éѯ"/>\r\n\t\t<link rel="canonical" href="https://www.ip138.com/"
/>\r\n\t\t<link rel="alternate" media="only screen and (max-width: 640px)" href="https://m.ip138.com/ip.html"/>\r\n\t\t<link type="text/css" r
el="stylesheet" href="//cache.ip138.com/static/style/public/resp'
>>> r.encoding = r.apparent_encoding #将编码方式更改为从响应内容文本中分析出来的编码方式
>>> r.text[:1000] #再次查看正常
'<!DOCTYPE html>\r\n<html>\r\n\t<head>\r\n\t\t<meta charset="gb2312"/>\r\n\t\t<meta name="robots" content="all"/>\r\n\t\t<meta name="viewport"
content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no"/>\r\n\t\t<meta name="applicable-devic
e" content="pc,mobile"/>\r\n\t\t<meta http-equiv="Cache-Control" content="no-transform"/>\r\n\t\t<meta name="apple-mobile-web-app-capable" con
tent="yes"/>\r\n\t\t<meta name="apple-mobile-web-app-status-bar-style" content="black"/>\r\n\t\t<title>iP地址查询--手机号码查询归属地 | 邮政编码查询
| iP地址归属地查询 | 身份证号码验证在线查询网</title>\r\n\t\t<meta name="keywords" content="ip,ip查询,ip地址查询,ip138,查ip,我的ip,公网ip,ip归属地查询"/>
\r\n\t\t<meta name="description" content="公网ip地址归属地查询"/>\r\n\t\t<link rel="canonical" href="https://www.ip138.com/"/>\r\n\t\t<link rel="
alternate" media="only screen and (max-width: 640px)" href="https://m.ip138.com/ip.html"/>\r\n\t\t<link type="text/css" rel="stylesheet" href=
"//cache.ip138.com/static/style/public/responsive.css"/>\r\n\t\t<link type="text/css" rel="stylesheet" href="/'
接着将零散的命令转换为脚本文件,这里我将脚本文件命名为test4.py,详细内容如下:
import requests
url = "https://www.ip138.com/iplookup.asp?ip=144.144.144.144&action=2"
user = {'user-agent':'Mozilla/5.0'}
try:
r = requests.get(url,headers=user)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[0:1000])
except:
print('爬取失败')
test4.py脚本编辑完成后,在Window系统下,我们打开命令提示符(cmd),输入“python [test.py绝对地址]”即可运行测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}