Python3基本数据类型
(1).数字类型
1)整数类型(int)
Python中的整数类型与数学中的整数概念一致,它可正可负没有取值范围限制(只是理论上的无限,实际上机器内存有限,不可能无限大)。
注意:在python2中整数型是有大小限制的,在32位机器上,整数的二进制位数为32,取值范围为-2^31~2^31-1,即-2147483648~2147483647;在64位机器上,整数的二进制位数为64,取值范围为-2^63~2^63-1,即-9223372036854775808~9223372036854775807。超过这个范围的整数类型就是long型。
整数类型的四种表现方式:
二进制:以0b或0B开头,例如0b010,-0B101
八进制:以0o或0O开头,例如0o123,-0O456
十进制:不做说明和演示
十六进制:以0x或0X开头,例如0x9a,-0X89
2)浮点数类型
Python中的浮点数与数学中的实数概念一致,它指的是带有小数点以及小数的数字。与整数不同,浮点数的取值范围和小数精度都存在限制,但常规计算时可以忽略。
浮点数取值范围从数量级上讲大约是-10^308~10^308,精度数量级约为10^-16,也就是说两个小数之间的差别最小可以表示到10^-16这个数量级。
但是浮点数有一个特性需要特别注意:浮点数间运存存在不确定尾数,这不是BUG。这里举一个例子0.1+0.2应该得出的是0.3,但是Python计算出来的却不是0.3,如下:
>>> 0.1+0.2 0.30000000000000004 >>> 0.1+0.3 0.4
其实这个不确定尾数并不止Python中存在,许多编程语言中都存在,它涉及到了计算机对数字运算的内部实现原理。
Python使用的IEEE 754标准(52M/11E/1S),该标准采用8字节的64位二进制存储空间,分配了52位来存储浮点数的有效数字,11位存储指数,1位存储正负号(也是Python常说的53位二进制表示小数部分,52+1,2^53-2=9007199254740990,约为10^16),即这是一种二进制版的科学计数法格式。
还需要了解十进制小数与二进制小数之间互相转换问题,首先来看一下十进制小数转换为二进制小数:
原十进制小数为0.1 0.1*2=0.2——取整数部分填充当前二进制小数位——0——剩余非零部分用于继续运算——0.2 0.2*2=0.4——取整数部分填充当前二进制小数位——0——剩余非零部分用于继续运算——0.4 0.4*2=0.8——取整数部分填充当前二进制小数位——0——剩余非零部分用于继续运算——0.8 0.8*2=1.6——取整数部分填充当前二进制小数位——1——剩余非零部分用于继续运算——0.6 0.6*2=1.2——取整数部分填充当前二进制小数位——1——剩余非零部分用于继续运算——0.2 ......之后进入无限循环
但是到了Python中并不能无限循环,从第53位开始进行舍入,舍入规则为0舍1入,那么0.1转换为二进制小数实际为0.00011001100110011001100110011001100110011001100110011010。注意:4个二进制为一个整体。
二进制小数转换为十进制小数:
原二进制小数为0.00011001100110011001100110011001100110011001100110011010 0*2^-1+ 0*2^-2+ 0*2^-3+ 1*2^-4+ 1*2^-5+ 0*2^-6+ ...... 1*2^-53+ 0*2^-54+ 1*2^-55+ 0*2^-56= 0.10000000000000000055511151231257827021181583404541015625
可以看到经过两次转行后出现了非常长的尾数,只是在浮点数输出时只输出了前16位小数。所以我们可以得出一个结论,二进制表示小数,可以无限接近,但不完全相同。这也是不确定尾数产生的原因,在运算时会先将十进制转换为二进制,再进行运算,运算完成后再由二进制转换为十进制。
随之也带来了另一个问题,运算后的数值比较。由于不确定尾数的存在,不能直接进行比较,必须使用round(x,d)函数,对数值x进行四舍五入,d为小数精确位数。
>>> 0.1+0.2==0.3 False >>> round(0.1+0.2,1)==0.3 True
Python浮点数可以使用字母e或E作为幂的符号,以10为基数的科学计数法,格式为<a>e<b>,表示a*10^b。例如96000,采用科学计数法就是9.6e4;0.0043,采用科学计数法就是4.3E-3。
3)复数类型
在众多的编程语言中,只有Python提供了复数类型,复数类型与数学中的复数概念一致。定义j2=-1,即j=√(-1),以此为基础构建的数学体系。a+bj被成称为复数,其中a为实部,bj整个是虚数部分,b为虚部。例如:z=1.23e-4+5.6e+89j,那么z就是一个复数类型,可以使用z.real获取实部1.23e-4,z.imag获取虚部5.6e+89。
客观的来说,在常规的计算机编程中复数类型很少被使用,但它却是进行空间变换,尤其是跟复变函数相关的科学体系中最常用的一种类型。
4)数值运算操作符
| 操作符及使用 | 描述 |
| x + y | 加,x与y之和 |
| x - y | 减,x与y之差 |
| x * y | 乘,x与y之积 |
| x / y | 除,x与y之商,10/3=3.3333333333333335 |
| x // y | 整数除,x与y之整数商,10//3=3 |
| + x | x本身 |
| - y | y的负值 |
| x % y | 余数,模运算,10%3=1 |
| x ** y |
幂运算,x的y次幂,x^y。当y为小数时,那么就是开根, 4**0.5=√4=2,8**(1/3)=2 |
二元操作符有对应的增强赋值操作符
| 增强操作符以及使用 | 描述 |
| x op= y |
即x = x op y,其中op为二元操作符。 x+=y x-=y x/=y x*=y x//=y x%=y x**=y >>> x=3.14 |
注意:不同的数字类型可以进行混合运算,最终结果以最宽的类型为准。整数-->浮点数-->复数。
5)数值运算函数
以下介绍的都是Python的内置函数,更多数值运算函数需要使用math库
| 函数 | 返回值(描述) |
| abs(x) | 返回x的绝对值,例如abs(-10.01)结果为10.01 |
| divmod(x,y) | 换回一个整数商x//y和余数x%y的元组,例如divmod(10,3)结果为(3,1) |
| pow(x,y[,z]) |
幂余,(x**y)%z,z可以省略只求幂。例如pow(3,pow(3,99),10000),结果为4587,显示幂运算的最后四位 |
| round(x[,d]) | 返回浮点数x的四舍五入值,d是保留小数位数,默认为0,例如round(-10.123,2),结果为-10.12 |
| max(x1,x2,...,xN) | 最大值,返回给定参数的最大值,参数可以为序列 |
| min(x1,x2,...,xN) | 最小值,返回给定参数的最小值,参数可以为序列 |
6)数字类型转换函数
| 函数 | 描述 |
| int(x) | 将x变为整数,舍弃小数部分。例如int(1.23)结果为1,int("123")结果为123 |
| float(x) | 将x变为浮点数,增加小数部分。例如float(12)结果为12.0,float("1.23")结果为1.23 |
| complex(real [,imag]) | 创建一个复数 |
(2).字符串类型
字符串提供了两类四种表示方法:
1、由一对单引号或双引号表示,仅表示单行字符串
2、由一对三单引号或三双引号表示,可以表示多行字符串
举例如下:
"请输入带有符号的温度值:"
'C'
'''Python
语言'''
"""全输出结果为
72C"""
说到一对三引号,很容易和Python的多行注释联系在一起。实际上,Python并没有真正提供多行注释的表达方式,三单引号构成的就是字符串,只是没有赋给任意变量,那么它就可以当做注释使用。
之所以Python通过了两类四种表达方式,是为了更好处理字符串中的单引号和双引号,如果同时存在单引号和双引号可以使用一对三单引号或三双引号。
1)字符串的序号
一段字符串可以由左往右进行编号,实现正向递增序号,从0开始向上增长;也可以从结尾处想头部方向索引,那么构成的就是反向递减序号,从-1开始递减
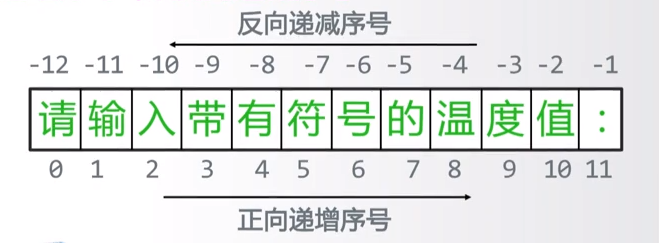
字符串中最重要的两个操作:索引和切片,它们就使用到了字符串的序号。索引和切片使用[]来获取字符串中单个字符或一段字符。
索引:返回字符串中单个字符,格式:<字符串|变量名>[N],实例:
>>> "请输入带有符号的温度值:"[1] '输' >>> Str="请输入带有符号的温度值:" >>> Str[-2] '值'
切片:返回字符串中的一段字符串,格式<字符串|变量名>[M:N],M省略表示从头开始,N省略表示直到末尾,实例:
>>> "请输入带有符号的温度值:"[1:2] '输' >>> Str="请输入带有符号的温度值:" >>> Str[:-2] '请输入带有符号的温度' >>> Str[-4:] '温度值:'
注意:切片是从M到N-1的字符串,并不包含N。
下面介绍切片的高级用法,切片使用<字符串|变量名>[M:N:K],根据步长K对字符串进行切片。实例:
>>> "零一二三四五六七八九"[1:8:2] '一三五七'
切片还有一种特殊用法,倒序,即K=-1时。实例:
>>> "零一二三四五六七八九"[::-1] '九八七六五四三二一零'
2)转义字符
转义字符表达特定字符的本意
| 转义字符 | 描述 |
| \ | 单个反斜杠在一行末尾时,表示续行符 |
| \\ | 反斜杠 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(BackSpace) |
| \000 | 空 |
| \n | 换行,光标移动到下行行首 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车,光标移动到本行行首 |
| \f | 换页 |
| \oyy | 八进制数,例如:\o12代表换行 |
| \xyy | 十六进制数,例如:\x0a代表换行 |
| \other | 其他的字符都以普通格式输出 |
3)字符串操作符
| 操作符及使用 | 描述 |
| x + y | 连接两个字符串x和y,例如"hello" + "world"结果为"helloworld" |
| n * x或x * n | 复制n次字符串x,n为正整数,例如2 * "hello"结果为"hellohello" |
| x in s |
in是Python保留关键字,这里当做操作符使用。如果字符串s中包含字符串x,那么返回True,否则返回False。 例如:"llo" in "helloworld",返回True |
| x not in s | 与in的用法相反 |
4)字符串处理函数
Python中提供了一些以函数形式来实现的字符串处理功能,称之为字符串处理函数。Python提供了6个有用的内置函数,如下:
| 函数及使用 | 描述 |
| len(x) |
返回字符串x的长度,例如:len("一二三456")结果为6。 注意:在Python中,无论是数字、标点符号、英文字母或汉字都是一个字符,长度是相同的 |
| str(x) | 将任意类型的x转换为对应的字符串形式,例如:str(1.23)结果为"1.23",str([1,2])结果为"[1,2]" |
| hex(x)或oct(x) | 将整数x转换为小写十六进制或八进制的字符串,例如:hex(425)结果为"0x1a9",oct(425)结果为"0o651" |
| chr(u) | u位Unicode编码,返回其对应的单字符 |
| ord(x) | x为单字符,返回其对应的Unicode编码 |
5)字符串处理方法
这里的“方法”特指<a>.<b>()风格中的函数<b>(),或者说“方法”本身也是函数,但与<a>有关,它是<a>能够提供的函数,而且方法必须采用<a>.<b>()的形式使用。
字符串与变量也是一种<a>,存在一些操作方法。客观讲方法是面向对象语言的专有名词,<a>是对象,<b>()是方法。
这里介绍常用的8个字符串处理方法:
| 方法及使用 | 描述 |
| str.lower()或str.upper() |
使用这两个函数可以将字符串中的所有字符全小写或大写, 例如:"AaBbCcDd".lower()结果为"aabbccdd" "AaBbCcdD".upper()结果为"AABBCCDD" |
| str.split(sep=None) |
返回一个列表,这个列表由字符串str根据字符串sep被分割的部分组成, 例如:"A,B,C".split(",")结果为['A','B','C'] |
| str.count(sub) |
返回子字符串sub在字符串str中出现的次数,例如: "an apple a day".count("a")结果为4 |
| str.replace(old,new[,max]) |
将字符串str中old子串替换为new子串,如果存在整数max,表示替换次数上限, 例如:"python".replace("n",'n123')结果为"python123" |
| str.center(width[,fillchar]) |
返回width宽度str居中的字符串,如果存在fillchar,那么空余部分使用fillchar填充, 例如:"python".centor(10)结果为" python ", "python".center(10,"=")结果为"==python==" |
| str.strip(chars) |
对照字符串chars中列出的字符,将字符串str左侧和右侧存在的相同字符去除,例如: "helloworld".strip("helod")结果为"wor"。strip()也可以认为是同时执行了lstrip()和rstrip() |
| str.join(iter) |
以指定字符串str作为分隔符,将iter所有字符分隔,重新组成一个新的字符串,例如: ",".join("python")结果为"p,y,t,h,o,n" |
6)字符串类型的格式化
格式化是对字符串进行格式表达的方式。字符串格式化使用.format()方法,输出样式如下:<模板字符串>.format(<参数1>,<参数2>,...,<参数n>)。在具体的使用中需要用到一个新的概念:槽,槽相当于一个信息占位符,它是使用一对{}来表示,它只在字符串中有用。
实例1:
字符串中槽{}的默认顺序 format()中参数的顺序
--------------------------------> ------------------>
0 1 2 0 1 2
^ ^ ^ ^ ^ ^
| | | | | |
| | | | | |
>>> "{ }:计算机{ }的CPU占用率为{ }%".format("2020-03-13","A",10)
'2020-03-13:计算机A的CPU占用率为10%'
在实例1中,设置了三个槽,它与其他待输出的字符信息共同组成了字符串,每一个槽中所要添加的内容与.format()中对应的参数是一致的。
在不指定槽的序列的情况下,模板字符串的槽的序列从0开始,依次增加,与format中的参数序列一一对应,填充到槽中。进一步来说,我们可以在槽中,指定需要添加的参数位置。
我们将实例1进行变化,形成一个新的实例,实例2:
_________________________________________________
| ________________________________ |
| | | |
>>> "{1}:计算机{0}的CPU占用率为{2}%".format("2020-03-13","A",10)
| |
————————————————————————————
'A:计算机2020-03-13的CPU占用率为10%'
在槽中填写format对应的参数序列,让槽去调取format中对应的参数,完成字符串的格式化。
还需要关注槽内部使用格式化的控制标记,来进行格式控制(参数的格式化),槽内部对格式化的配置方式,如下:{<参数序列>:格式控制标记}。简单来讲,在槽的内部,除了槽的参数序列之外,通过一个引号来引导一些参数,控制某一个变量在槽位置的输出格式,Python一共提供了六种格式控制标记,分别是<填充>、<对齐>、<宽度>、<,>、<.精度>和<类型>。六种格式控制标记可以分为两组,前三个一组,后三个一组。
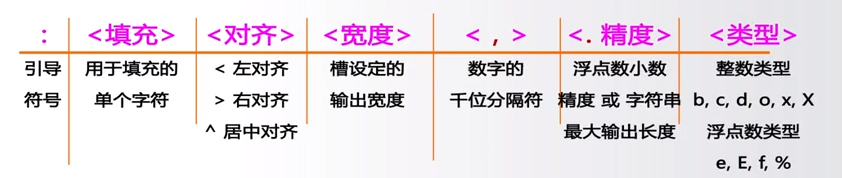
<填充>、<对齐>和<宽度>,这一组概念的基本模式是:首先给出一个输出<宽度>,然后决定即将输出的这个参数在这个宽度中的<对齐>方式,最后如果还有空余的空间用什么字符<填充>(如果没有<填充>,那么采用空格补齐的方式),这三项就决定了一个基本的格式。举个例子,<填充>-->"=",<对齐>-->“^”,<宽度>-->“20”:
>>> "{0:=^20}".format("PYTHON")
'=======PYTHON======='
<.>、<.精度>和<类型>都与具体的数字有关,第一个<,>比较特殊,它指的是数字的千位分隔符;第二个<.精度>需要注意,在精度前有一个小数点,它表示的是浮点数小数的精度,或者表示字符串最大的输出长度;第三个<类型>,表示以什么类型将变量放到槽中。举个例子:
>>> "{0:,.2f}".format(12345.6789)
'12,345.68'
>>> "{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425)
'110101001,Ʃ,425,651,1a9,1A9'
>>> "{0:e},{0:E},{0:f},{0:%}".format(3.14)
'3.140000e+00,3.140000E+00,3.140000,314.000000%'
(3).布尔类型
布尔类型是一个非常特殊的类型,所有标准对象均可用于布尔测试,同类型的对象之间可以比较大小。每个对象天生具有布尔True或False值。空对象,值为零的任何数字或者Null对象None的布尔值都是False。在Python3中True=1,False=0,可以和数字型进行运算。
下列对象的布尔值是False:None;False;0(整型),0.0(浮点型);0L(长整形);0.0+0.0j(复数);“”(空字符串);[](空列表);()(空元组);{}(空字典)。
值不是上列的任何值的对象的布尔值都是True,例如non-empty,non-zero等。用户创建的类实例如果是定义了nonzero(_nonzeor_())或length(_len_())且值为0,那么它们的布尔值就是False。
(4).序列类型
序列类型是Python组合数据类型中非常重要的一种类型结构,在编程中会经常使用。序列是具有先后关系的一组元素,可以理解为序列是一维元素的向量。正是因为序列存在先后关系,所以元素之间可以相同,元素的类型可以不同。Python序列类型类似于数学元素序列,也是由序号来引导的,可以通过类似下标的整数序列编号方式来进行访问。
序列是一个基本的数据类型(也叫基本类型),一般在使用中不会直接使用序列类型,而是使用序列类型衍生出来的几种数据类型,比如:字符串类型、元组类型和列表类型等。但是序列类型的所有操作,在衍生类型中都是适用的,同时衍生类型又有各自独特的操作能力,所以序列类型是一种基础的数据类型。
序列类型有一个关于序号的定义,也就是说序列中的元素存在正向递增的序号索引关系和反向递减的序号索引关系。
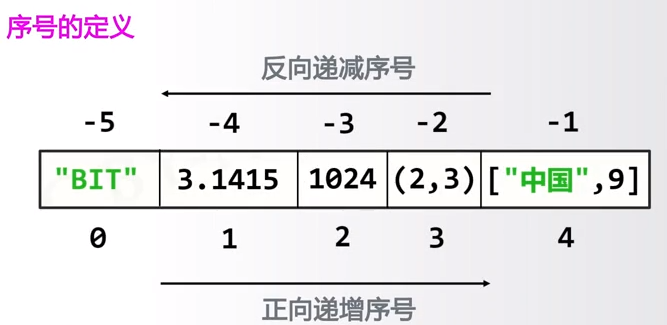
1)序列处理函数及方法
序列操作符:
| 操作符及应用 | 描述 |
| x in s | 如果序列s包含元素x,则返回True,否则返回False |
| x not in s | 与x in s相反 |
| s + t | 连接两个序列s和t |
| s * n或n * s | 将序列s复制n次 |
| s[i] | 索引,返回序列s中的第i个元素,i是序列的序号,序号有正向递增和反向递减两种 |
| s[i:j]或s[i:j:k] |
切片,返回序列s中[i,j)(大于等于i,小于j),以k为步长的元素子序列。 特殊用法:i=j=0,k=-1表示倒序 |
序列方法:
| 函数和方法 | 描述 |
| len(s) | 返回序列s的长度 |
| min(s) | 返回序列s的最小元素,需要序列s中的元素可比较,如果在序列中元素是不同类型、不能比较,那么将报错 |
| max(s) | 返回序列s的最大元素,需要序列s中的元素可比较,如果在序列中元素是不同类型、不能比较,那么将报错 |
|
s.index(x)或 s.index(x,i,j) |
返回序列s中[i,j)(大于等于i,小于j)第一次出现元素x的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
2)元组类型及操作
元组是序列类型的一种扩展,它本质上是一种序列类型,但它有一个独特的特点,元组一旦被创建就不能被修改。
元组使用()表示,元素之间用逗号(,)分隔。创建一个元组需要使用()或tuple()函数,在使用时也可以不使用(),例如:
def func():
return 1,2
在Python内部,Python会认为函数返回了一个值,这个值是元组类型。
创建元组类型实例:
>>> creature="cat","dog","tiger","human"
>>> creature
('cat', 'dog', 'tiger', 'human')
>>> color=(0x001100,"blue",creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
元组类型就是将元素进行有序排列,用()形式来组织,元组类型的每个元素一旦被定义,那么它的元素值是不能改变的。元组类型继承了序列类型的全部通用操作,并且因为元组创建后不能修改,所以元组类型没有特殊的针对自身的操作(其实用一个那就是上面提到的tuple()函数,用来转换为元组类型)。实例:
>>> creature="cat","dog","tiger","human"
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color=(0x001100,"blue",creature)
>>> color[-1][2]
'tiger'
3)列表类型及操作
列表是序列类型的一种扩展,它与元组类型很相似,但它十分常用。列表本质上是一种序列类型,但它创建后其中的元素可以随意被修改,可以向其中随意增加元素或减少元素,使用起来非常灵活。
列表类型使用[]表示,元素之间用逗号(,)分隔。创建一个列表需要使用[]或list()函数,列表中各元素类型可以不同,列表也没有长度限制。例如:
>>> ls=["cat","dog","tiger",1024] >>> ls ['cat', 'dog', 'tiger', 1024] >>> lt=ls >>> lt ['cat', 'dog', 'tiger', 1024] >>> ls[1]="human" >>> ls ['cat', 'human', 'tiger', 1024] >>> lt ['cat', 'human', 'tiger', 1024]
注意:使用[]或list()函数是真正创建一个列表,如果仅使用等号(=)将一个列表变量赋值给另一个列表变量,那么此时并没有在系统中真正的创建一个列表,而是将同一个列表赋给不同的名字,当其中一个变量被修改时,另一个变量也会被修改,类似于Linux的软链接、Windows的快捷方式。
列表类型的操作函数和方法:
| 函数或方法 | 描述 |
| ls[i]=x | 替换列表中第i元素为x |
| ls[i:j:k]=lt | 用列表替换ls切片后对应元素子列表 |
| del ls[i] | 删除列表ls中第i元素 |
| del ls[i:j:k] | 删除列表ls中[i:j)(大于等于i,小于j)以步长为k的元素 |
| ls+=lt | 更新列表ls,将列表lt元素添加到列表ls之后 |
| ls*=n | 更新列表ls,使得这个列表元素重复n次 |
| ls.appedn(x) | 在列表ls最后增加一个元素x |
| ls.clear() | 删除列表ls中所有元素 |
| ls.copy() | 生成一个新列表,包含ls中所有元素 |
| ls.insert(i,x) | 在列表ls的第i位增加元素x |
| ls.pop(i) | 将列表ls中第i位元素取出,并删除列表中该元素 |
| ls.remove(x) | 将列表ls中第一次出现的元素x删除 |
| ls.reverse() | 将列表中的元素反转 |
| sorted(ls) | 对列表ls进行排序 |
| ls.sort(cmp=None, key=None, reverse=False) |
对列表ls进行排序 cmp:可选参数, 如果指定了该参数会使用该参数的方法进行排序。 key:主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 reverse:排序规则,reverse = True 降序, reverse = False 升序(默认)。 |
实例:
>>> ls=["cat","dog","tiger",1024] >>> ls[1:2]=[1,2,3,4] >>> ls ['cat', 1, 2, 3, 4, 'tiger', 1024] >>> del ls[::3] >>> ls [1, 2, 4, 'tiger'] >>> ls*2 [1, 2, 4, 'tiger', 1, 2, 4, 'tiger'] >>> ls.append(1234) >>> ls [1, 2, 4, 'tiger', 1234] >>> ls.insert(3,"human") >>> ls [1, 2, 4, 'human', 'tiger', 1234] >>> ls.reverse() >>> ls [1234, 'tiger', 'human', 4, 2, 1]
4)序列类型应用场景
序列包含元组、列表两种重要的扩展类型,序列类型最主要的场景是用来做数据表示。其中元组用于表示元素不改变的应用场景,它更多用于固定搭配场合,例如函数的返回值return。列表则更加灵活,如果希望用一个数据类型处理一组数据,并且处理的功能又比较多样,那么尽可能使用列表,它也是最常用的序列类型。
数据表示指的是我们要用元组或列表这样的数据类型来表达一组有序数据,通过这样的类型表达了有序数据,我们就可以进而操作它们,所以元组和列表最大的作用就是对一组数据的表示。有了这种表示之后,我们很简单可以对一组数据进行遍历。
此外,序列类型中的元组正是因为它有不可改变元素的特点,在某些场景我们可以对数据通过元组类型进行保护。换句话说,如果不希望数据被程序某些功能所修改,我们就把这组数据转换为元组类型。
(5).集合类型
集合类型是组合数据类型非常重要的一种表达方式,是多个元素的无序组合。Python中的集合类型与数学中的集合概念一致,集合元素之间无序,在集合中不存在相同元素,即每一个元素都是独一无二的。在Python的集合类型中,它要求放入集合中的元素是不可变数据类型,例如:整数、浮点数、复数、字符串、元组等。注意:列表是可变数据类型。
在Python中集合用{}表示,元素之间用逗号(,)分隔。创建一个集合需要使用{}或set()函数。如果创建一个空集合必须采用set(),因为{ }是用来创建空字典的。
例如:
>>> A={"python",123,("python",123)} #使用{}创建集合
>>> print(A)
{'python', ('python', 123), 123}
>>> B=set("pypy123") #使用set()创建集合,将字符串中的每一个字符单独拆分变成集合的一个元素。
>>> print(B) #由于给定的字符串中存在相同的字符,生成集合后相同的字符只保留一个,并且无序存在。
{'1', '3', '2', 'p', 'y'}
>>> C={"python",123,"python",123} #使用{}创建的集合一样会将相同的元素去除,只保留一个
>>> print(C)
{'python', 123}
1)集合操作符
在数学中,集合之间存在一些可能的运算,这种运算主要有四种,分别是并运算、差运算、交运算和补运算。
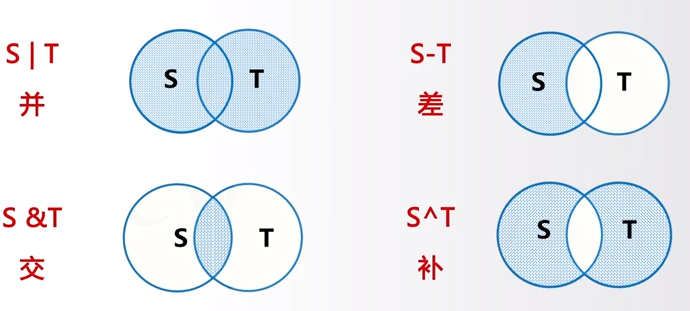
在Python中提供了如下操作符来表达集合之间的运算:
| 操作符与应用 | 描述 |
| S | T | 返回一个新集合,包含集合S和T中所有元素,实现了集合之间的并 |
| S - T | 返回一个新集合,包含集合S中的元素但不包括T中的元素,实现了集合之间的差 |
| S & T | 返回一个新集合,包括同时在集合S和T中的元素,实现了集合之间的交 |
| S ^ T | 返回一个新集合,包括集合S和T中的非相同元素,实现了集合间的补 |
| =、>、>=、<、<= | 返回True或False,判断集合间的子集(包含)关系 |
Python还提供了增强操作符,通过四种基础操作符和赋值符号的组合来实现对集合S的更新,如下:
| 操作符及应用 | 描述 |
| S |= T | 更新集合S,包含集合S和T中所有元素 |
| S -= T | 更新集合S,包含集合S中的元素但不包含T中的元素 |
| S &= T | 更新集合S,包含同时在集合S和T中的元素 |
| S ^= T | 更新集合S,包含集合S和T中的非相同元素 |
实例:
>>> A={"p","y",123}
>>> B=set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '2', '1'}
>>> A&B
{'y', 'p'}
>>> A|B
{'y', '3', '1', 123, '2', 'p'}
>>> A^B
{'3', 123, '2', '1'}
2)集合处理方法
| 操作函数或方法 | 描述 |
| S.add(x) | 如果元素x不在集合S中,将x添加到S中 |
| S.discard(x) | 移除集合S中的元素x,如果S中没有x也不报错 |
| S.remove(x) | 移除集合S中的元素x,如果S中没有x则产生KeyErroe异常 |
| S.clear() | 移除集合S中的所有元素 |
| S.pop() | 提取集合S中的第一个元素,并在集合中删除该元素,如果S为空则产生KeyError异常 |
| S.copy() | 返回一个与集合S一样的副本 |
| len(S) | 返回集合S中的元素个数 |
| set(x) | 将其他类型变量x转换为集合类型 |
| x in S | 判断元素x是否在集合S中,如果存在则返回True,如果不存在则返回False |
| x not in S | 与x in S相反 |
注意:集合并不是完全无序,只是自己本身有着特殊的排序方式,并不一定会按照创建时给出元素顺序。例如:
>>> A={1,2,3,4,5}
>>> A
{1, 2, 3, 4, 5}
>>> A={1,"A",23,"BC"}
>>> A
{1, 'BC', 'A', 23}
>>> A.pop()
1
>>> A
{'BC', 'A', 23}
>>> A.add(1)
>>> A
{1, 'BC', 'A', 23}
3)集合类型应用场景
集合类型可以用来做包含关系的比较,例如:
>>> 'p' in {'p','y',123}
True
>>> {'p',123} <= {'p','y',123}
True
还可以做元素去重,也可以说是数据去重,例如:
>>> list1=['p','y','p','y',123]
>>> list1
['p', 'y', 'p', 'y', 123]
>>> S=set(list1)
>>> S
{'p', 123, 'y'}
>>> list1=list(S)
>>> list1
['p', 123, 'y']
(6).字典
了解字典首先要了解映射,映射是一种索引和数据的对应关系,也是一种键和值的对应关系,可以认为索引叫键,数据叫值。映射更多的是表达了某一个属性跟它对应的值,这种映射本身就是一种索引或一种属性与数据之间的对应关系。映射关系无处不在,例如:“姓名”与具体的姓名数据,“年龄”与具体的年龄数据。
字典类型是映射的体现,通过键值对来进行数据索引的扩展。字典是键值对的一种集合,在字典中,键值对之间是没有顺序的。
在Python中字典用{}表示,键值对之间用冒号(:)表示,元素之间用逗号分隔。创建一个字典需要使用{}或dict()函数,键值对之间用冒号(:)来表示。
例如:
>>> dic={"中国":"北京","美国":"华盛顿"}
>>> dic["中国"]
'北京'
>>> dic["日本"]="东京" #增加键值对
>>> dic
{'中国': '北京', '美国': '华盛顿', '日本': '东京'}
>>> dic["日本"]="无" #修改键值对
>>> dic
{'中国': '北京', '美国': '华盛顿', '日本': '无'}
>>> d={}
>>> d
{}
>>> type(d)
<class 'dict'>
注意:{}表示空字典,因为字典类型在计算机编程中更常用。
1)字典处理函数及方法
| 函数或方法 | 描述 |
| del d[k] | 删除字典d中键为k所对应的数据值 |
| k in d | 判断键值k是否在字典d中,如果在返回True,如果不在返回False |
| d.keys() | 返回字典d中所有的键信息 |
| d.values() | 返回字典d中所有的值信息 |
| d.items() | 返回字典d中所有的键值对信息 |
| d.get(k,<default>) | 在字典d中,如果键k存在,则返回对应的值,如果不存在,则返回<default> |
| d.pop(k,<default>) | 在字典d中,如果键k存在,则返回对应的值,如果不存在,则返回<default>。最后删除字典中相应的键值对 |
| d.popitem() | 随机从字典d中取出一个键值对,以元组形式返回,取出的键值对会从字典d中删除 |
| d.clear() | 删除字典d中的所有键值对 |
| len(d) | 返回字典d中元素的个数 |
实例:
>>> d={"中国":"北京","美国":"华盛顿","法国":"巴黎"}
>>> d.keys()
dict_keys(['中国', '美国', '法国'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎'])
>>> d.items()
dict_items([('中国', '北京'), ('美国', '华盛顿'), ('法国', '巴黎')])
>>> d.get("中国","伊斯兰堡")
'北京'
>>> d.get("巴基斯坦","伊斯兰堡")
'伊斯兰堡'
>>> len(d)
3
>>> d.popitem()
('法国', '巴黎')
>>> len(d)
2
2)字典类型应用场景
字典类型是映射的一种衍生形式,所以字典类型最主要的应用场景就是对映射的表达。字典的最主要作用是表达键值对数据,进而操作它们。
(7).扩展:删除变量
使用del [变量名]可以删除变量,最好不要出现与函数相同的变量名,否则容易报错。
>>> list={1,2,3,4}
>>> list((1,2,3)) #此时就会报错
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
list((1,2,3))
TypeError: 'set' object is not callable
>>> del list #删除这个变量
>>> list((1,2,3)) #删除之后又可以使用了
[1, 2, 3]
参考:https://www.cnblogs.com/aiwanbuhui/p/7766352.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号