

并查集笔记
并查集笔记
并查集,一种可以高效处理连通区块问题的数据结构,可以优化集合合并操作,判断集合是否连通
它的原理可以简单概括为:
设置一个数组,把每个元素的祖先节点存在数组中,当要查询这个节点所在集合时,通过层层向上,最终找到一个最远祖先
初始化祖先数组时,我们将每个元素的祖先都设置为他自己,当我们查询节点时,如果当前走到的节点的祖先就是他自己,那么他就是这个集合的最远祖先
合并集合时,我们只需要通过一次操作,查找这两个集合各自的最远祖先,然后对最远祖先进行操作,将其中一个的祖先指向另外一个(而不是指向自己),那么就完成区间的合并,这一步存在多种优化方案,如路径压缩,按秩合并等
这里以洛谷P3367为例
在进行操作前,我们首先要设计祖先数组,这个数组存储的是各个节点的祖先节点的位置
int fa[N];
然后对数组进行初始化操作
void init(int x) { for (int i = 0; i <= n; i++) fa[i] = i; }
遍历所有用得到的节点,将他们的祖先初始化为他们自己
构造查找函数,目的是返回这个元素的最远祖先
int find(int x) { return x == fa[x] ? x : find(fa[x]); }
使用递归写法,如果 x==fa[x] 说明已经走到了最远祖先的位置,那么就返回当前的 x ,如果不是,则继续查找 fa[x] 的祖先,即查找 x 的祖先的祖先,直到走到最远祖先的位置
merge 函数,目的是对两个集合进行合并操作
void merge(int i, int j) { i = find(i), j = find(j);//查找各自的最远祖先 if (i == j) return;//如果祖先相同,则无需操作 fa[i] = j;//将i的祖先指向j // fa[j] = i; 也可以 }
以上就是朴素的并查集写法,没有任何的优化
不难发现,如果的我们的数据量较大时,那么某个集合的边会变得十分长,从树状结构退化为一条链,大大增加了查找的时间复杂度
这里首先介绍一下路径压缩的优化方案
路径压缩,指的是将查找最远祖先的过程 从开始查找的节点到最远祖先节点的路径上的所有经过的节点,重新将他们的祖先节点指向最远祖先节点
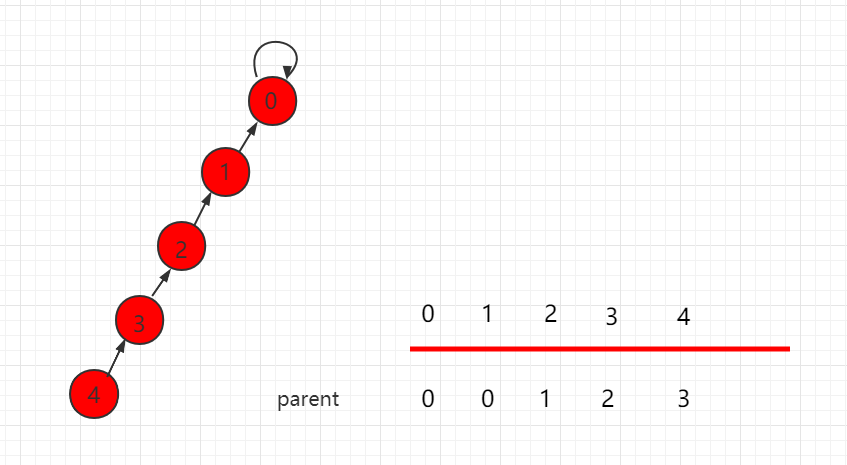
从初始的链结构变化为树结构
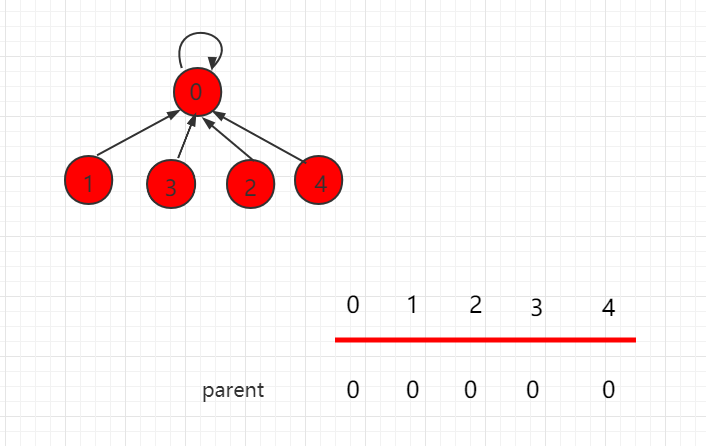
这个操作改变了并查集树的结构,具有不可逆性,但是时间复杂度非常优秀,能够做到在近似 \(O(1)\) 的时间内找到一个节点的祖先
代码的修改也十分简洁,只需要在原有查找函数的中间,进行祖先的重定向操作
int find(int x) { return fa[x] = x == fa[x] ? x : find(fa[x]); }
这一步把 fa[x] 赋值为 x 或 find(fa[x]) 即将路径上经过的点的祖先节点更改为他们的最远祖先节点
然后是按秩合并的优化方案
我们知道,并查集的操作就是对不同的树进行操作,每棵树都有其对应的高度
我们在合并两颗树时,合并后的树的高度不会超过合并前两个树的最大高度再加 \(1\) ,即:
\(h\_end<=max(h\_1,h\_2)+1\)
我们需要额外增加一个数组来存储各个节点的秩(当前节点的高度)
int rnk(N);
一开始,我们每个节点的秩都为 \(0\) ,所以将 rnk 开在全局变量里面即可
然后对合并操作进行改写,我们的目标肯定是降低合并后树的高度,树的高度越低,我们查找节点的祖先就越快
void merge(int i, int j) { i = find(i), j = find(j); if (i == j) return; if (rnk[i] > rnk[j]) swap(i, j); //这里保证 rnk[i] <= rnk[j] fa[i] = j; //将秩较小的集合合并到秩较大的集合上 if (rnk[i] == rnk[j]) rnk[j]++;//如果他们的秩相同的话,那么合并到的集合的秩就需要加1 }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具