02_多线程的实现方式
一、Thread类和Runnable接口
1.1、继承Thread类
package co.dianjiu.thread;
public class MyThread extends Thread{
@Override
public void run(){
System.out.println("MyThread");
}
public static void main(String[] args) {
new MyThread().start();
}
}
问:为什么调用start方法才算启动线程?
答:在程序里面调用了start()方法后,虚拟机会先为我们创建一个线程处于就绪状态,并没有运行,然后等到这个线程第一次得到时间片时,就会调用执行run()方法,run方法运行结束,此线程终止。
1.2、实现Runnable接口
package co.dianjiu.thread;
public class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println("MyRunnable");
}
public static void main(String[] args) {
//直接调用run方法执行
new MyRunnable().run();
//把自定义的实现runnable方法的类的实例丢到Thread的构造方法中,即可调用Thread类的start方法
new Thread(new MyRunnable()).start();
// Java 8 函数式编程,可以省略MyThread类
new Thread(()->{
System.out.println("匿名内部类");
}).start();
}
}
1.3、Thread类的常用方法
这里介绍一下Thread类的几个常用的方法:
- currentThread():静态方法,返回对当前正在执行的线程对象的引用;
- start():开始执行线程的方法,java虚拟机会调用线程内的run()方法;
- yield():yield在英语里有放弃的意思,同样,这里的yield()指的是当前线程愿意让出对当前处理器的占用。这里需要注意的是,就算当前线程调用了yield()方法,程序在调度的时候,也还有可能继续运行这个线程的;
- sleep():静态方法,使当前线程睡眠一段时间;
- join():使当前线程等待另一个线程执行完毕之后再继续执行,内部调用的是Object类的wait方法实现的;
1.4、Thread与Runnable的比较
实现一个自定义的线程类,可以有继承Thread类或者实现Runnable接口这两种方式,它们之间有什么优劣呢?
- 由于Java“单继承,多实现”的特性,Runnable接口使用起来比Thread更灵活。
- Runnable接口出现更符合面向对象,将线程单独进行对象的封装。
- Runnable接口出现,降低了线程对象和线程任务的耦合性。
- 如果使用线程时不需要使用Thread类的诸多方法,显然使用Runnable接口更为轻量。
所以,我们通常优先使用“实现Runnable接口”这种方式来自定义线程类。
二、Callable、Future与FutureTask
JDK提供了Callable接口与Future类为我们解决这个问题,这也是所谓的“异步”模型。
2.1、Callable接口
Callable一般是配合线程池工具ExecutorService来使用的。我们会在后续章节解释线程池的使用。这里只介绍ExecutorService可以使用submit方法来让一个Callable接口执行。(由于Alibaba代码规范中提到,线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,所以我也会提供使用ThreadPoolExecutor创建线程池,然后使用submit方法来让一个callable接口执行。)它们都会返回一个Future,我们后续的程序可以通过这个Future的get方法得到结果。
package co.dianjiu.thread;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class MyCallable implements Callable {
@Override
public String call() throws Exception {
return "MyCallable";
}
public static void main(String args[]) throws Exception {
//ExecutorService executor = Executors.newCachedThreadPool();
//MyCallable task = new MyCallable();
//Future<String> result = executor.submit(task);
// 注意调用get方法会阻塞当前线程,直到得到结果。
// 所以实际编码中建议使用可以设置超时时间的重载get方法。
//System.out.println(result.get());
/**
* 阿里巴巴Java开发手册中明确指出
* 【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,
* 这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
* 说明:Executors各个方法的弊端:
* 1)newFixedThreadPool和newSingleThreadExecutor:
* 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
* 2)newCachedThreadPool和newScheduledThreadPool:
* 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
*/
ExecutorService pool = new ThreadPoolExecutor(5, 200,
30, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1024), new ThreadPoolExecutor.AbortPolicy());
MyCallable task = new MyCallable();
Future result = pool.submit(task);
System.out.println(result.get());
}
}
ThreadPoolExecutor参数的初步解释
使用ThreadPoolExecutor创建线程池
参数1:corePoolSize 核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
参数2:maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
参数3:keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
参数4:unit:参数keepAliveTime的时间单位,有7种取值。TimeUnit.DAYS、TimeUnit.HOURS、TimeUnit.MINUTES、TimeUnit.SECONDS、TimeUnit.MILLISECONDS、TimeUnit.MICROSECONDS、TimeUnit.NANOSECONDS
参数5:workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue。ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
参数6:threadFactory:线程工厂,主要用来创建线程**(上面和下面都省略了这个参数)**
参数7:handler:表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
2.2、Future接口
package java.util.concurrent;
public interface Future<V> {
/**
* 尝试取消执行此任务。 如果任务已经完成,已经被取消或由于某些其他原因而无法取消,则此尝试将失败。
* 如果成功,并且在调用cancel时此任务尚未开始,则此任务永远不会运行。
* 如果任务已经启动,则mayInterruptIfRunning参数确定是否应中断执行该任务的线程以尝试停止该任务。
* 此方法返回后,对isDone后续调用将始终返回true 。
* 对后续调用isCancelled总是返回true ,如果这个方法返回true 。
* 参数:mayInterruptIfRunning –如果应该中断执行此任务的线程,则为true否则为true 。
* 否则,正在进行的任务将被允许完成
* 返回值:如果无法取消任务,则返回false ,通常是因为它已经正常完成了; 否则为true
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
*如果此任务在正常完成之前被取消,则返回true
*/
boolean isCancelled();
/**
* 如果此任务完成,则返回true 。
* 完成可能是由于正常终止,异常或取消引起的,在所有这些情况下,此方法都将返回true 。
*/
boolean isDone();
/**
* 必要时等待计算完成,然后检索其结果。
* 返回值:计算结果
*/
V get() throws InterruptedException, ExecutionException;
/**
* 必要时最多等待给定时间以完成计算,然后检索其结果(如果有)。
* 参数:超时–等待的最长时间 unit –超时参数的时间单位
* 返回值:计算结果
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
2.3、FutureTask类
package co.dianjiu.thread;
import java.util.concurrent.*;
public class MyFutureTask implements Callable {
@Override
public String call() throws Exception {
return "MyFutureTask";
}
public static void main(String args[]) throws Exception {
//ExecutorService executor = Executors.newCachedThreadPool();
//FutureTask<String> futureTask = new FutureTask<>(new MyFutureTask());
//executor.submit(futureTask);
//System.out.println(futureTask.get());
/**
* 阿里巴巴Java开发手册中明确指出
* 【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,
* 这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
* 说明:Executors各个方法的弊端:
* 1)newFixedThreadPool和newSingleThreadExecutor:
* 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
* 2)newCachedThreadPool和newScheduledThreadPool:
* 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
*/
ExecutorService pool = new ThreadPoolExecutor(5, 200,
30, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1024), new ThreadPoolExecutor.AbortPolicy());
FutureTask<String> futureTask = new FutureTask<>(new MyFutureTask());
pool.submit(futureTask);
System.out.println(futureTask.get());
}
}
一起跟一下源码
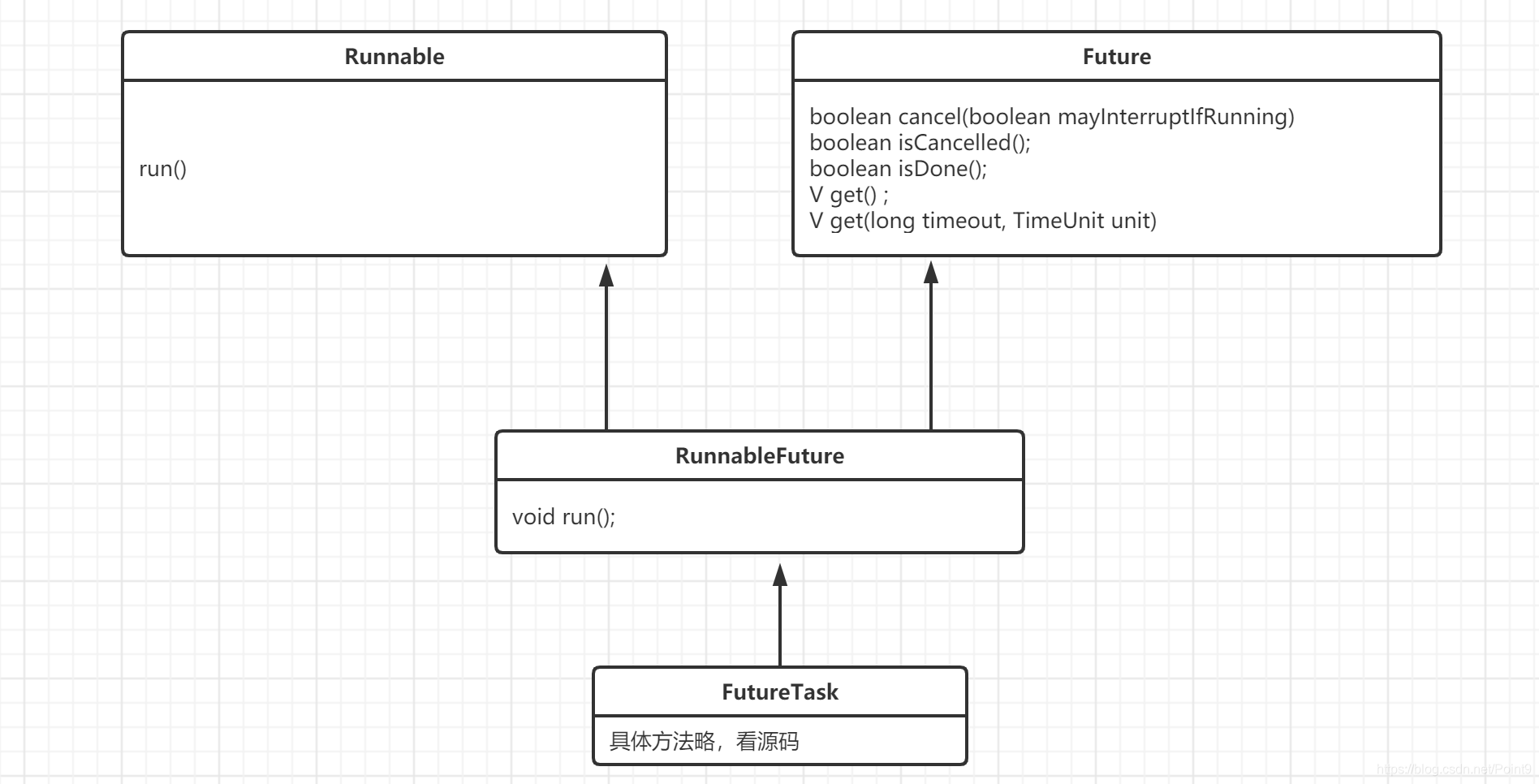
由上图FutureTask UML 类图可知,FutureTask是实现的RunnableFuture接口的,而RunnableFuture接口同时继承了Runnable接口和Future接口。所以JDK提供了一个FutureTask类实现了Future中cancel,get,isDone等方法来供我们使用。
2.4、FutureTask的几个状态
此任务的运行状态,最初为NEW。 运行状态仅在set,setException和cancel方法中转换为终端状态。 在完成期间,状态可能会采用COMPLETING(正在设置结果时)或INTERRUPTING(仅在中断跑步者满足cancel(true)时)的瞬态值。 从这些中间状态到最终状态的转换使用便宜的有序/惰性写入,因为值是唯一的,无法进一步修改。 可能的状态转换:新->完成->正常新->完成->例外新->取消新->中断->中断
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;


