hadoop电信用户行为分析
1.环境配置
先对每台服务器(虚拟机)进行环境配置 虚拟机:CentOS-7-x86_64-Minimal-1810
centOS7系统出现以下错误
ifconfig命令报错: ifconfig bash:ifconfig commend not found
显示没有这个指令:安装该指令 yum -y install net-tools
注意一点:使用SecurtCRT连接阿里云服务器你需要用公网(注意)
1.修改相关虚拟机网络信息
/etc/sysconfig/network-scripts
修改三台机器ip地址
1 ONBOOT="yes" # 设置为yes, 表示开机启动 2 IPADDR="192.168." # ip地址 3 PREFIX="24" # 子网掩码 4 GATEWAY="192.168." # 网关 5 DNS1="114.114.115.115" # DNS
2.修改三台主机名:/etc/hostname(目录) 将localhost.localdomain改成hadoop01;其他两台虚拟机依次改为hadoop02 hadoop03


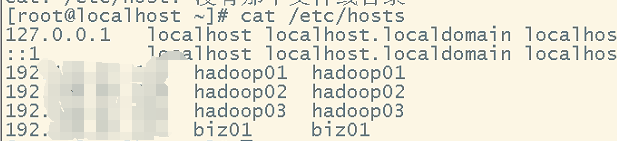
修改三台主机映射:/etc/hosts
涉及相关Linux指令:
你每次需要改的的时候都要在最后一行最后一个非空字符这个时候需要知道一个指令:“G+$" 即(shift+g shift+4)
关闭防火墙和警用防火墙
1.关闭防火墙 systemctl stop firewalld.service
2.禁用防火墙 systemctl disable firewalld.service
修改一个文件 vi /etc/selinux/config SELINUX=disble
设置免密码登录 ssh-keygen生成密钥(公钥和私钥)
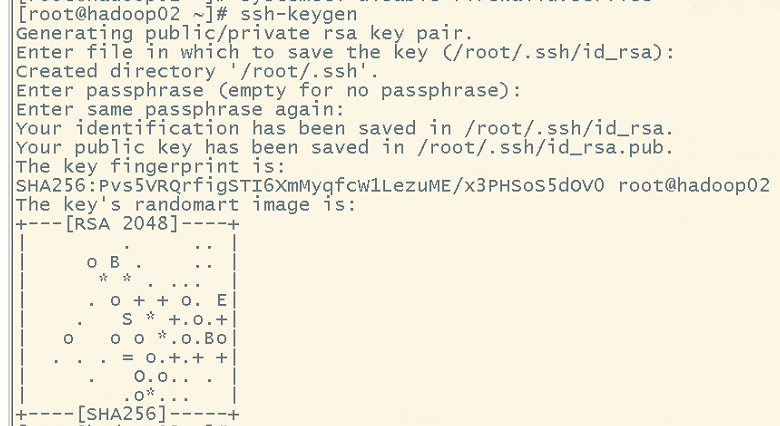
拷贝给其他的主机:ssh-copy-id 主机名字
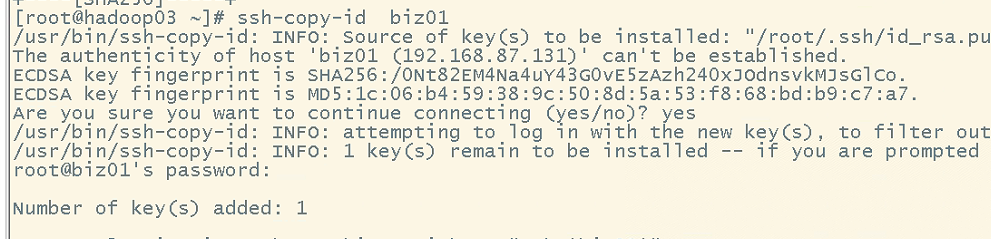
分别发送给其他主机,自己也要保留一份。随后进行所有会话验证。
配置服务器结点时钟同步
在所有节点安装ntpdate:yum install -y ntpdate
增加定时任务:
yum install -y vim
yum install -y net-tools
yum install -y lrzsz
yum install -y rsync
yum install -y wget
创建同意目录
mkdir -p /bigdata/{soft,server}
/bigdata/soft 安装文件的存放目录
/bigdata/server 软件安装的目录
2.同步数据脚本
mkdir /root/bin cd /root/bin vim xsync #!/bin/bash #1 获取命令输入参数的个数,如果个数为0,直接退出命令 paramnum=$# echo "paramnum:$paramnum" if (( paramnum == 0 )); then echo no params; exit; fi # 2 根据传入参数获取文件名称 p1=$1 file_name=`basename $p1` echo fname=$file_name #3 获取输入参数的绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取用户名称 user=`whoami` #5 循环执行rsync current=`hostname` nodes=$(cat /root/bin/works) for host in $nodes; do echo ------------------- $host -------------- if [ "$host" != "$current" ];then rsync -rvl $pdir/$file_name $user@$host:$pdir fi done
同时在workers
1 cd /root/bin 2 3 vi workers 4 5 hadoop01 6 hadoop02 7 hadoop03
设置文件权限:
chmod u+x /root/bin/xsync
配置上述文件后,就能够实现三台服务器文件同步。
3.安装软件
1.安装jdk
tar -zxvf /bigdata/soft/jdk-8u241-linux-x64.tar.gz -C /bigdata/server/ ln -s jdk1.8.0_241/ jdk1.8 vi /etc/profile.d/custom_env.sh export JAVA_HOME=/bigdata/server/jdk1.8 export PATH=$JAVA_HOME/bin:$PATH source /etc/profile
# 同步到biz01, hadoop01, hadoop02, hadoop03
xsync /etc/profile/custom_env.sh
xsync /bigdata/server/jdk1.8.0_241
xsync /bigdata/server/jdk1.8
scp -r /etc/profile/custom_env.sh biz01:/etc/profile/custom_env.sh
scp -r /bigdata/server/jdk1.8.0_241 biz01:/bigdata/server/jdk1.8.0_241
在biz01 创建软链接
ln -s jdk1.8.0_241/ jdk1.8

2.安装mysql
## 查询MySQL相关的依赖 rpm -qa |grep mysql ## 如果存在, 则通过rpm -e --nodeps 进行卸载 wget https://dev.mysql.com/get/mysql80-community-release-el7-6.noarch.rpm rpm -ivh mysql80-community-release-el7-6.noarch.rpm cd /etc/yum.repos.d/ mysql-community.repo: 用于指定下载哪个版本的安装包 mysql-community-source.repo: 用于指定下载哪个版本的源码 ## 导入签名的信息key rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 ## 安装5.7 yum install -y mysql-community-server systemctl start mysqld systemctl status mysqld systemctl enable mysqld ## 查看初始密码 less /var/log/mysqld.log |grep pass set global validate_password_length=4; set global validate_password_policy=0; ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; #创建一个远程登录用户 create user 'root'@'%' identified by '123456'; ## 设置远程登录权限 grant all privileges on *.* to 'root'@'%'; vi /etc/my.cnf ## 在mysqld下面设置 character_set_server=utf8 ## 重启服务 systemctl restart mysqld
3.搭建集群环境
搭建集群环境 hadoop01 hdoop02 hadoop03 布置如图所示
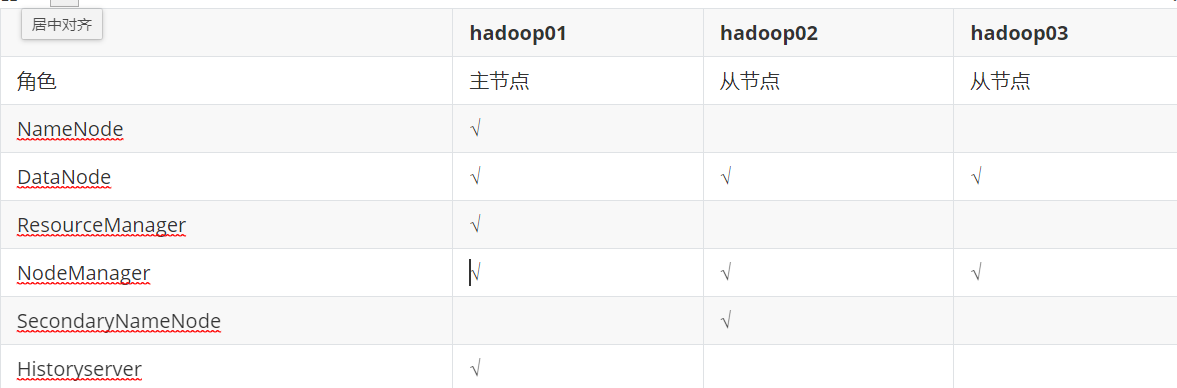
上传文件及解压
tar -zxvf /bigdata/soft/hadoop-3.3.3.tar.gz -C /bigdata/server/
创建软连接
cd /bigdata/server
ln -s hadoop-3.3.3/ hadoop
Hadoop配置文件修改
hadoop-env.sh vim hadoop-env.sh 54行的JAVA_HOME的设置 export JAVA_HOME=/bigdata/server/jdk1.8 在文件末尾添加如下内容 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/bigdata/data/hadoop</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
hdfs-site.xml
<!-- 指定secondarynamenode运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
yarn-site.xml <!-- 指定YARN的主角色(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop01:19888/jobhistory/logs</value> </property> <!-- 保存的时间7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
cd /bigdata/server/hadoop/etc/hadoop/
vim workers
hadoop01
hadoop02
hadoop03
配置环境变量 vim /etc/profile.d/custome_env.sh export HADOOP_HOME=/bigdata/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profilehadoop启动hadoop namenode -format
在`主节点hadoop01`启动namenode cd /bigdata/server/hadoop/bin ./hdfs --daemon start namenode 在`hadoop02`启动secondarynamenode cd /bigdata/server/hadoop/bin ./hdfs --daemon start secondarynamenode 在`所有节点`启动datanode cd /bigdata/server/hadoop/bin ./hdfs --daemon start datanode 查看进程情况 netstat -ntlp 其中hdfs的web端口: hadoop01:9870已经可以正常访问 在`主节点hadoop01`启动ResouceManager cd /bigdata/server/hadoop/bin ./yarn --daemon start resourcemanager 在`所有节点`启动Nodemanager cd /bigdata/server/hadoop/bin
./yarn --daemon start nodemanager
效果图如图所示
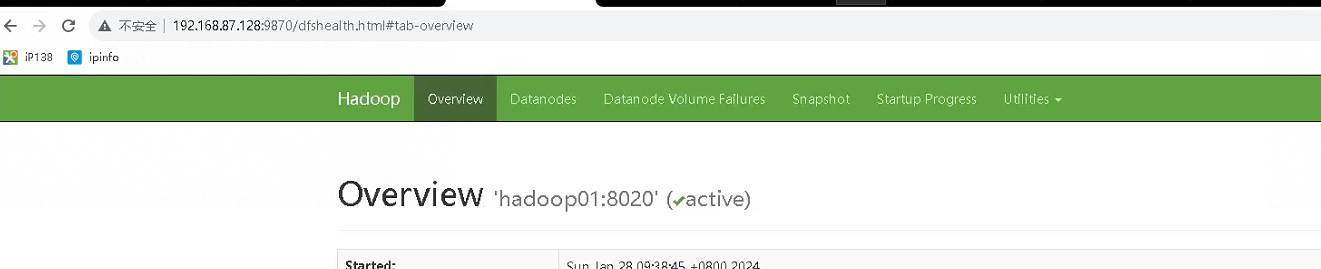
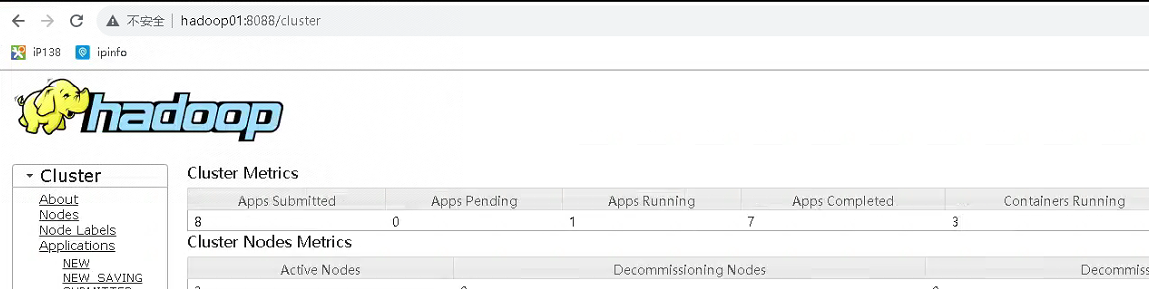
记录历史信息
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>
中间省略()
最后可视化效果:
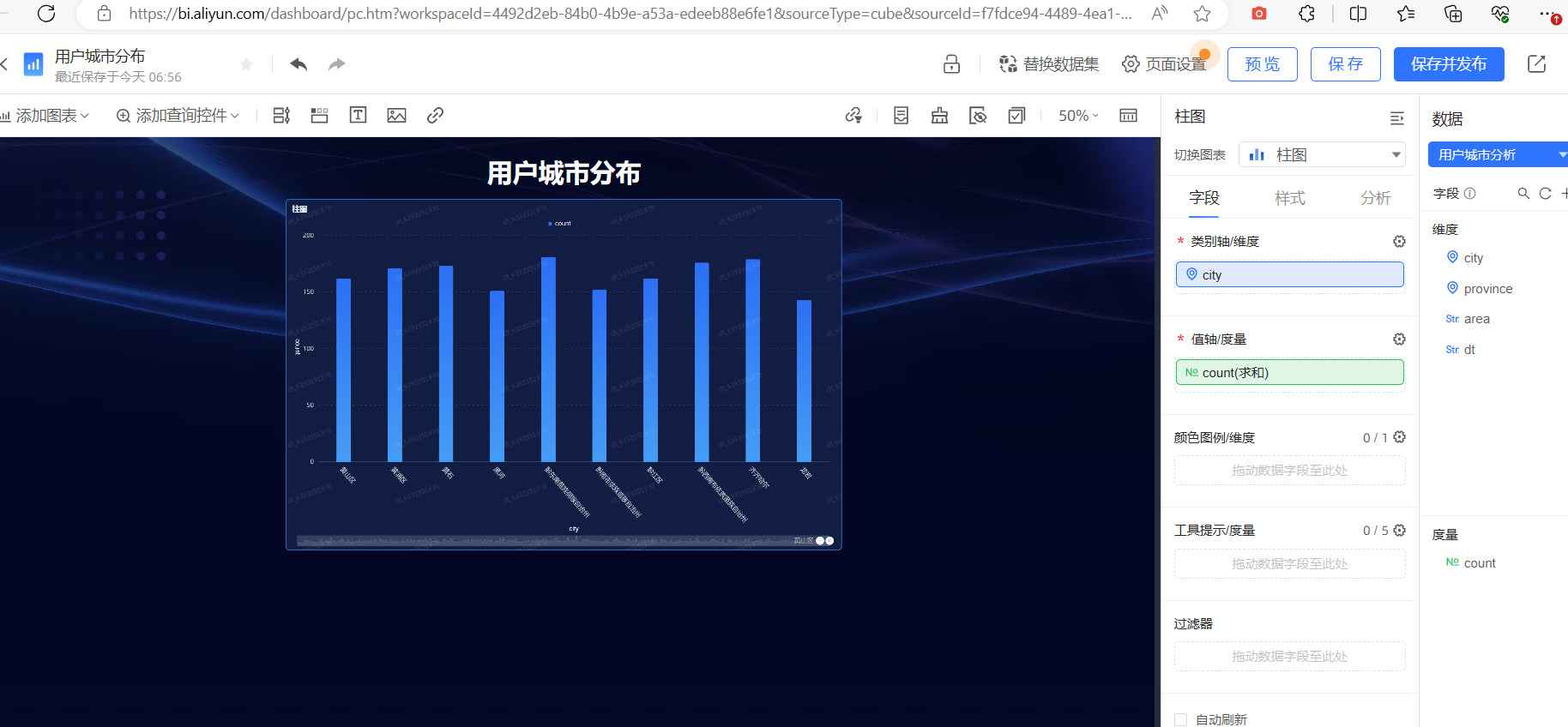
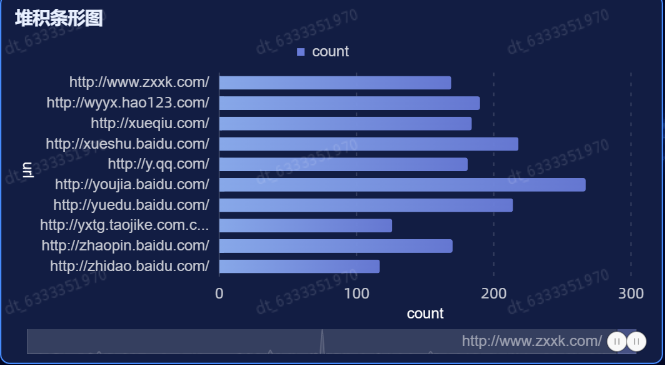
1.报错
解决Hadoop Browse Directory Couldn‘t upload the file 错误.无法上传文件
直接 hadoop fs -put 文件 路径

 浙公网安备 33010602011771号
浙公网安备 33010602011771号