hadoop集群 大数据项目实战_电信用户行为分析_day01
上图是相关配置的要求,主要创建了四个虚拟系统,有三台虚拟机搭建hadoop集群,一台作为业务系统。
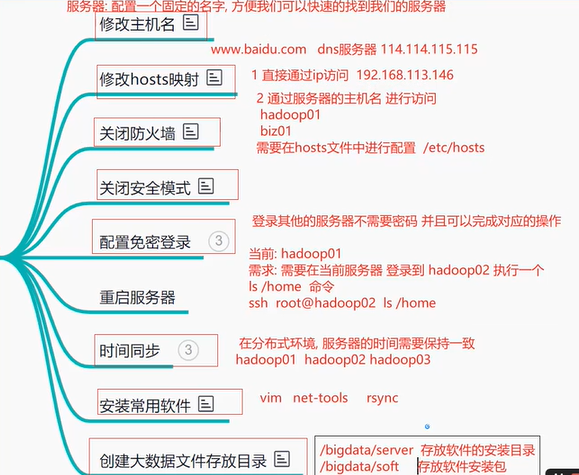
涉及到相关的Linux指令有::set nu[显示行号] :6[到第6行 shift+G跳到最后一行 进入vi指令后查找相关东西/(你需要查找的东西)
1.配置环境、
第一步设置网络参数,设置静态网络
目录:/etc/sysconfig/network-scripts 访问文件名字:ifcfgens33

其中ONBOOT='yes',表示启动这块网卡 BOOTPROTO=static,表示静态路由协议,可以保持IP固定 GATEWAY:表示虚拟网关,通常都是将IP地址最后一个位数变成了2 PREFIX:24用来表示子网掩码,前面右24个1,1个0
第二步设置主机名和IP映射配置 一台主机mask 另外两台分别是子机
设置三台主机名和IP地址相关映射
 [root@node03 ~]# cat /etc/hosts
[root@node03 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.77.138 node01
192.168.77.139 node02
192.168.77.140 node03
第三步设置SSH免密登录功能配置
1.每台机子生成公钥和密钥
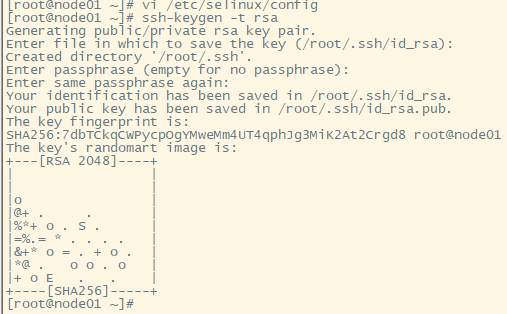
上述代码生成了密钥和公钥
2.把每台的公钥传给另外几台机子
ssh-copy-id 机子
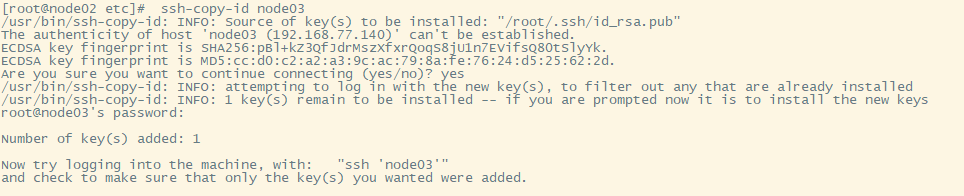
3.配置通过不操作
一种方式:yum install -y rsync
一种通过脚本进行编写:脚本名字xsync
1.上传jdk包: tar -zxvf jdk-8u241-linux-x64.tar.gz -C /bigdata/server/
2.修改名字:mv jdk1.8.0_241/ jdk
3.配置环境:

4.激活环境
source /etc/profile
5.配置hadoop环境
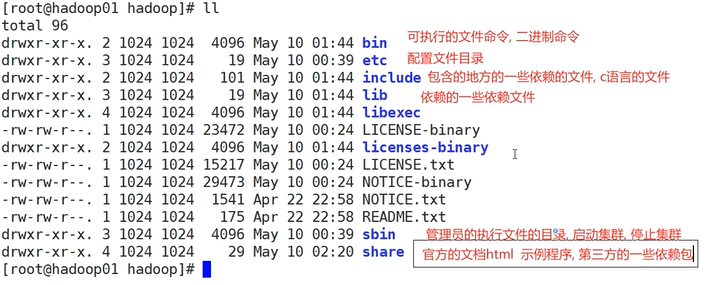
hadoop相关文件介绍如上所示,目前用到的是etc配置文件目录

上述是对hadoop和java配置环境

6.配置mysl环境
首先检查有没有安装过mysql环境,主要业务系统安装mysql

下载数据库
wget https://dev.mysql.com/get/mysql80-community-release-el7-6.noarch.rpm

就是使用mysql 5,.7版本不使用8.0版本

重点:集群配置

所有配置文件均在:/bigdata/server/hadoop-3.3.3/etc

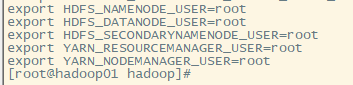
1.配置hadoop-env.sh

2.核心配置文件:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/data/hadoop</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>
</configuration>
4.配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->RN的主角色(ResourceManager)的地址 -->
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认
值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
5.配置hdfs-site.xml
<configuration>
<!-- 指定secondarynamenode运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>
最后使用start-dfs.sh和start-yarn.sh启动所有分布式服务系统,最后结果为:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号