
15-445(2021) PROJECT #1 - BUFFER POOL
这个实验的目的是要为Bustub设计一个缓存管理器BufferPoolManagerInstance来管理数据库的缓存池,还要实现多个缓存池的并行操作。之前写6.S081的时候实现过一个Buffer Node Layer,用来管理操作系统缓存在内存中的inode,和这个BufferPoolManager的功能还是很相似的。按照课程要求,这里就不公开作业代码了,以分析框架代码和解题思路为主。
TASK #1 - LRU REPLACEMENT POLICY
1.分析
第一个任务是实现LRU算法。这里LRU的用途是管理空闲的frame。如果某个frame正在被使用,则它不应该出现在LRU中。只有确认过没有线程正在使用它的时候才可以把它放入LRU里。先简单总结一下在机考题中遇到LRU的实现方法:
step1. 创建一个双向链表。
step2. put(k,v):把新进来的项k插入链表头。查询链表,如果这个项已经在链表里面了,需要更新其值v,并把它移到链表头部。如果缓存已经满了,就移除链表尾部的元素。
step3. get(k):如果需要从LRU缓存访问一个项k,就把这个项移到链表头。
但是本实验里需要实现的和上述LRU不太一样。来看三个方法:
1.Victim():要求直接从LRU缓存里取出一个空闲的frame。因此很简单,只需要取出链表的最后一个元素就可以了。
2.Pin():按照教材所述,如果一个frame在被某些线程使用就需要Pin()一下。被使用就说明这个frame不能拿来分配。因此Pin()的作用是把指定的frame从缓存里直接删除,不让这个frame出现在LRU缓存里。
3.Unpin():如果frame被最后一个使用它的线程释放,就意味着它可以拿来分配了,就应该调用Unpin()把它重新放回LRU缓存。
这里需要注意的一点:frame都是独一无二的。如果要把某一个frame从LRU里删除,执行一次Pin()就可以了。如果要执行多次Pin(),就意味着要把同一个frame从LRU缓存里删除多次,这显然不合理。同理,如果要把某一个frame加入LRU,执行一次Unpin()就可以了,不可能多次把同一个frame加入到LRU中。如果对已经加入LRU的frame执行Unpin(),不能把它移动到链表头部。
2.实现
接下来是这三个方法的实现思路。
首先是数据结构。创建一个双向链表,在C++里建议直接使用std::list,自己写双向链表容易出现不可知的错误。链表的查询代价是非常大的,因此可以引入一个hash表来实现链表的O(1)查询,注意hash表的增删改查一定要和链表同步。创建的数据结构如下:
std::list<frame_id_t> lru_list_;
std::unordered_map<frame_id_t, std::list<frame_id_t>::iterator> lru_map_;
size_t max_num_;
std::mutex mtx_;创建一个frame_id_t类型的链表,里面存储空闲的frame。然后创建hash表,从frame id直接映射到链表的节点,这个节点的类型是一个迭代器std::list<frame_id_t>::iterator。mtx_是互斥锁。
(1)Victim()
step1. 先加锁,这里建议使用std::lock_guard,它会随着函数返回而自动析构,用它就不用纠结lock()和unlock()d的对应关系了。
step2. 然后先检查LRU是否已经空,如果空了就不用再执行了。
step3. 弹出lru_list_尾部的frame id,把lru_map_中frame id对应的项删除,返回true,把得到的frame id赋值给传入的引用参数。
(2)Pin()
step1. 还是先加锁。
step2. 先判空,如果LRU已经空了,就没什么可以Pin的了,直接返回。
step3. 使用hash表查询frame_id对应的链表节点(“节点”就是std::list<frame_id_t>::iterator类型的迭代器)。如果没找到,就说明这个frame不是空闲的,什么都不做。如果找到了,就先给lru_list_.erase()传入得到的迭代器,删除链表里的此项,然后删除hash表中frame_id对应的项。
(3)Unpin()
step1. 加锁。
step2. 如果LRU缓存满了,则直接返回。
step3. 使用hash表查询frame_id对应的链表节点,如果找到了就什么都不用做。如果没找到,就把它插入链表头部,然后把<frame_id, 链表头部的迭代器>这一对插入hash表。
(4) Size()
返回lru_map_.size()。因为hash表的size()操作是O(1)的,而list的size()是O(N)的。
TASK #2 - BUFFER POOL MANAGER INSTANCE
1.buffer pool做了什么
buffer pool是数据页在内存里的缓冲,BufferPoolManagerInstance就负责管理数据页在buffer pool和磁盘之间的来往。我们这个实验的目的就是编写Bustub操作数据页的几个方法。
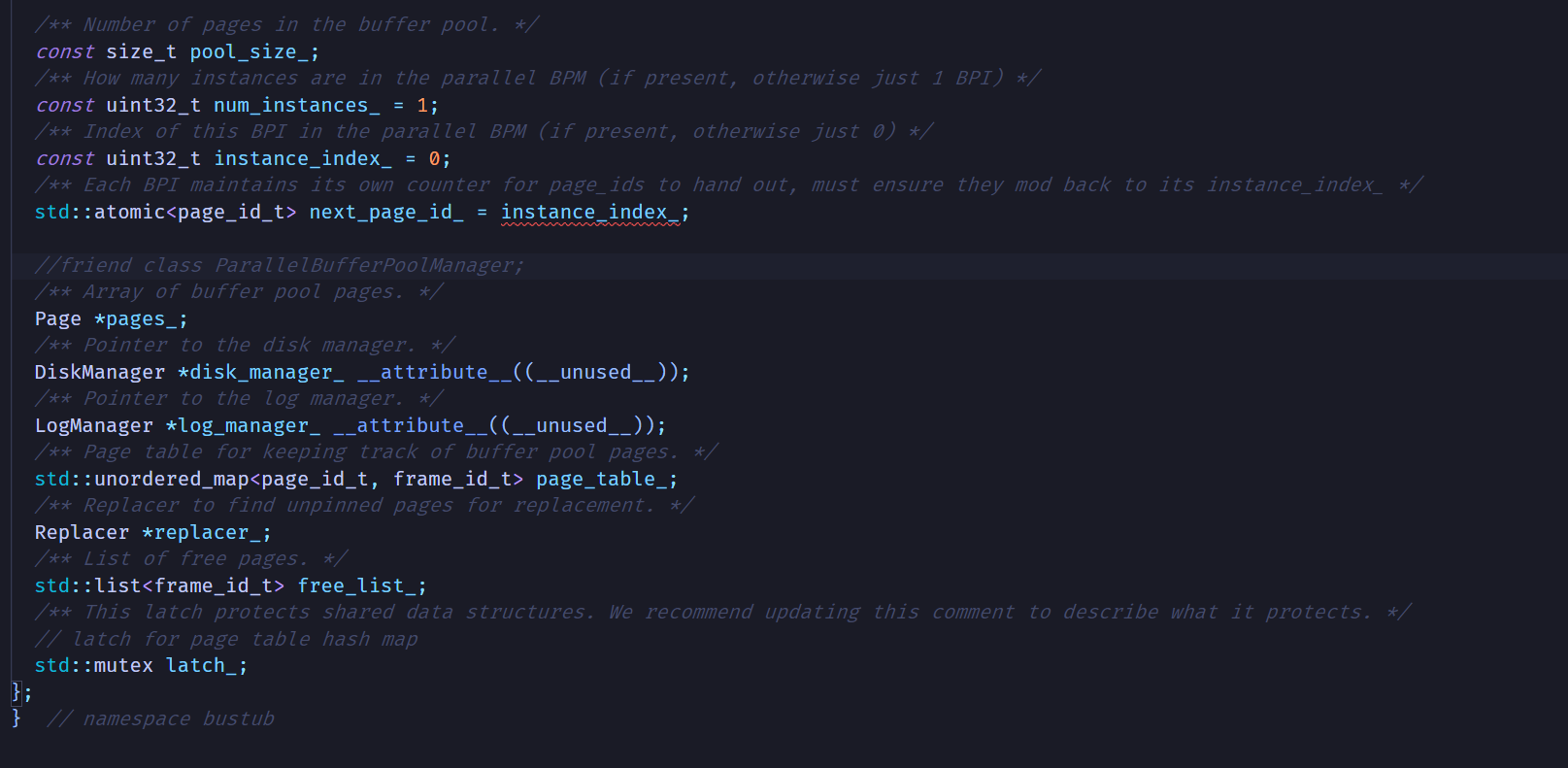
先看BufferPoolManagerInstance这个类的私有成员:
再看构造函数:
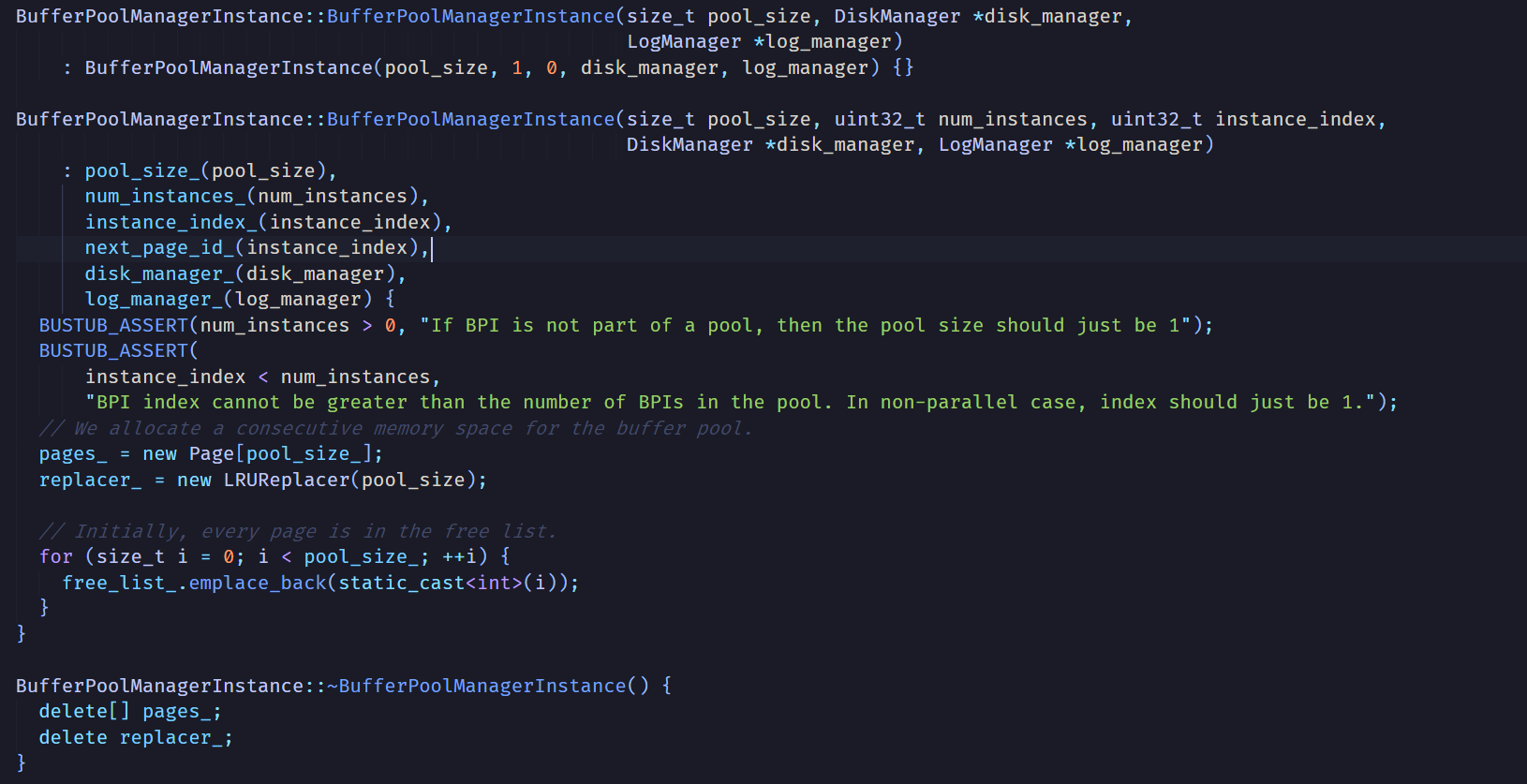
这里在堆上创建了一个Page类型的,大小为pool_size_的数组,以及一个LRUReplacer类。另外,还传入了一个DiskManager类和一个LogManager类的指针。很明显,pages_就是所谓的buffer pool了,它的Pages元素就是所谓的“frame”,数据页就存储在Page对象之中。Page除了数据以外,还有一些is_dirty_等参数,详细可以看page.h。
free_list_里存储的是空闲页在pages_里的下标,这个下标的类型是frame_id_t的,这个类型本质上是int32_t整数。初始化的时候,整个buffer pool都是空闲的,所以构造函数就把0 ~ pool_size_-1所有的下标都加入到free_list当中。
注意到page_table_是一个从page_id_t 到 frame_id_t的映射,根据buffer pool的定义,它存储的是从磁盘数据页到内存数据页的映射。那么page_id_t指的应该就是磁盘中的数据页了。观察我们马上要实现的方法,大多都要传入一个page_id_t类型的参数,比如下面这个
/**
* Flushes the target page to disk.
* @param page_id id of page to be flushed, cannot be INVALID_PAGE_ID
* @return false if the page could not be found in the page table, true otherwise
*/
bool FlushPgImp(page_id_t page_id) override;就要求传入一个page_id,根据这个page_id就能把它从buffer pool写回到磁盘上的位置。那么page_id是从哪里来的呢?
观察buffer_pool_manager_instance.cpp里面方法NewPgImp的实现,里面有这么一行注释:
// 0. Make sure you call AllocatePage!
NewPgImp()方法的功能是在buffer pool里为一个新数据页分配一个位置。它接受一个page_id_t类型的引用,返回分配的Page*指针,并把分配给数据页的page_id存储在引用中。
也就是说一个数据页的page_id是在NewPgImp()中由AllocatePage()方法确定的。接下来的问题是:page_id到底和磁盘有什么关系?还是在buffer_pool_manager_instance.cpp里,发现FlushPgImp()的实现中有一行注释:
// Make sure you call DiskManager::WritePage!
构造函数中传入的DiskManager*指针有用了,那么DiskManager::WritePage是做什么的呢?
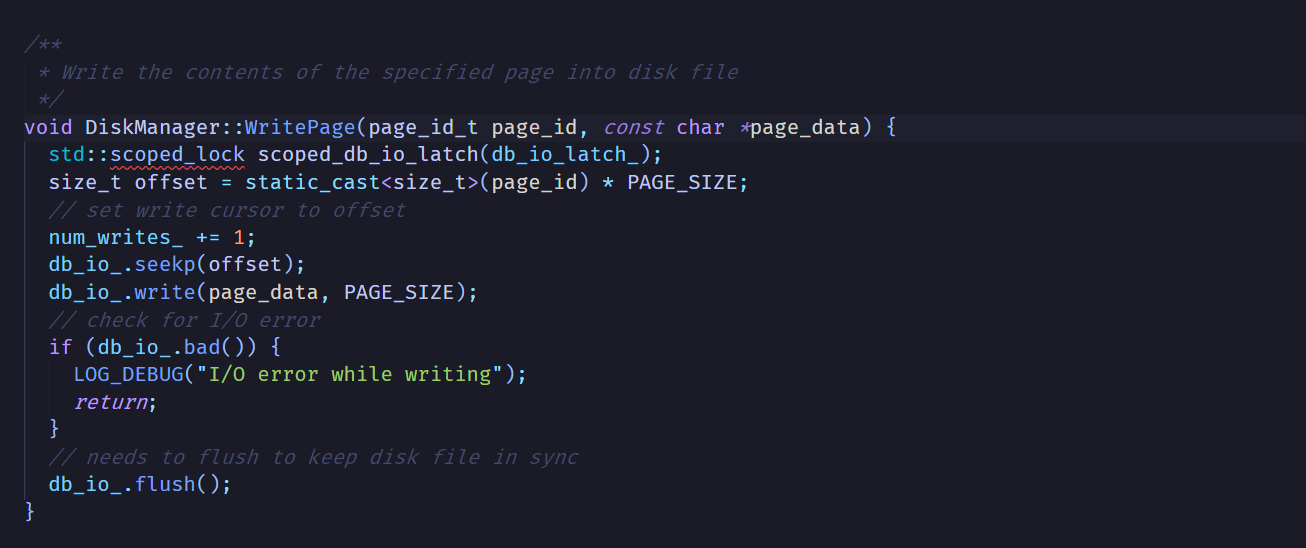
这里的实现出乎意料的简单。现在就很清楚了:
WritePage使用了一个std::fstream的对象db_io_来写入数据库文件。page_id就是数据页在数据库文件里面的相对位置。写入某一页的时候,先使用PAGE_SIZE乘以page_id得到此页在文件里的偏移量,然后使用seekp()把流指针移动到此位置,最后调用write()写入一整页。
总结下来,buffer pool和磁盘文件的关系是:
-
BufferPoolManagerInstance为一个数据页分配在buffer pool和磁盘文件里的位置。前者的类型是frame_id_t,是在pool_size_数组中的下标;后者的类型是page_id_t,是在磁盘文件里的偏移量。
-
使用时,通过frame id来访问一个数据页在buffer pool中的分身,通过page_id访问它在磁盘文件中的分身。
-
page_table_这个哈希表存储了磁盘文件到buffer pool frame的映射。
另外注意一下,本实验中不用实现DeallocatePage方法。
2.实现
每个方法的开头都有注释说明实现的思路,所以这里就写一下实现的细节:
-
为了实现线程安全,每个方法都要加锁。因为page_table_,pages_和free_list_都是线程间共享的数据结构,所以直接在方法开头使用lock_guard加锁即可。
-
几个地方需要修改pin count:
-
NewPgImp中,当需要从LRU缓存里获取frame时,需要Pin()一下这个frame并把它的pin count+1。
-
FetchPgImp中,无论是成功搜索到frame还是获取一个新frame,都需要Pin()以及pin count+1。
-
调用UnpinPgImp时,需要把frame的pin count-1。UnpinPgImp不能删除frame。当且仅当pin count降到0时使用Unpin()。
-
-
UnpinPgImp的要求“@param is_dirty true if the page should be marked as dirty, false otherwise”,要写成:
if (is_dirty) { unp_page->is_dirty_ = true; }这才是正确的逻辑,千万不要直接把is_dirty赋给unp_page->is_dirty_。
-
NewPgImp中,务必要在完成frame是否能够分配的检查之后才能使用AllocatePage()分配page_id!否则无法通过task3的测试。
TASK #3 - PARALLEL BUFFER POOL MANAGER
这个task是要并行使用多个buffer pool。思路是:在ParallelBufferPoolManager中创建多个BufferPoolManagerInstance类,构成一个有序表。当一个数据页需要被写入buffer pool时,就使用一个哈希函数,以page_id为key,把它映射到某一个BufferPoolManagerInstance上面。
本实验使用的就是最简单的page_id mod num_instances函数。
这时BufferPoolManagerInstance里面的两个参数num_instances_和instance_index_就派上用场了。
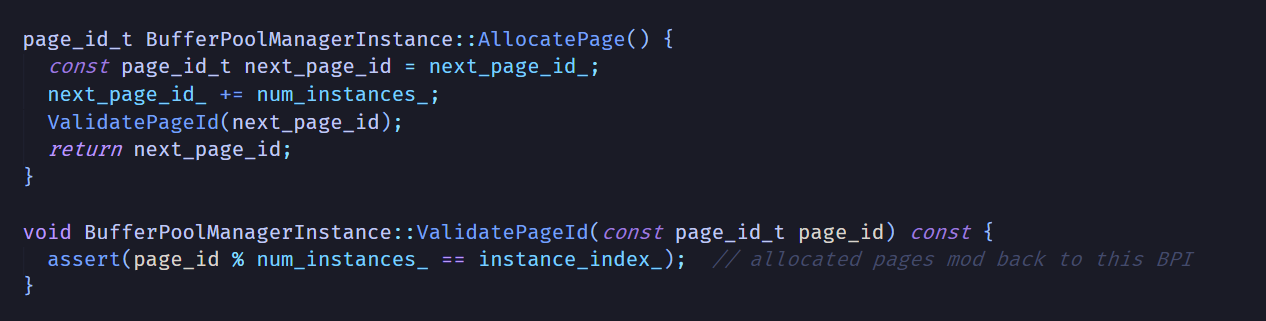
不难发现,这两个参数是用来确保哈希函数的正确性的。某个BufferPoolManagerInstance产生了一个page id,那么把page id带入哈希函数计算之后,就一定会得到这个BufferPoolManagerInstance在有序表里的下标。
这个task实现起来还是很容易的,基本就是两行代码:1. 使用传入的page id,计算它属于哪个BufferPoolManagerInstance;2. 调用对应BufferPoolManagerInstance的方法处理它。每个page id都对应唯一的BufferPoolManagerInstance,所以Instance之间不会竞争磁盘文件,不用上锁。
这里还要注意一下,BufferPoolManagerInstance和ParallelBufferPoolManager都是BufferPoolManager的派生类,所以在前者里是不能直接使用后者的方法的,只能使用父类BufferPoolManager里面的public方法。
最后提交Gradescope测试,测试比较慢,耐心等待一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号