
MIT 6.S081 2021: Lab Lock
Memory allocator
xv6是使用linked list来管理空余内存块,我们先看一下kalloc.c究竟是怎么工作的:
首先是2个结构体,匿名结构体kmem就是我们访问空余内存的凭据了,kmem里面有一个自旋锁和一个链表头部指针。struct run显然就是链表结构,里面唯一的成员就是指向下一个空余物理页面的指针。kinit做的操作是初始化自旋锁,然后把从内核尾部地址到PHYSTOP的物理内存全部kfree()一遍。
kfree()的作用是:传给它一个指针,它释放该指针指向的一页内存pa。释放方式是:先使用memset把pa里面的内容全部置为1,然后把pa插入freelist的头部。kalloc()的作用是:分配freelist直接指向的页。分配方式是:直接返回freelist的值,然后让freelist指向下一个空闲的页。这就是kalloc.c管理空闲页的过程。在系统boot的时候,CPU0会调用kinit()分配所有内存,得到一个串接起内存中所有可以页的链表。
现在我们要优化这一过程。当多个CPU都需要分配内存时,为了防止race condition,它们在申请新页表的时候都要获取kmem中的自旋锁lock,任何时候只能有一个CPU申请内存。然而自旋锁执行的是busy waiting,非常耗费CPU资源,所以可以为每个CPU设置一个专属的free list,这样多个CPU之间就不需要争夺一个自旋锁了。
为每个CPU设计一个struct memnode,结构成员仿照之前的kmem,有一个自旋锁和一个链表头。初始化一个struct memnode类型的数组cpu_mem,CPU可以按照自己的hart id在cpu_mem里找到自己的free list。
struct memnode{
struct spinlock lock;
struct run *freelist;
};
//初始化一个struct memnode类型的数组
struct memnode cpu_mem[NCPU];现在修改kinit():
void
kinit()
{
//这里应当多次调用,初始化每个CPU的锁
//TODO
//char name[20];
for(int i=0;i<NCPU;i++)
{
//snprintf(name,15,"kmem");
initlock(&cpu_mem[i].lock, "kmem");
//memset(name,0,20);
}
//initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}初始化所有锁,按照提示,锁的名称就用kmem。取别的名字的话auto grade程序可能识别不了。
然后修改kfree()。理所当然的,使用cpuid()获取CPU的hart id,获取现有CPU专属的锁,然后把空页插入此CPU的freelist头部。
void
kfree(void *pa)
{
struct run *r;
push_off();//记得关中断
int this_cpu = cpuid();
pop_off();
//printf("cpu %d free %p\n",this_cpu,pa);
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&cpu_mem[this_cpu].lock);
r->next = cpu_mem[this_cpu].freelist;
cpu_mem[this_cpu].freelist = r;
release(&cpu_mem[this_cpu].lock);
}似乎按照同样的道理,kalloc()也直接仿照上面kfree(),获取现有CPU的锁,然后把freelist指向下一个空页。直接这么写,系统boot的时候就会触发panic。
这里需要注意,在只有CPU0调用了kinit(),因此在初始时,CPU0的freelist拥有所有空闲内存,其他CPU的freelist都是空的!提示已经告诉我们,如果某一个CPU的free list空了,它应该从其他CPU”偷“一个空闲页。所谓”偷“的过程是:CPU1使用CPU0的freelist来kalloc()一个页,CPU1会修改CPU0的freelist,然后把得到的指针传给CPU1上正在运行的线程。稍后,该线程使用kfree()释放了这页内存,kfree()把这页内存加入到CPU1的freelist。
为kalloc()设计偷页的功能:
void *
kalloc(void)
{
struct run *r;
push_off();//记得关中断
int this_cpu = cpuid();
pop_off();
acquire(&cpu_mem[this_cpu].lock);
r = cpu_mem[this_cpu].freelist;
if(r)
{
cpu_mem[this_cpu].freelist = r->next;
release(&cpu_mem[this_cpu].lock);
}
else//尝试从其他的CPU的freeList里取得
{
int j;
int free_cpu;//哪个CPU有空的free list
for(j=0;j<NCPU;j++)
{
free_cpu=(this_cpu+j)%NCPU;
if(cpu_mem[free_cpu].freelist!=0)//如果freelist是有值的
break;
}
release(&cpu_mem[this_cpu].lock);//释放了现在cpu的锁
acquire(&cpu_mem[free_cpu].lock);//获取cpu j的锁
r = cpu_mem[free_cpu].freelist;
if(r)
cpu_mem[free_cpu].freelist = r->next;
release(&cpu_mem[free_cpu].lock);//释放cpu j的锁
}
//printf("cpu %d kalloc %p\n",this_cpu,r);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}如果自己的freelist已经空了,那么从右侧开始循环搜索所有CPU,如果发现谁的freelist不为空,就及时释放现在CPU的锁。获取偷窃目标的锁,把偷窃目标的freelist指向下一页,然后返回偷到的空页指针r。
Buffer cache
xv6文件系统里有一个buffer cache layer,它的用途是:
(1) synchronize access to disk blocks to ensure that only one copy of a block is in memory and that only one kernel thread at a time uses that copy;
(2) cache popular blocks so that they don’t need to be re-read from the slow disk.
很明显就像CPU里面的cache一样,要利用局部性原理做低速存储器的缓冲。这个比kalloc要复杂,我们来看一下它做了什么:
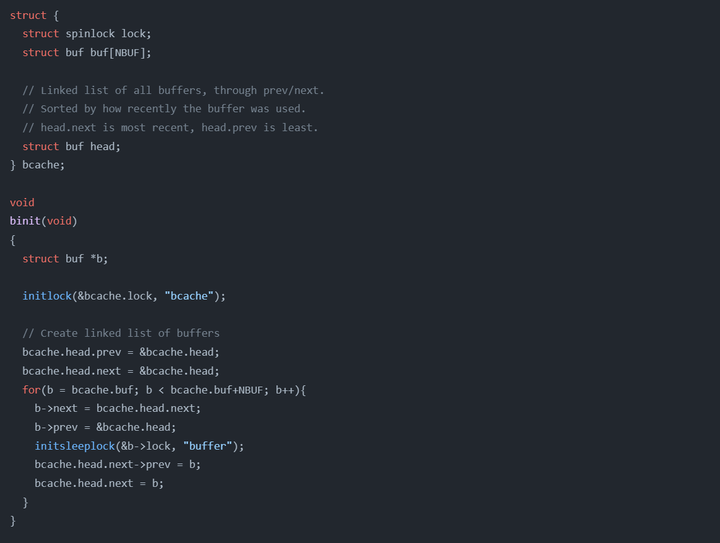
bcache就是整个buffer cache了,里面有一个自旋锁lock和一个双向链表。链表头部是head,其他节点都存储在buf数组里。(这里可没有stdlib.h和malloc,必须使用静态链表)每个buf块里有它对应的dev和block,每个block只能有一个对应的buf块。每个buf块里都有一个用来读写的睡眠锁。
首先调用binit初始化链表和锁。
看一下稍后要修改的bget函数:
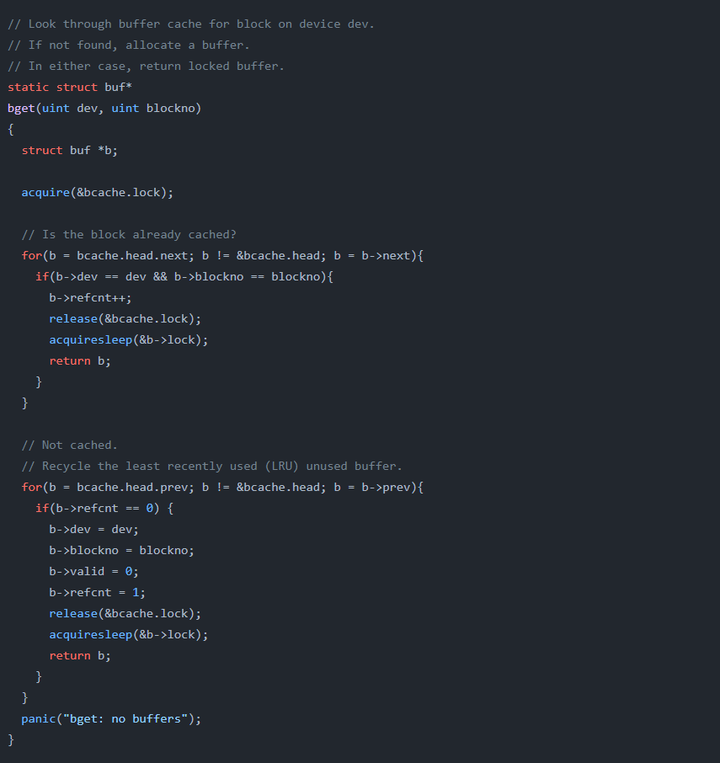
这个bget函数先获取了访问链表的自旋锁bcache.lock,然后遍历链表,根据传入参数寻找buf块,如果找到了对应的块就释放自旋锁,调用睡眠锁准备读写。
如果没找到,就从后往前遍历链表,找到一块refcnt为0的块(refcnt为0意味着未被使用),初始化它,然后获取睡眠锁来读写。
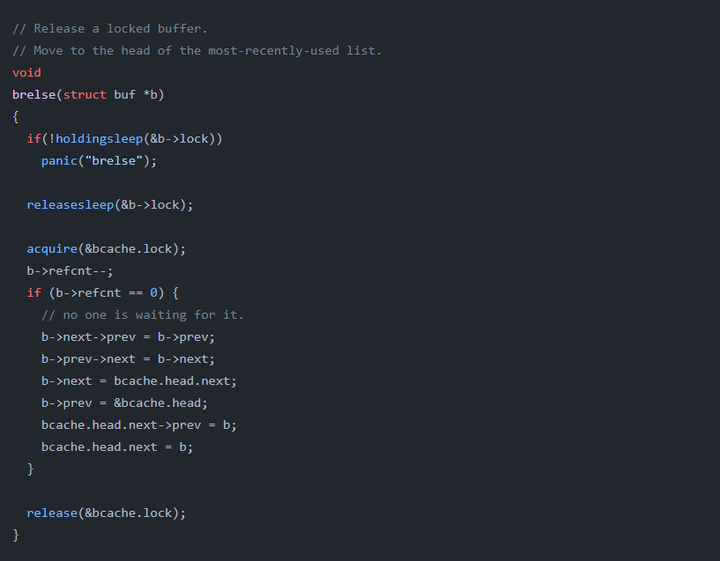
brelse()函数的主要功能就是释放的buf块移动到链表的头部。这样可以实现LRU。链表中越往后的buf块就是使用的越少的块。
和上面kalloc一样,多个进程访问bcache都需要获取bcache.lock这个自旋锁。按照提示,可以使用一个hash表来代替buf链表来减少冲突。我们可以把blockno映射到这个hash表的bucket中。
struct bucket{
struct spinlock lock;
struct buf bufarr[BUCKETSZ];//每一个bucket 存储的buf
};
struct bucket bhash[NBUCKETS];声明一个hash表bhash,有NBUCKETS个bucket,每个bucket有一个自旋锁和一组buf节点。如果需要访问hash表,首先根据blockno计算出它在表中的位置,然后在bufarr里面搜索即可。
这里用的散列函数比较简单,直接取模:
int hashkey(uint key)
{
return key%NBUCKETS;
}为buf添加几项:
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
uint timestamp; //时间戳
int bucket;//属于哪个bucket
};初始化hash表。
void binit(void)
{
//初始化每个锁的名称
uint init_stamp=ticks;
for(int i=0;i<NBUCKETS;i++)
{
//snprintf(name,18,"bcache",i);
initlock(&bhash[i].lock,"bcache");
for(int j=0;j<BUCKETSZ;j++)//初始化时间戳
{
bhash[i].bufarr[j].timestamp=init_stamp;
bhash[i].bufarr[j].bucket=i;//记录它属于哪个bucket
}
}
}实验要求使用系统时间戳来实现LRU,所以获取调用binit()时的ticks作为初始时间戳,然后进行初始化。
然后修改bget,首先根据blockno映射到相应的bucket,获取该bucket的自旋锁,然后遍历这个bucket里面的bufarr,找到之后要更新时间戳,释放自旋锁调用睡眠锁。如果没有找到,就在所有refcnt为0的项里面搜索时间戳最小的,作为替换对象:
static struct buf* bget(uint dev, uint blockno)
{
int key=hashkey(blockno);
acquire(&bhash[key].lock);//hash到对应的bucket,需要获取bucket上面的锁
struct buf* b;
for(b=&bhash[key].bufarr[0]; b<&bhash[key].bufarr[0]+BUCKETSZ; b++)
{
if(b->dev == dev && b->blockno == blockno)//如果找到该节点
{
b->refcnt++; //增加引用数
b->timestamp=ticks;//更新时间戳
release(&bhash[key].lock);//释放bucket锁。其他进程可以访问bucket了
acquiresleep(&b->lock);//获取该节点的睡眠锁,准备读写
return b;
}
}
//没有找到:找时间戳最小的未使用项
uint minstamp=~0;
struct buf* min_b=0;
for(b=&bhash[key].bufarr[0] ; b<&bhash[key].bufarr[0]+BUCKETSZ; b++)
{
if(b->timestamp<minstamp && b->refcnt==0)
{
minstamp=b->timestamp;
min_b=b;
}
}
if(min_b!=0)
{
min_b->dev = dev;
min_b->blockno = blockno;
min_b->valid = 0;
min_b->refcnt = 1;
min_b->timestamp=ticks; //记得更新时间戳
release(&bhash[key].lock);//释放bucket锁。其他进程可以访问bucket了
acquiresleep(&min_b->lock);//获取该节点的睡眠锁,准备读写
return min_b;
}
panic("bget: no buffers");
}
这时brelse就很简单了,首先务必要释放之前在bget()调用的睡眠锁,只需要减少refcnt数目就可以了。LRU功能已经由时间戳实现,所以可以直接删掉后面的链表操作:
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bhash[b->bucket].lock); //获取它所在bucket的自旋锁
b->refcnt--;
release(&bhash[b->bucket].lock);
}顺便再修改一下最后两个函数,因为之前它们直接获取了bcache.lock:
void
bpin(struct buf *b) {
acquire(&bhash[b->bucket].lock);
b->refcnt++;
release(&bhash[b->bucket].lock);
}
void
bunpin(struct buf *b) {
acquire(&bhash[b->bucket].lock);
b->refcnt--;
release(&bhash[b->bucket].lock);
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号