MIT 6.S081 2021: Lab Multithreading
xv6进程的切换
先总结进程切换的过程:
1.从进程1进入到内核中,保存用户进程的状态并运行进程1的内核线程。
2.从进程1的内核线程切换到进程2的内核线程,切换需要以CPU调度线程为中介。
3.进程2的内核线程暂停自己,并恢复进程2的用户寄存器。
4.最后返回到进程2继续执行。
xv6使用抢占式调度,每过一个tick的时隙,操作系统就会中止当前正在运行的进程,然后选择一个进程来运行(完全有可能是原来的进程)。因此,之前做lab trap的时候,你可能会发现在usertrap()里有一段代码,每当出现时钟中断的时候就做出一个名为“yield”的操作:

注释说明了这个yield()负责放弃CPU控制权。来看一下yield都做了哪些操作:

yield()只是把进程状态设置成了RUNNABLE,并调用shred()。再看shred():

前面做了一大堆错误检查,然后调用了一个swtch()函数。首先要搞清楚,这个mycpu()是做什么的呢?是这样:每个CPU上都有一个负责调度的线程,它的信息存储在proc.c里的struct cpu cpus[NCPU]数组里面。看一下proc.h里面struct cpu的结构:

里面有一个context结构体,查看这个struct context的成员(就在struct cpu上面),发现这个结构体保存的是线程的一些寄存器。因此,CPU的调度线程的运行环境就可以备份在context中。
struct proc里面也有这个结构。注释写的很清楚,swtch到这里就可以运行这个进程。需要注意的是:这里每个进程有两个线程,一个用户线程,一个内核线程,一个进程要么运行在用户线程,要么运行在内核线程。context存储的是该进程的内核线程的寄存器,用户线程下的寄存器是存在trapframe里面的。

再看一下swtch.S里面swtch()函数的定义,发现全都是汇编代码,操作就是把线程1的callee save寄存器以及ra、sp存到它的context成员里面,然后把线程2的context内容恢复到寄存器里。到这里就很清楚了,shred()的作用就是:保存现在进程1内核线程的内容,切换到本CPU的调度线程。这就是所谓的“上下文切换”。
注意一点,上下文切换的核心就在于ra和sp,只要确定好切换对象的栈在哪里和程序下一步执行的代码在哪里,再保存好自己该保存的寄存器就可以了,剩下的信息会在切换对象的栈里保存。
那么CPU的调度线程是如何实现的呢?如果看一下操作系统内核的main.c代码,会发现内核main函数的最后一步是调用函数scheduler():
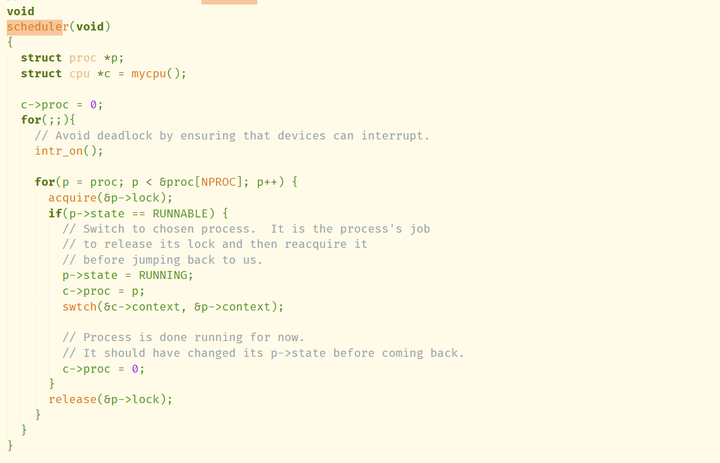
这就是调度线程的实现了,它无限遍历了所有进程的proc结构,如果有RUNNABLE的进程就使用swtch切换到它的context。也就是说,scheduler()从CPU的调度线程切换到进程2的内核线程。准确的说,是恢复到进程2之前在sched()调用swtch()的时刻。之后进程2会继续执行sched()往后的代码,一直到返回用户态,这样就完成了整个切换的过程。
Uthread: switching between threads
有了上面的基础,接下来处理uthread就方便了。这里thread_a、thread_b、thread_c的流程是:首先检查另外两个有没有开始执行,没有的话调用yield();每打印一行字就调用一次yield();进程结束时调用thread_schedule()。进程表all_thread的第一个元素代表main,状态总是RUNNING,只在第一次切换时会用到它。
假设现在执行thread_a,它会选定all_thread[1]作为该线程的控制块。因为另外两个线程没有开始执行,所以调用yield()进入thread_schedule()。t会被设置成all_thread[0],next_thread会被设置为all_thread[1]。然后调用thread_switch函数,切换上下文。thread_switch直接套用xv6内核的swtch即可:
struct thread增加一项:
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context regdata;
};uthread_switch.S直接使用swtch.S的一系列操作即可。
allthread数组是未初始化的全局变量,应该是位于.bss段,初始值默认为0,因此直接执行thread_switch会把所有的寄存器都写入0。之前我尝试在thread_create中直接使用内联汇编向sp等寄存器里写入栈顶地址,总是在sepc=0x0000000000000002位置出现问题,这是因为0覆盖了我写入的内容。所以正确的做法是,在thread_create中就设置好regdata里的ra和sp寄存器:
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
(t->regdata).sp=(uint64)t->stack+STACK_SIZE;
(t->regdata).ra=(uint64)func;
}sp设置为stack数组的尾部(栈是从高到低增长),ra是return address,设置为func的地址。这样稍后就向寄存器ra和sp写入值,执行完thread_switch(),就会往ra指向的地址返回,从func()开始执行。
Using threads
ph.c实现了一个hashtable。如果多个key映射到同一个bucket,hashtable的做法是在bucket后面挂一串链表,每个value都占一个链表节点,对应一个key。这样,在insert()会出现race condition:

看第37和38行,假设线程A即将向某一项插入节点a,线程B也要向其插入节点b。如果按照以下序列:
1.A执行到37行,把a->next指向链表头节点。
2.这时系统切换到B线程,把b插入链表头部,这时p里存储的值是b的地址。
3.A执行38行,把*p覆盖为a的地址。这时我们丢失了b的地址,无法再访问b。
因此在insert()附近上锁即可。
static
void put(int key, int value)
{
int i = key % NBUCKET;
// is the key already present?
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
pthread_mutex_lock(&lock);
if(e){
// update the existing key.
e->value = value;
} else {
// the new is new.
insert(key, value, &table[i], table[i]);
}
pthread_mutex_unlock(&lock);
}Barrier
这个程序调用3个线程,每个线程都执行20000次barrier。要求是:线程执行barrier()里必须阻塞,只有等到所有线程都执行到barrier()时才能打开阻塞,继续执行循环。
思路很直白:每调用一次barrier()都先为bstate.nthread加1,如果不等于nthread,就在条件变量上pthread_cond_wait;直到所有线程都调用barrier()时,最后一个调用barrier()的线程可以跳过wait(),执行pthread_cond_broadcast并置bstate.nthread为0。(记得上锁)
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
bstate.nthread++;
if(bstate.nthread!=nthread)
{
pthread_cond_wait(&bstate.barrier_cond,&bstate.barrier_mutex);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
//所有进程都达到barrier了,由最后一个达到线程的解锁
if(bstate.nthread==nthread)
{
pthread_mutex_lock(&bstate.barrier_mutex);
bstate.nthread=0;
pthread_cond_broadcast(&bstate.barrier_cond);
bstate.round++;
pthread_mutex_unlock(&bstate.barrier_mutex);
}
}OSTEP里建议使用while来检查pthread_cond_wait()的条件,但是这里因为barrier()本身就是被反复调用的,所以使用if即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号