
边学边做的商品图片爬虫
需求是给出商品名称Excel列表,然后从网站上把这个商品的图片贴到对应格子里
用pandas打开名称列表
pandas操作:https://cloud.tencent.com/developer/article/1785768
file_path = "G:\\work\\list.xlsx"
excel_reader = pd.read_excel(file_path, sheet_name = "FULL PRICE")
count = 1
首先是获得商品界面的url,一开始想的是做自动搜索,但是后来发现商品界面的地址大部分是商品名的变形,所以处理字符串之后直接用requests获得页面代码
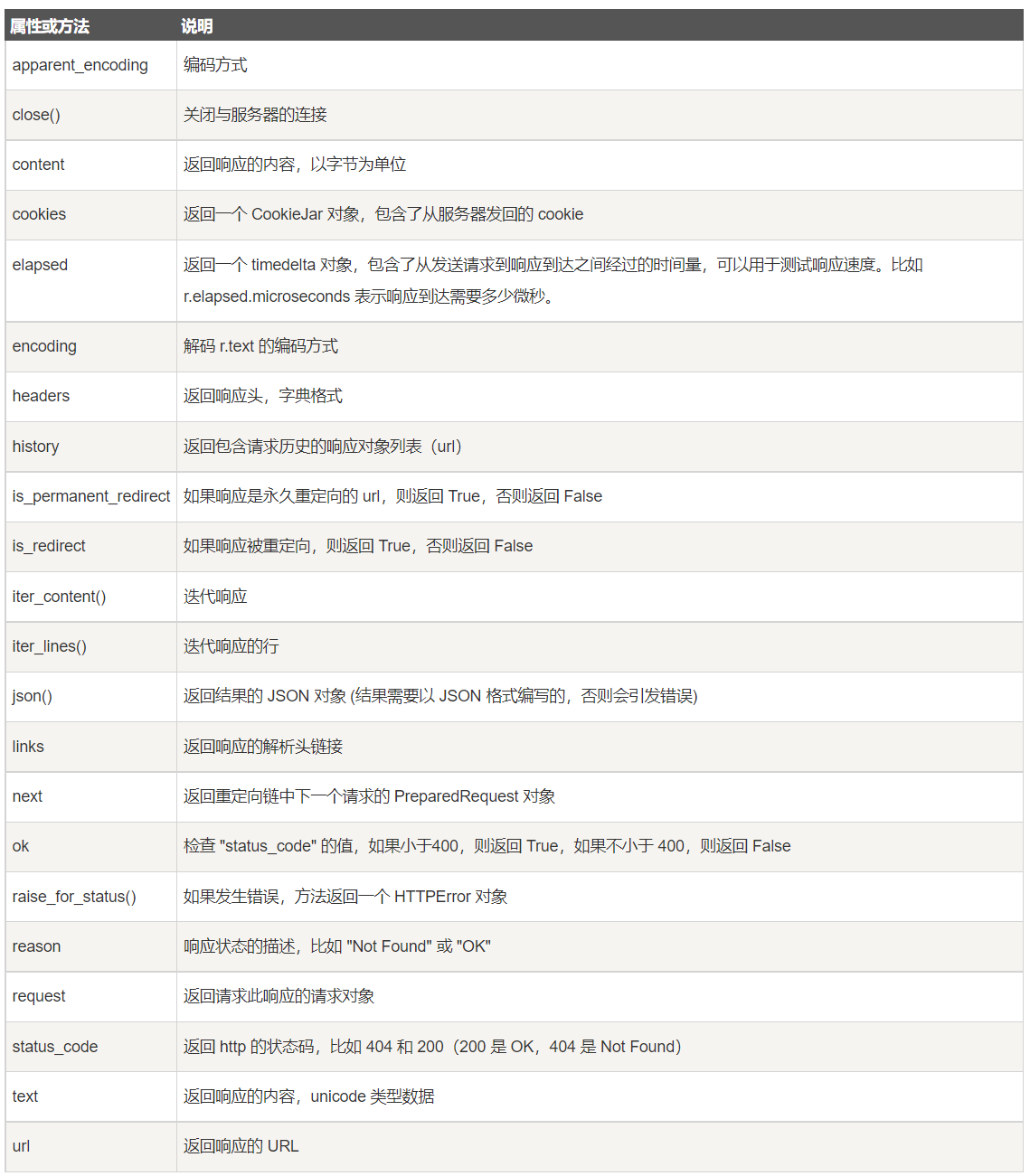
# 提取商品名的url形式
if type(stri) == float:
break
count += 1
s=""
sum = 0
w = 0
p = 0
fr = 0
se = 0
flg = 0
fl = 0
for i in stri:
if i == '[':
flg = 1
if i == ']':
flg = 0
if flg==0 and i == '/':
break
if i == '/':
fl = 1
if (i >= 'a' and i <= 'z') or (i >= 'A' and i <= 'Z') or (i >= '0' and i <= '9') or i == '-':
s+=i
p+=1
if (i == ' ' or i == '/') and s[len(s)-1] != '-':#update
s += '-'
se = fr
fr = p
p += 1
w=se
if s[len(s)-9] == 'O' and s[len(s)-8] == 'n' and s[len(s)-7] == 'e':
ss = s[0: w-4]
# print(ss)
else:#del
ss = s[0: w]
print(s)
print(ss)
def getHtml(url):
try:
reponse = requests.get(url, verify=False)#发送请求并得到回应
reponse.raise_for_status()#查看状态码 如果不是200则执行except
reponse.encoding = reponse.apparent_encoding#将推测的编码方式用于编码
return reponse.text#返回网页内容
except:
return "error"
然后从商品信息页找到主图的图床url:
# 提取图床url
picw = page.find("https://cdn.shopify.com/s/files/")
pic=""
for i in range(picw, len(page)):
if page[i] == '"':
break
pic += page[i]
print(pic)
使用request下载到本地
# 下载图片
response = requests.get(pic,headers = headers)
content = response.content
with open('G:\\work\\'+s+'.jpg','wb') as f:
f.write(content)
Excel的行高有限所以把图片压一下
open(name[, mode[, buffering]])
参数说明:
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。

Image:https://blog.csdn.net/leemboy/article/details/83792729
# 缩小图片
img = PIL.Image.open('G:\\work\\'+s+'.jpg')
width, height = img.size
img.thumbnail((width/2, height/2))
img.save('G:\\work\\resize'+str(count)+'.jpg')
用add_image插入图片并保存
# 插入图片
imgg = Image('G:\\work\\resize'+str(count)+'.jpg') #需添加的图片所在路径
ud=load_workbook('G:\\work\\listout.xlsx') #打开工作簿
ws=ud['FULL PRICE'] #获取工作表
print(count)
ws.add_image(imgg,'G'+str(count)) #添加图片到指定的单元格
ud.save('G:\\work\\listout.xlsx') #保存文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号