
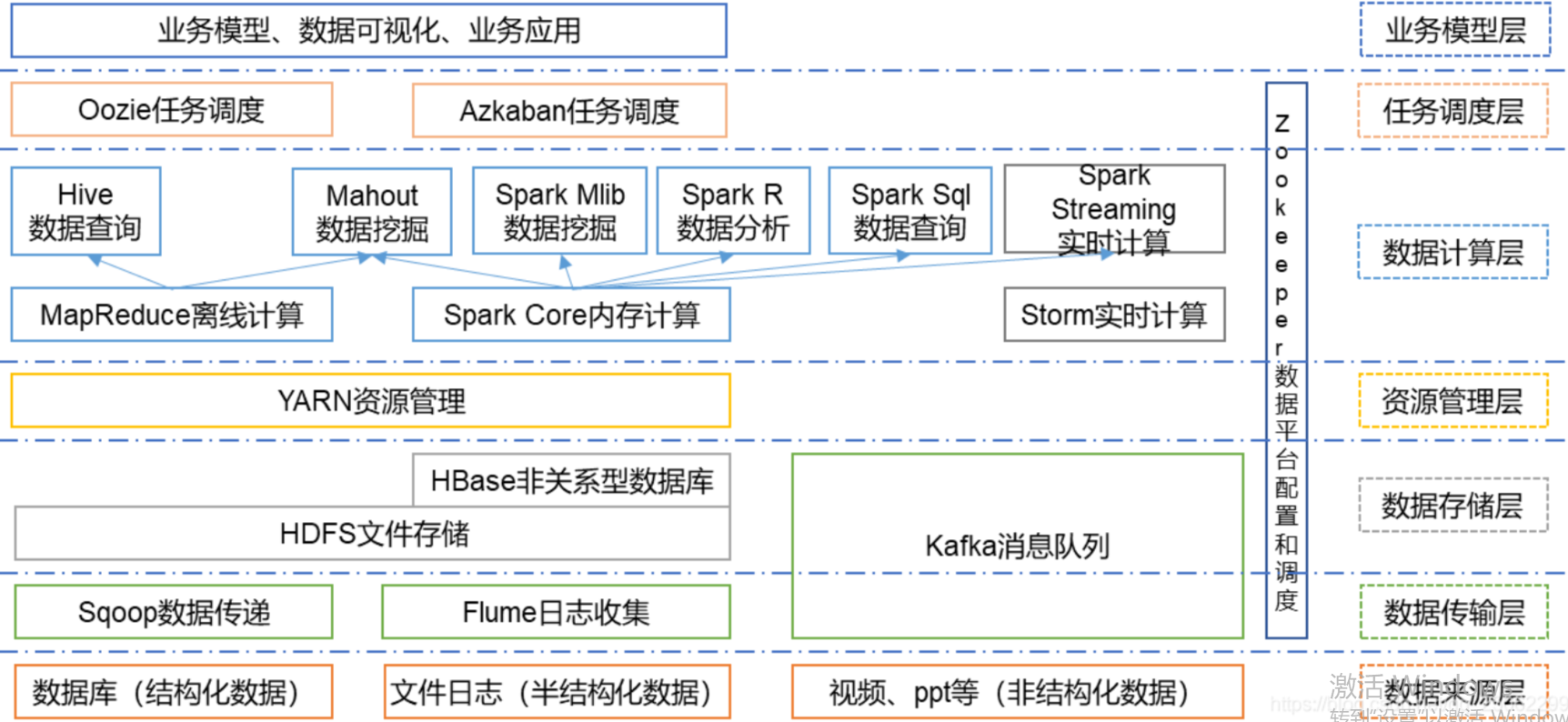
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠、高效、可伸缩等特点
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
1、HDFS(分布式文件系统)
HDFS是整个hadoop体系的基础 。
功能:负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
2、MapReduce(分布式计算框架)
MapReduce是一种基于磁盘的分布式并行批处理计算模型。
功能:用于处理大数据量的计算。其中Map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,Reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
3、Spark(分布式计算框架)
Spark是一种基于内存的分布式并行计算框架。
同样是处理大数据计算,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
4、Flink(分布式计算框架)
Flink是一个基于内存的分布式并行处理框架。
功能类似于Spark,但在部分设计思想有较大出入。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。
5、Yarn/Mesos(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的。
功能:主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的
6、Zookeeper(分布式协作服务)
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面。
功能:协调服务/解决分布式环境下的数据管理问题(即用于管理Hadoop操作,如统一命名,状态同步,集群管理,配置同步等)。
7、Sqoop(数据同步工具)
Sqoop是SQL-to-Hadoop的缩写。
功能:主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
8、Hive/Impala(基于Hadoop的数据仓库)
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。
功能:通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,
Hive功能:Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Impala功能:用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。因此执行效率高于Apache Hive。
9、HBase(分布式列存储数据库)
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
10、Flume(日志收集工具)
Flume是一个可扩展、适合复杂环境的海量日志收集系统。
功能:将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM。单个Agent由Source、Sink和Channel三大组件构成
11、Kafka(分布式消息队列)
Kafka是一种高吞吐量的分布式发布订阅消息系统。
功能:可以处理消费者规模的网站中的所有动作流数据。实现了主题、分区及其队列模式以及生产者、消费者架构模式。
生产者组件和消费者组件均可以连接到KafKa集群,而KafKa被认为是组件通信之间所使用的一种消息中间件。KafKa内部氛围很多Topic(一种高度抽象的数据结构),每个Topic又被分为很多分区(partition),每个分区中的数据按队列模式进行编号存储。被编号的日志数据称为此日志数据块在队列中的偏移量(offest),偏移量越大的数据块越新,即越靠近当前时间。生产环境中的最佳实践架构是Flume+KafKa+Spark Streaming。
12、Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。
功能:能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Hbase(数据仓库)
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、 实时读写的分布式数据库
功能:利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理 HBase中的海量数据,利用Zookeeper作为其分布式协同服务,主要用来存储非结构化和半结构化的松散数据(列存NoSQL数据库)
Pig
Pig是一种数据流语言和运行环境,常用于检索和分析数据量较大的数据集。Pig包括两部分:一是用于描述数据流的语言,称为Pig Latin;二是用于运行Pig Latin程序的执行环境。
功能:作为数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业
2.对比Hadoop与Spark的优缺点。
Spark 和 Hadoop 的比较
mapreduce 读 – 处理 - 写磁盘 -- 读 - 处理 - 写
spark 读 - 处理 - 处理 --(需要的时候)写磁盘 - 写
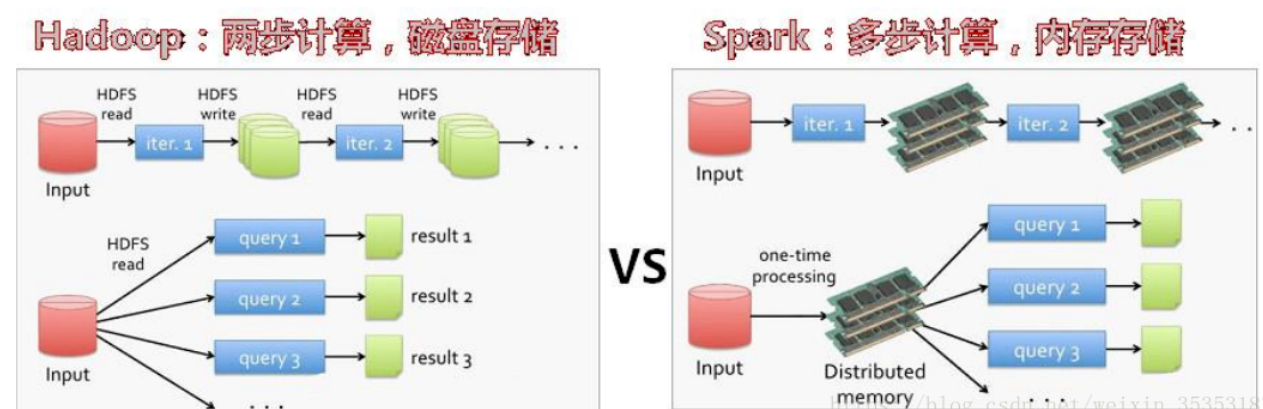
首先,Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
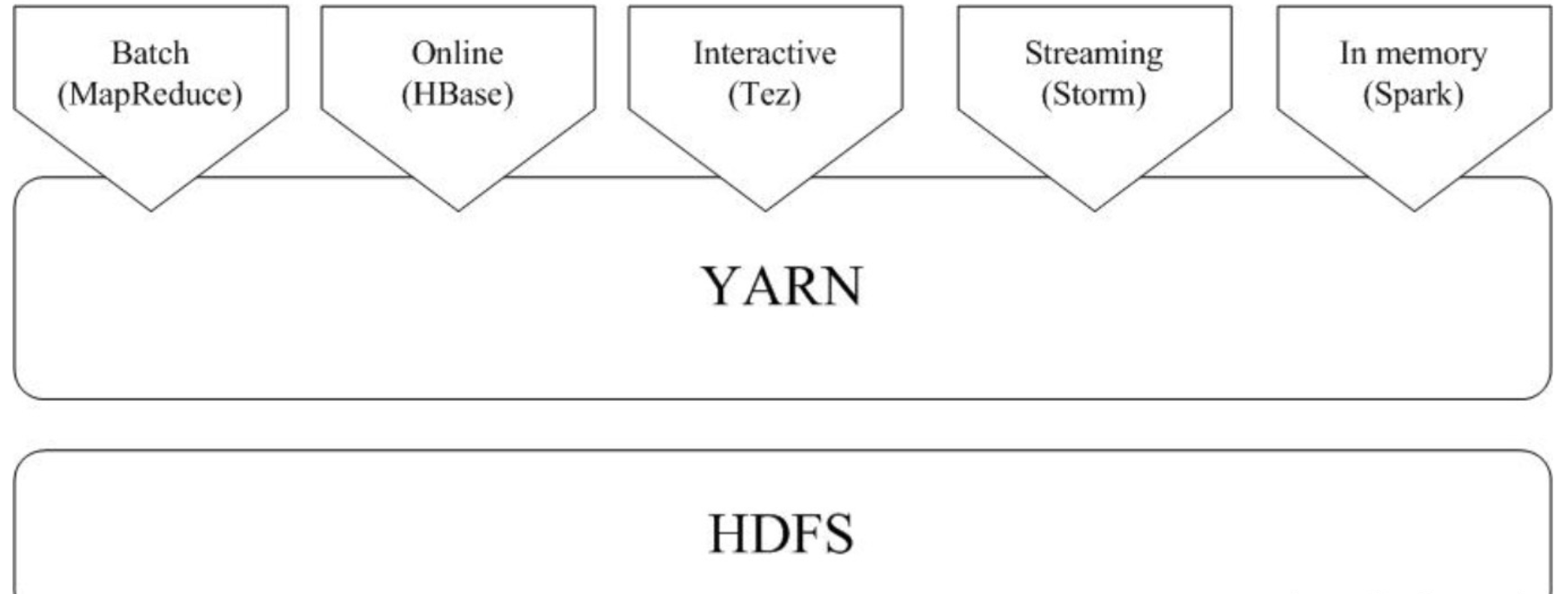
3.如何实现Hadoop与Spark的统一部署?
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署(如图9-16所示)。这些不同的计算框架统一运行在YARN中,可以带来如下好处:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号