软件开发你不可不知的那些事:如何有效减轻风险和质量债务?
在评估代码库的风险时,这不是单个的魔术数字,也不是简单的像是“通过/不通过”交通信号灯。风险是多维和多变的,对于不同的组织,风险的衡量方法也有所不同。
你可能已经知道代码中高风险或“不良”部分的位置——它们是你经常更改的代码部分,在这里和那里进行了一些小调整,以修复一些看起来无害的小问题,但通常代表着不良设计之上的要素分层。这就是为什么更改现有代码是在应用程序中引入缺陷的主要原因。
但是我们也知道变化是不变的。你永远不会完全实现所有功能或第一次都无法正确执行,但是与此同时,当你在现有代码上分层时,对每个用例和场景的了解就会丢失,复杂性会增加,并且代码的风险也会越来越大。这些变化为将环境应用于风险提供了关键条件。
与了解风险本身同样重要的是,了解如何应对风险——如何确定补救措施的优先级,以实现“可接受的风险水平”,同时最大程度地降低对团队速度的影响。不过,这篇文章仅着眼于:如何评估代码更改的风险以及如何有效地确定优先级和减轻风险。
确定多元风险
风险不是一个单一的数字,也不是项目级别的“交通灯”(尽管我们确实在UI中使用了易于关联的交通灯颜色),而是代码库的分类以及关于实际和潜在存在的问题的指导。见下文:
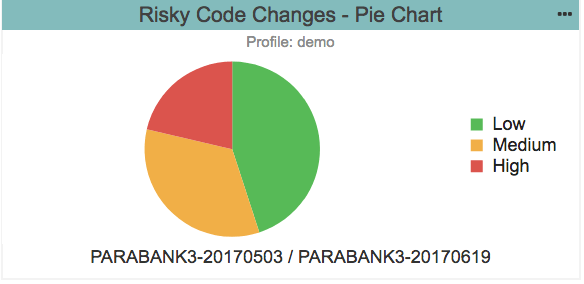
来自Parasoft的Process Intelligence Engine的饼图示例,显示了高、中和低风险代码的比例。
风险的分类既是多维的又是多元的——你必须将静态分析、度量、代码覆盖率和测试等技术中的质量度量汇总在一起,才能真正理解它。这些技术中没有一个能为你提供特定维度的值,而是为公式提供了值。例如,代码覆盖率不是一个好用的数字,因为你可以拥有100%的覆盖率,但是只有少量的测试可以做有意义的事情——你需要考虑使用代码覆盖率告诉你的内容(即,“我的代码的测试水平如何?”),并通过添加更多数据来进行更有意义的分析。
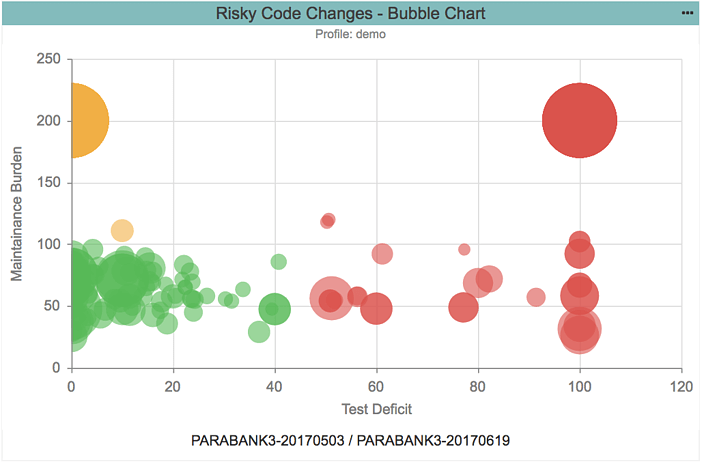
风险代码更改气泡图的示例说明了最高风险所在。 (可以扩展气泡以查看驱动分类的指标。)
上面的气泡图说明了基于两个维度的风险分类(也如下列所述):
- 维护负担。结合使用Halstead体积、严格的循环复杂性、代码行数和代码与注释的比率来量化代码的可维护性和可理解性,以及
- 测试缺陷。使用测试次数、方法数量和代码覆盖率来量化测试代码的质量。
测试不良的代码(即测试缺陷较高)被归类为高风险(红色),而经过良好测试和结构良好的代码(即较低的维护负担)被归类为低风险(绿色)。
易变的代码库,其中的每项更改都有风险
在开发过程中,你的代码库处于不断变化的状态,每行更改的代码都会带来未知的风险。它会破坏基本功能吗?它会引入安全漏洞吗?信息越少,风险越大。在之前的文章中,我们讨论了变更对测试的影响,以及如何智能地使用代码覆盖率来预测测试资源需要集中在哪里。但是,即使覆盖范围和测试范围不断扩大,随着时间的流逝,仍然存在更多的风险。
代码库中的更改为我们提供了第三个也是最重要的风险维度:时间。时间不是传统意义上的时间,而是与构建及其之间的变化相关的时间。专注于代码库在内部版本之间已更改的部分,这使我们能够集中精力处理风险最高且最相关的代码,因为该团队目前正在代码库的这一部分中工作。
质量债务的负担会拖慢你的速度吗?
重用和遗留代码已经有其自己的负担,特别是对于安全性。如果没有足够的检查来维持或改善质量基准,则每条提交或修改的代码行都会加重债务。要摆脱这种债务,就像任何债务一样,需要关注并致力于减少债务。另外,就像任何债务一样,除非你知道钱花在了哪里,否则怎么会知道如何储蓄?
一旦确定了具有最高风险和最高优先级的代码,就还需要考虑减轻风险所需的工作量。这是第四个也是最后一个方面:质量债务。在上面的气泡图中,质量债务用气泡的大小表示——气泡越大,需要解决的已知问题越多。在我们的示例中,质量债务是高严重性静态分析违例(包括违反代码度量标准的设置阈值)和测试失败的组合,并通过逻辑代码行数进行了标准化(请参见图3)。
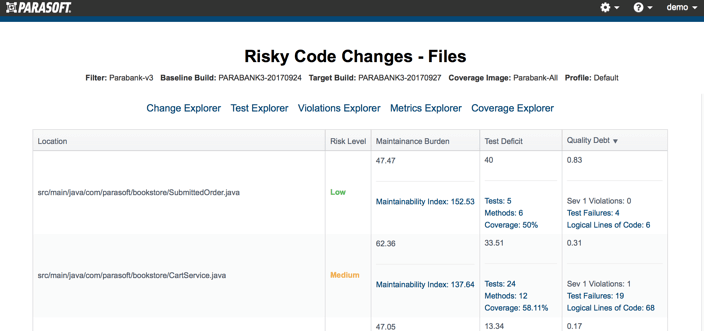
这些出色的质量任务的汇总为降低代码风险所需的相对工作量提供了指导。
但这不是我衡量风险的方法!
并非每个组织都将遵循相同的质量实践或在计算尺寸时要考虑哪些因素。你需要能够配置和创建自己的风险定义。
本文中展示的示例可供市场上的相关用户使用,使你可以立即使用它,并进行扩展和修改以满足你的特定需求。从示例开始,你可以自定义静态分析、指标阈值和风险分类以适合你自己的组织。
总结
通过适当的安全措施平衡预算、进度和质量目标,同时满足客户需求,这是一个艰巨的任务,每一个环节都有风险。但是,质量实践和流程智能的自动化可帮助你将资源最佳地用于哪里。了解风险的根源以及每个代码的更改方式如何影响基线质量和安全性,可以减少开发方程式中的许多未知数。通过正确地关注和措施,质量和安全债务问题是可以克服的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号