机器学习 | 基于机器学习的供应链管理之销售库存优化分析(实操分享)
本次是用机器学习做出未来一定时期内的销售量预测,从而辅助指导销售库存计划的决策分析,以达到合理配置库存,减少资源成本浪费的目的。实操内容有点多,虽然我已经尽量删减了。有兴趣的朋友可以关注+收藏,后面慢慢看哟。如果觉得内容还行,请多多鼓励;如果有啥想法,评论留言or私信。那么我们开始说正事了~
一、数据准备阶段
数据集描述
用于技术验证的数据集来自kaggle上的医药销售预测项目Rossmann Stores Clustering and Forecast,整个数据集包含三张表:训练集、测试集、经销商信息表。测试集只比训练集少销售额Sales和Customers这两个字段,其它字段完全相同,其中训练集和测试集分别有1017209和41088条,训练集和测试集前五条数据如下。


测试集包含未来六周的促销等状况,要求预测指定经销商的销售额或则顾客总数。
经销商信息数据集store.csv有1115条数据,也就是1115家经销商,10个字段。

其中Store字段唯一代表一家经销商,可以将train.csv和test.csv分别与store.csv通过字段Store关联起来。
数据预处理
1. 首先从日期字段Date中提取出年月日以及该日期在所在年的第几周,并将它们作为新的字段,方便之后对数据按时间进行聚合处理。
2. 对三张表中的分类变量进行编码转换,采用sklearn内置的LabelEncoder编码。
3. 查看每张表的字段缺失情况,train.csv,test.csv,store.csv缺失如下

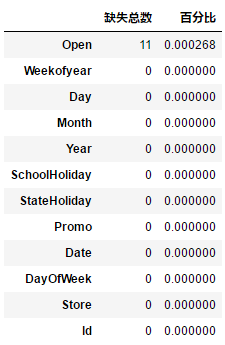
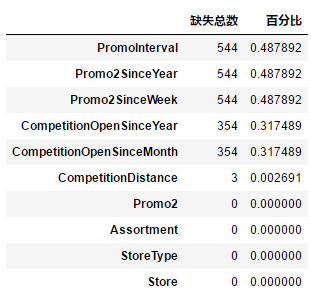
在store表中,缺失字段CompetitionDistance表示最近竞争对手的距离,是一个连续变量,用中位值填充该变量的缺失值,其它的确实变量统统用0填充。对于test表中有11条变量确实Open字段,表面其没有开业,在后面的建模中会被直接过滤掉,此处暂不处理。
4. 合并字段CompetitionOpenSinceMonth表示距离最近的竞争对手开业的月份,CompetitionOpenSinceYear则表示开业的年份,构造字段CompetitionOpenSince表示竞争对手开业以来的总的月份;Promo2SinceYear/ Promo2SinceWeek表示商店参与最近促销的年份和参与时间所在的周,构造字段Promo2Since表示商家参与促销以来所经历的周数,根据经验Promo2Since与Promo会呈现负相关性,因为当前促销Promo和之前促销存在竞争关系。
相关性分析
进行变量之间的相关性分析,选取具有代表性的促销相关的变量Promo,Promo2,Promo2Since,以及与竞争相关的变量CompetitionDistance,CompetitionOpenSince,做出它们的散点图,如下
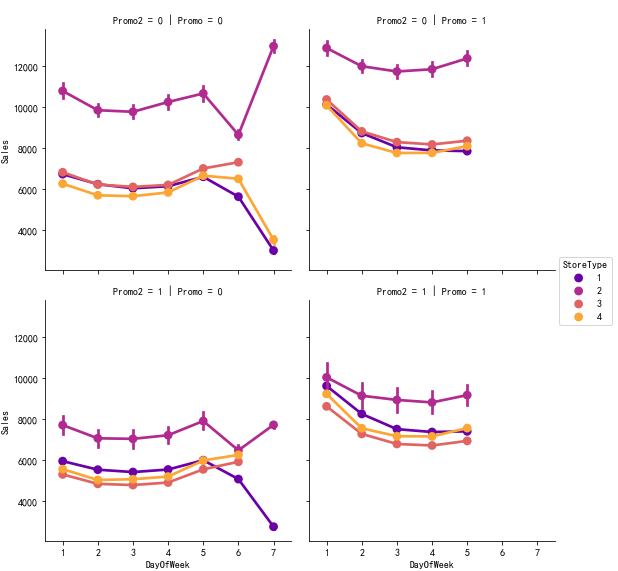
从图中可以发现无论对于哪一种类型的经销商,当前促销Promo能够明显提升当前的销量,而之前的促销Promo2则会降低当前的销量,并且当前促销后销量会在周一达到峰值,另外可以发现当前促销的商家在周六和周日都不开门,第三种类型的商家在周日一直都不开门,第四种商家在当前不促销之前促销时在周日不开门。
同时也做出促销对销量在月份上的影响,如下
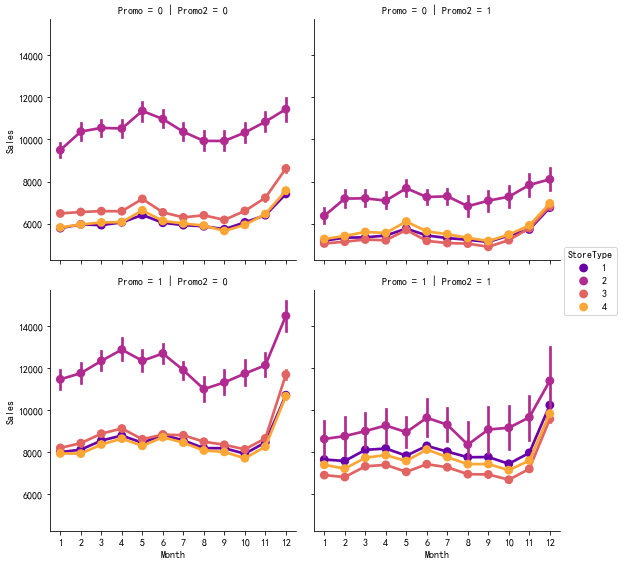
可以发现所有商家在年底的销量达到顶峰,表面月份对销量有显著的影响。
最后做出所有变量的相关系数矩阵,如下所示
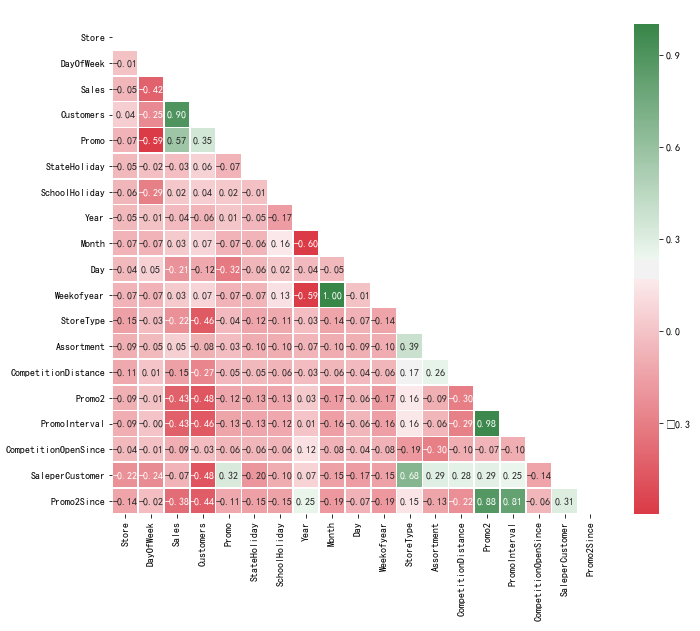
发现Weekofyear和Month,Promo2和PromoInterval相关性非常之高,于是建模时舍弃Month和PromoInterval,其余变量全部用于建立机器学习模型。
二、建模
建立的模型主要建立包括三类:时间序列模型、机器学习模型、深度学习模型。
时间序列ARIMA模型
销售数据是典型的时间序列数据,对销售数据建立时间序列模型需要检验数据的平稳性,趋势性。建模的数据为所有经销商每天的销售总额,为了避免数据波动过大,对原数据取对数,平稳性检验采用最常用的adfuller单位根检验,结果如下
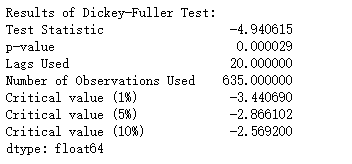
P值非常之小,在99%的置信水平上认为该序列是平稳的。如若不平稳,则可以进行差分运算直至平稳为止,不过通常做3差分后已经平稳。
通过某些方法,例如傅里叶分解、小波分解、TSI分解等,将数据分解成可预测部分和不规则变动(随机波动)部分,可预测部分占比比不规则变动大很多,那么就具备了预测未来的条件。为了查看其趋势性,采用TSI分解,即将时间序列分解成趋势trend,季节周期性seasonal,随机部分residual这三个部分,然后对trend部分建立时间序列模型,然后加上seasonal作为预测值,residual因为是随机的,不能预测。对销量数据进行分解后的效果如下
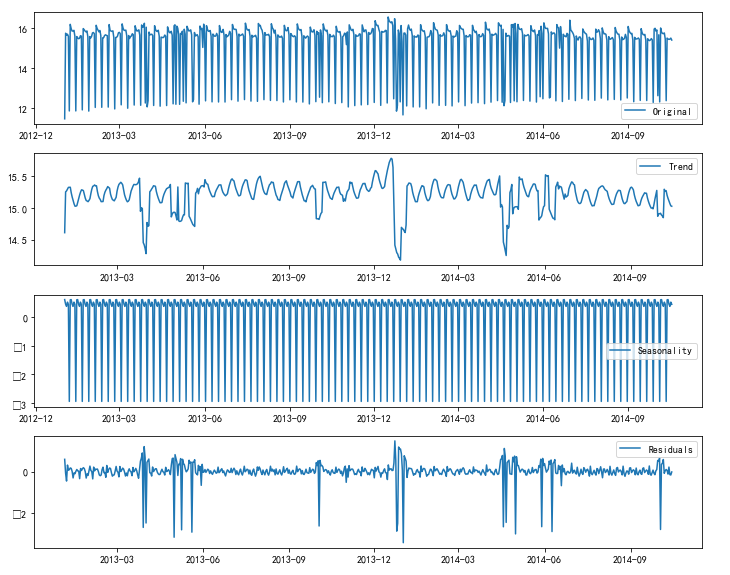
不难发现没有明显的趋势性,呈现波动状态,seasonal部分放大了后发现周期为7,残差部分residual存在毛刺,这可能与促销或者节假日有关,暂且按下不表,先检验residual的平稳性,结果如下
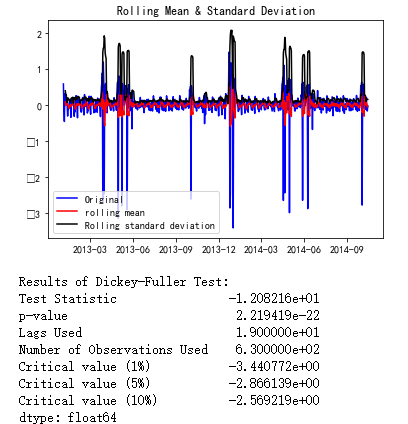
P值十分之小,在99%的置信度下是平稳的。下面用ARIMA模型对trend部分建立模型,确定其AR,MA的阶数都为4,另外没有做差分,所以最终的阶数为order=(4,0,4),对trend的拟合效果如下
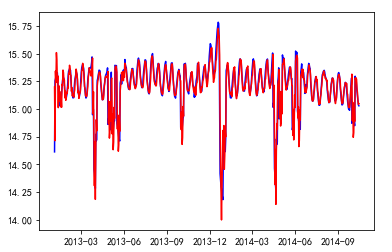
加上seasonal部分在进行指数还原后结果如下
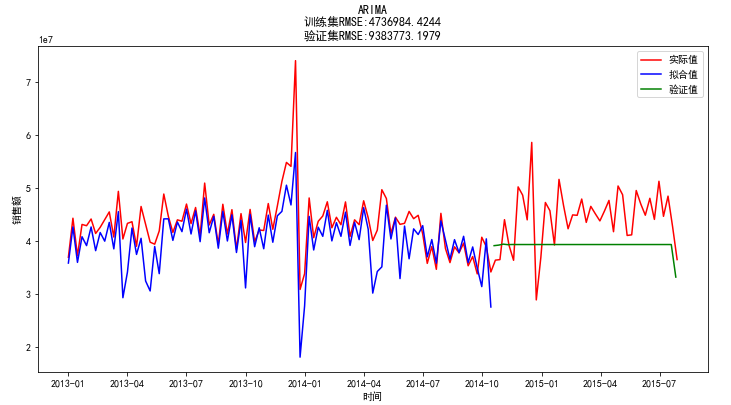
对时间序列按照7:3划分为训练集和测试集,并且将原始数据和预测数据按照7天进行降采样求和,看出在验证集上的RMSE挺大的,意味着存在很大的预测偏差,达到21%。
机器学习模型
将数据集按照7:3的比例划分为训练集和测试集,分别采用了GBT,Xgboost,LightGBM,RandomForest这三种预测准确度比较高的树模型进行预测,预测效果分别如下
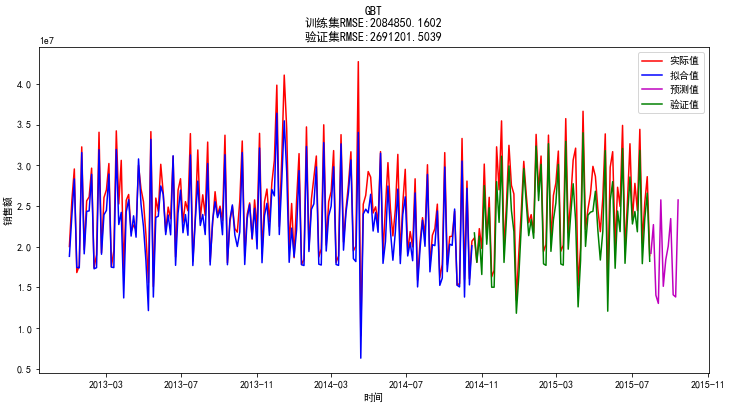
验证集上的平均预测误差为10.91%,
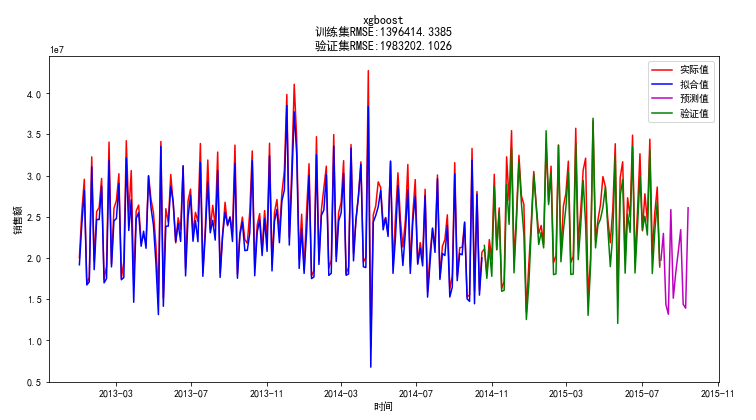
验证集上的平均预测误差为5.57%,

验证集上的平均预测误差为8.57%。
最后选择预测效果最好的Xgboost作为最终的机器学习模型进行销量的预测,给销量预测设置一个预测区间,当预测销量不在区间范围时,厂商或者经销商就应该相应进行库存调整或者促销方案或者销售人员的安排做出变动。预测区间根据预测值的四分位数确定,预测上线为Q3+k1(Q3-Q1),下线为Q1-k2(Q3-Q1),其中k1,k2的值由商家的库存状况自行确定。加上预测区间后的预测效果如下
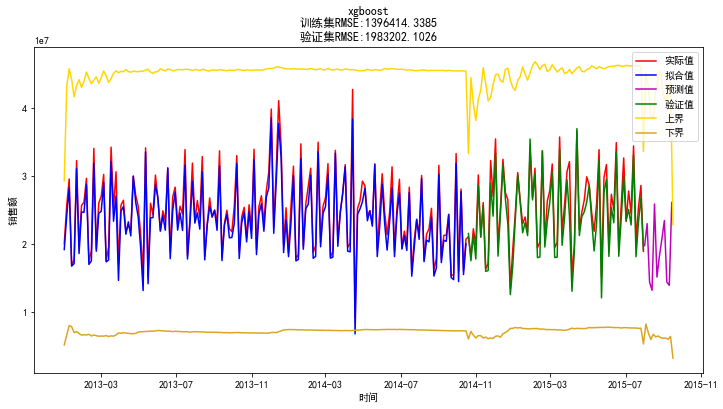
以上内容是对整个公司所有经销商的销售量进行预测,接下来对不同类型的经销商的销售量进行预测,为此把经销商分成5种类型,采用层次聚类,效果如下
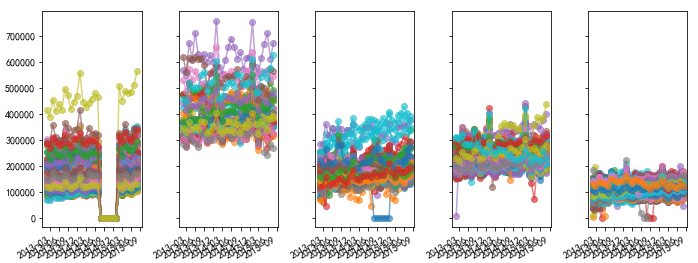
类型种数根据实际情况指定,然后可以按类别分别建模,除此之外,还可以按照每家经销商建立模型。于是,可以给出总销量,某种类型或者某家经销商的销量预测。如下图,给出了这家经销商未来六周的销售量预测值,以及预测区间,其中金色线为预测上限,土黄色线为预测下限

三、后记
实践总结发现仍然存在一些需要改进的地方,主要有以下几点:
- 模型的预测偏差还是比较大,应该适当改进模型,比如进行模型融合,采用DNN等;
- 模型超参数没有调优,可以结合遗传算法搜索最优超参数;
- 特征工程过于粗糙,有必要了解具体业务知识创造特征。
后面会对此次实践做一些优化,可能需要再花上个几天,如果有时间再将后续写上来。一键三连~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号