2021看雪SDC议题回顾 | SaTC:一种全新的物联网设备漏洞自动化挖掘方法
https://zhuanlan.zhihu.com/p/431335767
随着物联网技术的日新月异,未来物联网的应用将越来越广泛,但它同样也会带来大量安全漏洞。而当下IoT漏洞挖掘技术尚未完全成熟,许多人的信息安全意识不够强,技术革新面临着巨大的安全隐患。
来自上海交通大学的陈力波老师所提出的SaTC:一种全新IoT漏洞自动化挖掘方法,相应的学术论文已发表在国际安全顶会 USENIX Security 2021 上,并经历了充分的实际数据校验,在6个知名厂商的39款设备中找到了33个漏洞。实际应用效果突出,对物联网安全领域具有极为重要的意义。
下面就让我们来回顾2021看雪第五届安全开发者峰会上《SaTC:一种全新的物联网设备漏洞自动化挖掘方法》此议题的精彩内容。
演讲嘉宾

【陈力波-上海交大网安学院创新实践教研室副主任】
陈力波:上海交通大学网络空间安全学院创新实践教研室副主任
毕业于清华大学NISL实验室,是著名安全战队“Blue-Lotus”蓝莲花的初创成员,具备多年网络安全攻防经验。主要擅长漏洞挖掘和利用、渗透测试,在IoT、区块链等领域开展安全前沿技术研究。
演讲内容
以下为速记全文:
各位嘉宾大家下午好,我是来自上海交通大学网络安全学院的陈力波,我今天给大家介绍一下我们最近的一个工作,发表在USENIX Security2020上面,是一个关于物联网设备漏洞自动化挖掘的方法。
我们都知道物联网现在在我们的日常生活中已经非常的普及和应用,它在智能家居、手机移动端,还有车联网、工业物联网等场景中。据统计,到2020年为止的话,有580亿的终端在用,我们可以看到它在我们生活中的各个角落里面都广泛的部署着各种的物联网终端设备。同时我们通过公开的研究报道,可以发现其实大量的IoT设备存在着中高危的安全漏洞,给互联网带来了非常大的安全威胁。
主要有以下这么几点:第一个是IoT终端的数量非常巨大,第二个是大部分缺乏安全防护,还有很多终端连接互联网,所以很有可能会成为一个互联网上面的僵尸的节点。

我们可以看到像Mirai这种影响非常广泛的僵尸网络,对美国东部DNS服务照成大面积瘫痪的一个攻击,包括我们右边这个图的话是 TCP/IP协议栈这样的一个通用漏洞,所以整个来说IoT它这种碎片化的一个生态,再加上现在这种迭代开发,所以很多代码其实是高度的复用,有些漏洞的影响面会非常大。
然后其中无线的路由器和网络设备,就类似摄像头这些遭受的攻击会相对来说比较多一点,主要是由于它开放的服务比较多,像web服务、DNS还有UPS这些服务。还有一点就是它大量的连接在互联网上。
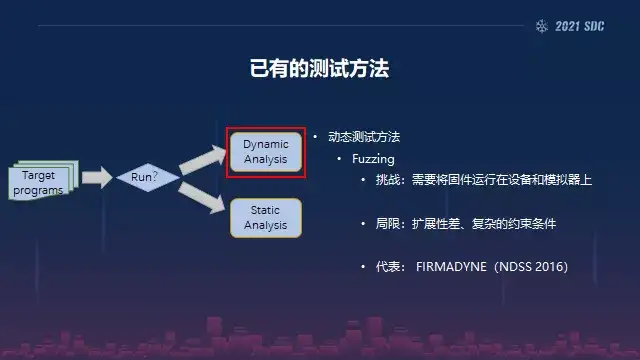
然后我们就在想如何去检测这些设备中的安全漏洞?整个学界大概是有这么两大类,类似动态的方法,动态方法的话就是像我们大家熟知的像Fuzzing,但是在将Fuzzing这种在传统PC领域非常成熟的像AFL这些框架用在这种设备上的话就面临一个问题,你需要把它模拟起来。所以说也就呼应我们前面说到碎片化,现在很难有一个非常统一的高效的这种恢复的环境,来支撑你做这种智能的Fuzzing。
所以整个来说,对IoT的安全研究是局限性很大,然后会带来比较复杂的一个局面。所以我们可以看到在安全顶会上面也有不少相关的研究工作在尝试。比如,Ndss 2016有一个工作Firmdyne,其实这个工作是这方面做的比较大的贡献。
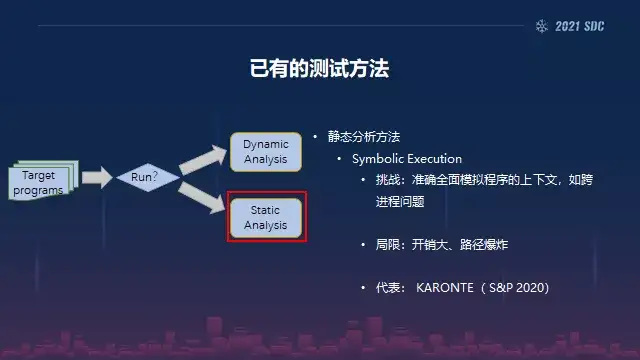
然后第二块的话就是静态分析。静态分析的话,学界比较推崇的是符号执行, 然而实际应用过程中,执行的时候面临着很多的问题,第一个是它的开销非常大,并且会碰到循环约束条件如何结束的问题,导致路径爆炸。
然后还有你要准确的去模拟这种程序的上下文,比如跨进程的问题。如果你多进程通信的话怎么来准确的模拟,因为你是在没有运行程序的状态下,然后符号执行的话,经过这么多年学界的不断的推,它在现在的话是一种混合符号执行的状态,也称之为动态符号执行。就是传统的静态符号之前基本上是不可用的。
所以近些年的话动态符号执行相对来说它用实际的值去替换符号值,所以会做一个路径的探索。这一块的话相对来说比之前的应用性要提高很多,其中的代表的工作是Karonte的,是UCSB发表在另外一个顶级安全会议 S&P 2020上面的。所以我们的工作大部分也是跟他们是聚焦在同一点,所以我们是在他们的基础上又做了非常大的创新和改进。
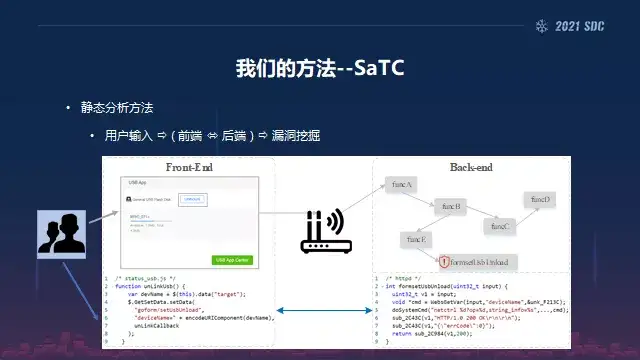
好,我们讲一下我们的方法——SaTC,简而言之,方法来源于共享的关键字,基于这个关键字开展污点分析。我们可以看到像一个典型的这种路由器的话,像注册的话,这里是一个前端的一个界面,像前端的一个界面,然后右侧的话就是它对应的二进制。像前端的话,你用户发送的数据会由于前端代码的这种解析来给到他一个标签,然后后端的话会有相应的关键词出现。所以说这是我们最开始为什么提出这种方法的一种出发点。
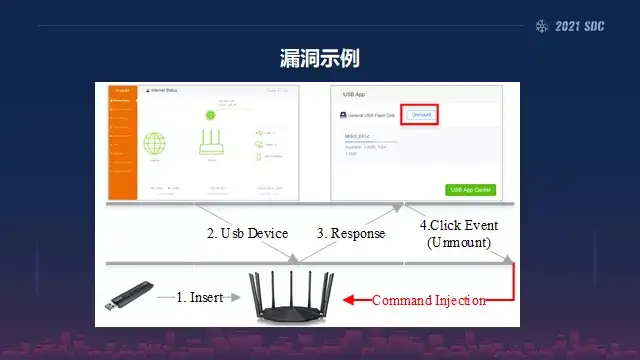
大家可以看一下这个漏洞是一个非常典型的漏洞,它是在一个路由器在插入U盘的情况下。可能可以触发到他的一个命令出路,所以整个漏洞的一个出发过程分了4步,从最开始的操作U盘,然后到管理界面,在它的 response之这个回应界面中再去点击这个mod卸载这个指令,这样的话在这个过程中它发生了一个命令注入,像这里的右下角这是红色字体这里。


然后我们来看一下漏洞的深层次的原因,我们可以看到左边的话是它前端的发现漏洞的一个代码是JS代码,我们看到它是用一个DOS内容这样一个关键字来标注这段数据的,然后右边是相应的二进制程序,它经过一系列非常复杂的函数调用之后,在最后他执行了一个命令叫form set usb unload,这个函数里面它有个doSystem,所以在这里的话他没有去过滤发送过来 device name对应的字段的内容,所以就产生了命令注入。
所以整个攻击来说,只要发送这样一个恶意的链接,就可以完全控制路由器。
所以我们从这个例子可以看出,如果我们有一个非常高效的方法,从前端可以把这些关键字提取出来的话,那么给我们带来的直接的受益。就是我们在整个污点分析的过程当中的话,就可以跳过前面这些没有太多意义的处理函数。
然而传统的污点分析都是从前面开始的,前面这些函数有可能意味着类似于索赔的函道,然后也属于文件系统的投入,对吧?这些内容都是完全跟我们后面的命令做系统来说没有什么太大的关系。
所以说给我们带来的启发,如果我们有这些关键字的话,会极大的缩减我们符号执行的路径,就是让它的可用性得到了进一步的提升。所以我们的一个非常简单的想法就是说在前端的JS文件中,用户输入被一个字符串DOS等号来标记,然后在后端的二进制之中几乎完全相同的字符串dos内容用于提取数据包装对应的system。
所以说两个同时出现的关键字就是我们标题里面所讲到的教学的Key words,所以我们的方法就是这样子来的,就是用共享的关键字在后端的二进制中引入,引入点定位,并开始查找漏洞。
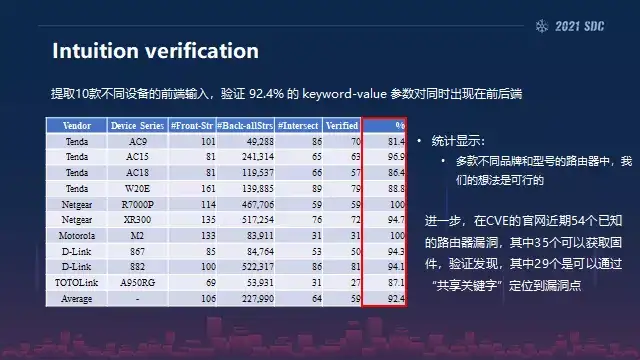
好,然后我们提出这个想法之后,我们需要去统计一下这种现象不是个例是不是只有这个设备才存在。然后我们把手头的各个厂商的路由器也收集一下,大概有这些厂商,都是比较主流的厂商,然后每个厂商的几个型号,我们在利用真机调试的情况下,第8个的权限下面我们做了一个前端的黑盒的fuzzing,然后后端的话我们在相应的输入点,把它的key-value这种参数对提出来,所以我们整个统计可以在这个表格中可以看出来。
有90%多的参数对是同时出现在后端的,然后进一步的我们在CV的官网上,近期54个已知漏洞里面有35个可以获取的固件,就是我们能够分析的,我们发现其中有29个是可以通过共享关键词来定位漏洞点的,所以这样看来我们这个方法是具有一定的普适性。
我们来看我们要做这个工作大概面临的几个挑战,第一个挑战就是如何识别这种前端文件中的关键字。第二个就是如何定位这些关键是在后端的二进制里面的处理位置。第三个就是如何跟踪大量的用户输入的相关路径,检测是否存在安全漏洞。
所以我们可以看一下我们整个的一个设计,从最左边开始是一些包的固件的预处理,然后右边的话有最开始是一个输入关键字的提取,然后第二个是第二个是输入的点的识别,然后最后是一个污点分析,然后我们一个个看一下,我们输入关键词提取模块,主要是我们对应的这些前端常见的资源文件,比如说像html里面的这种JS还有html文件,然后包括xml文件这种描述文件,这里面的关键词都是我们需要去提取的,所以这里的话我们其实也匹配了很多我们人工的一些经验,对吧?

比如像 AST里面的就是JavaScript,因为它相对来说比较动态比较复杂,所以我们用ast来提取文本里面的对应节点的属性,其实就是你可以简单理解为就是把JavaScript里面所有变量的名字把它提出来,所以我们是对应的服务的话,除了HTTP服务,还有UPnP,还有HNAP服务。
然后在提取完之后,其实我们会发现里面有非常多的无关的这种字符串,所以我们会制定一些规则,比如说这些跟输入完全不相关的,我们就把它给剔除掉,然后如果字符串以“=”结尾的话,我们就留下左侧部分,右侧部分就把它舍去,还有一些比较短的这种字符串,所以我们整个的规则集合也是开放的,如果后续有嘉宾在使用的过程中,其实可以自己去定义。

然后我们主要是基于两类,一个是基于前端经验得到的这种筛选模式,还有一个是基于文件和字符串出现的频率。你像这种其他文件里面如果像共享库中的字符串对吧?它大量的被引用,所以我们认为字符串其实是跟输入定制开发是完全没有关系的。然后还有类似于通用字符串,我这边举的例子什么Button和Cancel,这在大概率的情况下是不会有问题的。
所以我们在关注这种开发者定义的这些前端输入的情况下,我们就开始做后端的匹配,就是把刚才过滤完的字符串和后端的所有二进制里面字符串做一个匹配,然后这里还会有带到带来两个非常好的,一个就是可以把边界服务给识别出来,就是说其实在路由器里面,你如果做过漏洞挖掘的话,其实你会发现因为特别是那种cgi的模式下,其实你很难一开始去找到一个跟边界相关的,因为它的命名也不会有太多的这种规则。
如果出就是出了HTTP这种,非常常见的,所以说如果你的关键词量特别大,比如说我跟包括服务相关的关键词在二进制里面匹配的数量特别大,我们就会认为它是我们要关注的,可能存在安全漏洞的边界服务,所以我们怎么会做一个排序,把最高的关键字的对应的二进制来做布点分析。
然后所以紧接着第三个就是一个输入点的识别模块,这里的话整个大概分了三个部分,第一个就是最简单的就是它的一个直接引用,像图里面红色框子里的,对它直接对device里面的引用。
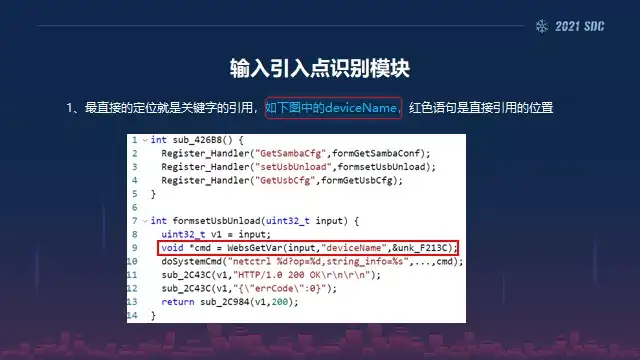
那么第二个的话就是类似于这种启发式的,我们可以看到这里有一个USB Name这个关键词其实在前端里面是提到的,但是我们通过启发式的可以把它发现出来,因为你可以看到它的上下文有非常多的其他的关键字,我们能够突破的关键字,跟它出现在同一个上下文,而且它的数据都是一样的,所以我们通过启发式的把这些也找到了,而且这种的话很大的概率很有可能是一些开发者不小心留下来的,或者说是一些恶意的后门也是有可能的,因为它在前端其实不可见的。
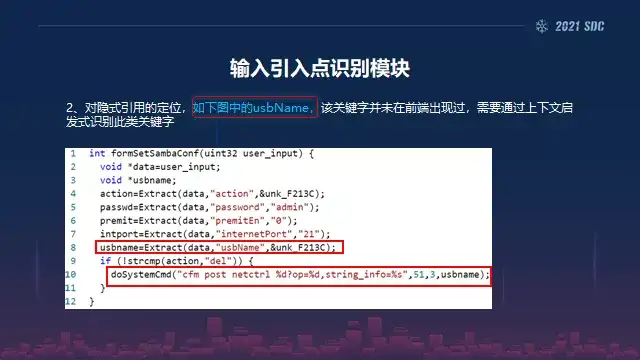
然后第三个的话这里我们要提一下,还有一个是跨二进制的,我们可以看到红色框里面的有一个关键词叫URL filter mode,其实它是跨了两个进程。
所以说这种方式的话,其实我们最开始背景里面介绍的UCSB的KARONTE的话,其实他是做了下面这一块,但是他们第一块是没有做到的,他无法从源头开始,所以说我为什么前面提到,其实我们是对他们是一个非常大的推进,就在这里。
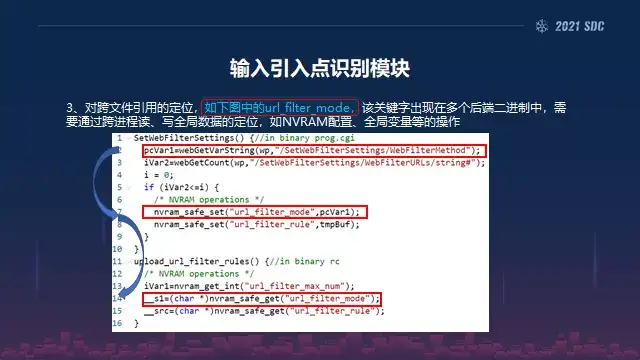
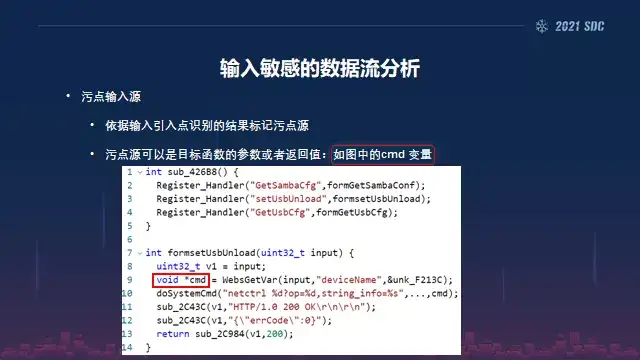
然后在关键字识别匹配出来之后,我们就要开始做一些输入敏感的这种数据流分析,我们可以得到污点的数据源,然后依据输入引入点的识别结果来标注污点源,可以是一个目标函数的这种参数,也可以使它的返回值。
比如说像我们图里面 cmd变量指针变量,这个字符串指针我们可以把它作为一个标记、一个污点源,第一步是污点源的标记。
然后第二步的话我们会关注两类这种漏洞,一类是这种内存破坏型的,还有类似命令注入,这样的话我们会对应得到不同的两类的Sink Point。
一种是类似于Memcpy这类函数,还有类似System的这类函数,就是调用这个系统需要的,可能主要面临出路。
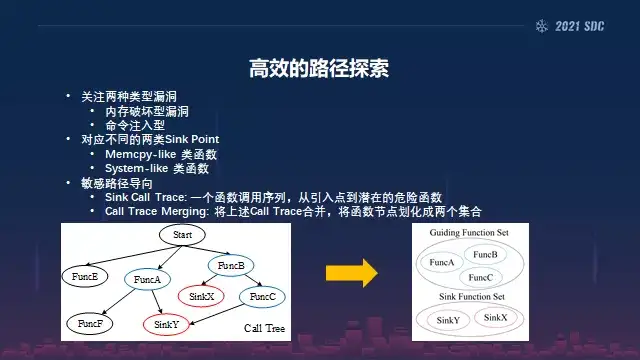
所以在这种情况下,我们会做一个整个从输入刚才我所提到的关键字的引入点到SInk Point的一个call,对所有的call trace是一个函数调用的序列,从引入点到潜在的危险函数,然后所有的call trace是我们会把它进行合并,就相当于土地这样,左边的话是一个很普通的call tree,大概有这里面有我们举了两个例子,有两个Sink Function Set,SinkX、SinkY这两个函数,所以你有很多调用序列可以到达这里。
但是我们发现如果你每个序列给到单个去执行的话,其实代价会比较大,我们就把它做了一个合并,就相当于我们不需要去运行每次的call trace,我们可以把它合并,把它改成了一个类似于塑形的探索。
然后angr其实非常也支持这样子,所以我们在右边这个函数集合里面,我们就分了两类,一类是叫改理方向,就是说碰到这种函数的话,你的符号执行引擎会step into进去。
然后下面一类的话就是一个方向去,就碰到这种自己函数的话,你就要去考察它的策略是不是出现了这种污点的违背,比如说有命令注入了对吧,注入对应的c端的函数,这个参数它是外部可以污染的。

然后我们做的是一个粗粒度的污点分析引擎,所以这是一个怎么说是兼顾效率和准确性。
然后是运行在这个指令级别,然后针对函数调用的话,我们把它分成三类,就是我们可以发现在整个你的符号执行过程中,我们把它函数分成这三类,一个是可摘要函数,比如说我们常见的这种一个c的库函数,要copy这种它是可摘要的,这样的话你直接运行它对应的这种语义就可以了,所以不需要进入它的函数内部。
然后第二个是普通函数,就是其其实就是说它是里面又没有再深层次的嵌套,函函数调用或者它的调用的是可摘要函数,所以这种函数的话我们用angr去跑的话是完全可以解决它的,这样子我们可以让它跟录进去其他工作。
然后还有一个是嵌套函数,嵌套函数就是我们这里的粗力度的这种布点分析引擎的关键的策略所在。
我们会去看如果它的参数被我们污染,然后它的返回只是一个指针,同时在后续如果被使用的话,我们会去污染反馈指针,如果不是的话,我们就污染其他的场所,这是我们的一个方法上的策略。

然后整个来说的话,我们还有一个非常大的进步,就是我们对整个路径做了一个优化,路径它所做的优化。
我们可以看到在右边的话,这是在符号使用中非常头疼碰到的这种循环函数。因为大家都知道如果你的循环变量是一个符号式的话,其实你很难去判断什么时候去接受这个循环,所以你的状态空间是一直在增长的,然后哪怕是现在用这种混合符号执行,你给他一个具体值。
但是你像刚才我们图里面这个我们图里面其实就是一个非常明显的过滤函数,就是说如果有不同的字符,它对应的策略是不一样的。
所以说在这个情况下,它的路径探索,哪怕你给它一个具体的词,它的探索的效率是非常低的,就是说他可能要运行很多次之后,才能够把BBL所有的这些里面的这些里面的这种这个函数约束取出来。就是它的分支约束取出来,所以说你很难要要求这个陆续探索期,他每次都非常精确的选择右边,对吧?他只要一选择,左边他就回去了。
所以说你要是要把右边这些标的的话全部摊下来的话,这个代价值是就是说你如果随机的话,随机的话是很难的。因为现在的这种混合符号执行的话基本上是这样,它在这个条件的时候一般是第一次选择了左分枝,第二次就选择右分枝了。
对他是这样来迭代的,所以说这样的为了提升效率的话,就会我们有一个算法,我们就会去找这种业绩点,这个业绩点就非常的有特点,对吧?它的前期非常多,然后它的后期节点是吧?这只有一个,所以他前期非常多,所以这种情况下我们有一个算法,类似于出现循环的函数里面,如果有一个比较快,它的前向节点快大于50%以上的话,我们认为这个函数就符合我们这种策略处理的特征。
我们会在探索的过程中找到这种节点之后,我们会在控制流里面直接把这个节点删掉,因为这个节点跟约束没有关系,所以这样的话反而大大提升了我们效率,把这个节点删掉之后,一次性就把它全部走回来了。
所以这是我们整个对符号执行在理论上的一些贡献。所以说我们这个方法也是得到了一些应用,在实际的过程中,特别是在你比如如果有这种ctf或者是网络这种经验的话,你找到一个命令错误的漏洞之后,可能都会想怎么去过这种制服的比例。
你要把空格、双引号什么都要放进去,但是它肯定会是有过滤的,所以这个方法就能够快速的把所有的过滤条件提取出来。
然后我们的实验评估的话大概分了这三类,我们快速的过一下,第一个就是是否可以找到真实的安全漏洞,真实设备中的安全漏洞。然后第二个就是他是否可以准确的找到输入关键字,他找到那些关键字里面有哪些是错误的。然后第三个就是污点分析的效率和准确性如何。

第一个的话我们整个看到我们是找了6个厂商14个情况,大概有39个部件里面,然后包括了两两类架构,有路由器和摄像头两大类,然后总共发现了大概有33个是新发现的安全漏洞,里面还有30个CVE、CNVD、PSV。
然后覆盖的这种边界服务的话,除了HTTP常见以外,还有HNAP是基于HTTP,然后还有UPnP。
然后对这里的漏洞类型的话,除了我们之前提到的命令出路和缓冲以外,我们还找到一些访问越界。
因为我们在提取关键字的时候,其实也会碰到客户端服务的那些跟接口相关的 F区相关的一些这种接口,我们可以去调后端的一些功能,然后有些功能其实它是存在越界的,所以我们直接就可以把它这种问题给发现出来。
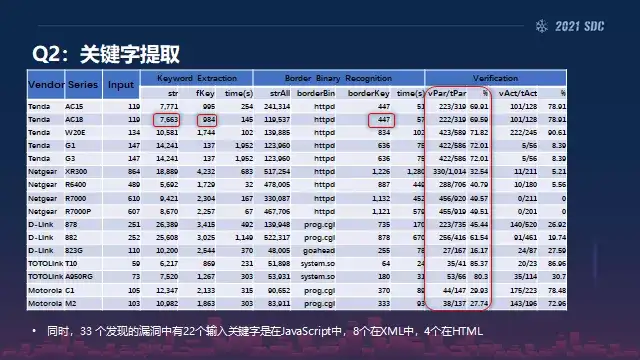
然后第二个的话关键是提取这块的效率的话,我们可以看到就结合我们人工去验证的方法,大概整个以这里Tenda为例的话,我们整个的效率就是正确的关键字,就是跟输入相关的关键词大概有70%以上是正确的。
然后我们33个发现的漏洞当中,有22个关键字是在JavaScript里面,然后有8个是在XML里面,然后有4个是HTML。
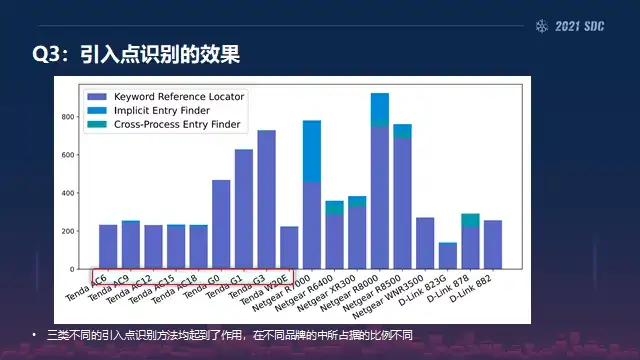
然后引入点的识别效果里面也可以看到,其实每一个厂商确实还是差别挺大的,然后你像Tenda的话可能就是第一类,所以就比较多,直接的这种识别就会比较多一点。
然后像Netgear的话好像是影视输入的,就是需要启发式算法的,然后包括 D-Link的话就是跨边界的,跨边界就是要多个版本来组合起来识别的是比较多的。
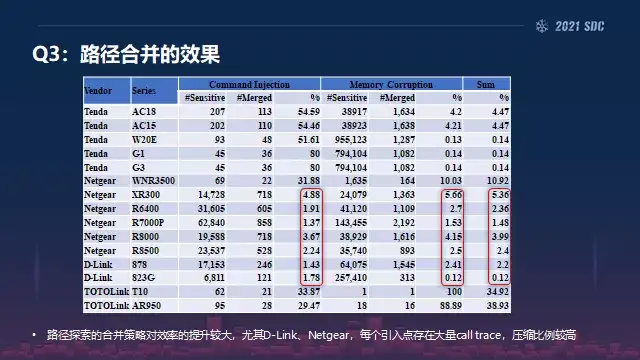
然后路径合并的效果也可以看到,特别是我们这里举红色框出来的,像D-Link的话,其实每个引入点存在的大量的trace都是在一个树里面,所以说它的压缩比率非常高,整个压缩下来只有5%不到,所以对效率的提升非常大,这也是为什么我们引擎确实能够起作用的一个原因。
然后整个的误报和漏报如何,就是SaTC的话总共是输出了101个告警,有46个确认是正确的。
然后这里的一些误报是因为缺少了一些常用函数的摘要,然后还有一些这些函数它可能就是会导致我们面临注入时就成为不报了,因为他把所有的这atoi就转换了,字符串对应的是二进制了,所以你就很难产生面临错误了,所以是这种完全我们后续可以去扩展我们这个行业摘要来支撑把这些误报给解决掉。

然后漏报的话,我们通过全量的测试,就是我们抛开效率不谈,我们把所有的关键词进行跑一遍之后,我们全量测试的时候发现确实有漏报,然后有一个是叫cmd input,这个很明显是类似的一个后门,所以说它没有出现在前端,所以我们就把它给漏了。
然后还有一个是对他的话,因为出现在很多地方,我们因为刚才算法策略的问题,我们把这种大量同时出现了,我们把它给删掉了,所以这是我被我们策略所顾上的。
然后我们总结一下,我们是提出了一种全新的这种物联网设备的这种漏洞这个方法,然后基于物联网设备中常见的这种前后端共享关键字的这样一种状态。
第三个的话就是我们是有一个系统,在实际应用中其实效果已经很突出了,我们最近在接触了一个也是我们去国家的关键基础设施的一个行业的类似于他们国家的分析,我们直接上去之后就可以报出真实漏洞,虽然说误报率大概在20%多一点,所以说还是在实际应用中效果还是比较突出的,这是我们的Paper和Slides,还有我们的代码也开源了在GitHub上面,所以欢迎各位可以有时间去试用,然后有问题的话可以随时给我们提。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号