
python 基础之scrapy 原理练习
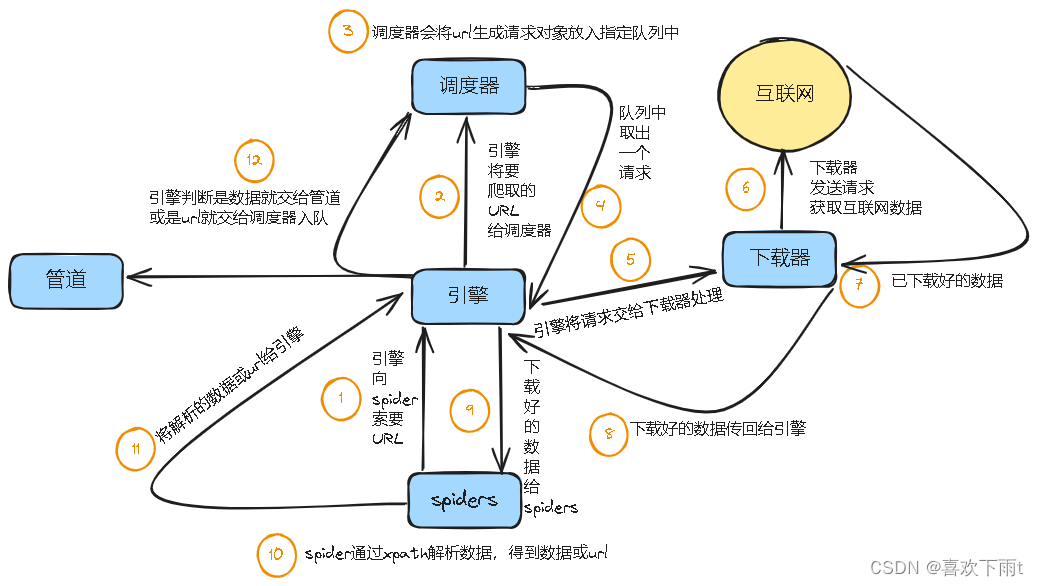
1、Scrapy Engine(引擎组件):
负责Spider、ItemPipeline、Downloader、Scheduler的工作调度、信息通讯、数据传递等工作
2、Scheduler(调度组件):
负责接收引擎传递过来的请求,按照具体规则添加队列处理,最终返回给引擎
3、Downloader(下载组件):
负责下载引擎传递过来的所有Request请求,最终服务器的响应数据返回给引擎组件
4、Spider(爬虫):
处理所有Response响应,分析提取Item数据
如果数据中有二次请求,继续交给引擎组件
5、ItemPipeline(管道):
负责[分析、过滤、存储]处理由Spiders获取到的Item数据
1、引擎向spiders要url
2、引擎将要爬取的url给调度器
3、调度器会将url生成请求对象放入到指定的队列中
4、从队列中出队一个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求从互联网上获取数据
7、下载器将数据返回给引擎
8、引擎将数据再次给spiders
9、spiders通过xpath解析器解析数据,解析到数据或者url
10、spiders将数据或者url给引擎
11、引擎判断是数据还是url,数据交给管道处理,url交给调度器处理
12、管道将数据持久化存储
新版scrapy 简单好用
import scrapy
class CarhomeSpider(scrapy.Spider):
name = "carhome"
allowed_domains = ["car.autohome.com.cn"]
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
price_list = response.xpath("//div[@class='main-lever-right']//span[1]/text()")
# for index in context:
# cat_price = context[index]
# print(cat_price)
name_list = response.xpath("//div[@class='main-title']/a/text()")
for i in range(len(name_list)):
name = name_list[i]
price = price_list[i]
print(name,price)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号