计算机组成原理—指令系统
前言:指令系统学习完后能够知道为什么我们在平时的软件会需要提供不同位数的下载包,一般的正规软件下载都会提供32位64位还有不同平台的比如windows和mac系统给对应系统下载安装。在还没学习本章知识点之前我只知道平台不同,系统位数不兼容问题,但也只是口头上说,看别人是这么讲我也这么讲,真的要了解为何是平台不兼容的根本原因说白了真的不太懂,本章学完后真的解决了我这个疑惑,并且结束本章学习后对计算机底层有了更深一层的理解。到后面了解到为何手机与电脑难以互通的原因也解开了,这一章确实学的很爽(有一定会汇编知识学起来更快)
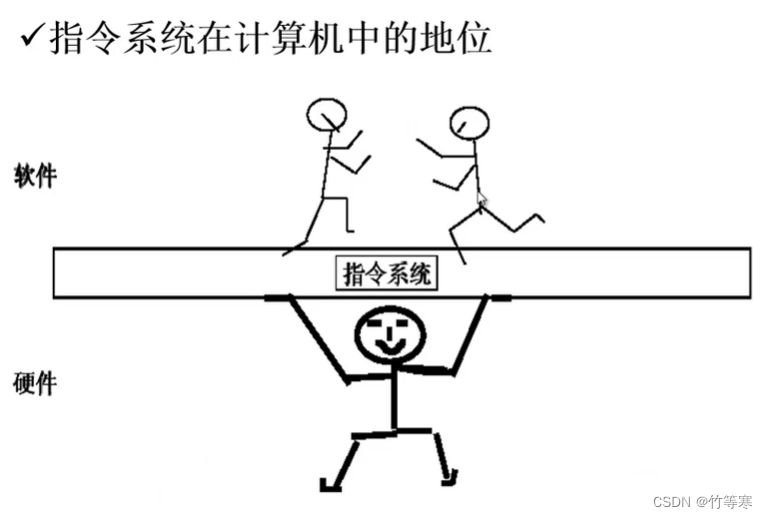
下面给出指令系统在计算机中的地位
可以看出我们的指令系统是硬件用来支撑软件运行起来的一个系统,指令系统顾名思义一定要有指令,这些指令相互配合能够完成软件也就是高级语言代码中写的功能需求,然后收到指令后,这些指令就能够让硬件识别出来要干嘛,最终完成一系列操作。
PS:忍不住说一下,就是我们代码在编译的时候会形成机器指令,编译器会完成很多转换功能,比如内存对齐,等等。
GPT3.5:如果你使用的是一种通用的高级编程语言(例如C、C++、Java等),通常可以使用针对不同平台的编译器,而不需要下载每个计算机的专用编译器。这是因为编译器会生成与目标计算机架构兼容的机器代码。
这时候我就有疑惑:那我处理器版本迭代,使用升级后的处理器的话,那我岂不是要下载对应的编译器对源代码重新编译生成可执行程序才能用?
答案:不需要,因为伟大的处理器设计者在设计处理器的时候肯定会考虑到兼容性问题,所以在很多硬件迭代的时候我们一般是不需要担心计算机运行不起来你以前的程序,因此,在学习本章之前我有了这个观点后学习指令字长是可变长度的时候不会很纠结。
机器指令
学习之前需要知道一个概念:指令集,指令集就是一堆指令的集合,指令集存在CPU中,CPU不同指令集可能就不同(但是可能可以互相兼容),因此我们学习的时候一定要注意,指令集最多也就几百条,几百条其实算多了,学习的时候只需要知道指令集的存在。
- 指令的格式
| 操作码 | 地址码 | 寻址方式 |- 操作码——用来告诉CPU你要进行什么操作,比如加法的操作码为:0001,那要进行加法操作的时候给出的操作码就是0001
- 地址码——这里说的是这数据的地址码,在需要对多个数据进行取地址操作的时候该地址码可能会有多个地址,后面会学习一二三四地址指令。
- 寻址方式——这里说的是使用哪种方式进行寻址,比如后面要学习的8086架构中的寻址方式就一大堆,烦得很,但是烦归烦,对于我们使用汇编语言进行数据的寻址访问的时候爽到飞起,我们可以通过各种方式进行寻址,可以挑选一种最快最合适或者最方便的寻址方式能够使我们编程灵活性大大提升,我相信学过汇编语言的看到这应该能很明显感受到。
注意,寻址方式的格式顺序不一定放在最后,具体放在哪里还是要根据你使用的指令系统的CPU处理格式,我们需要记住的是有的指令格式需要寻址方式的,也可以没有,并且在有的指令中可以将操作码分离出去,我们学习的知识逻辑上的格式,并不是严格的需要将操作码和地址码放在一块
- 指令字长
- 固定字长
固定指令字长常常用于RISC架构中,该架构是常用于嵌入式和移动设备,RISC架构采用了精简的指令集,每条指令执行的操作较为简单,但执行速度较快。 - 可变字长
可变指令字长常常用于CISC架构中,该架构常用于个人计算机或者服务器中,以处理更为复杂和多样化的任务。
首先提出疑问,既然我们上面提到过不同CPU指令集可能不同,我们还要搞这些固定长度和可变的,CPU处理的指令不统一那岂不是更难兼容了?
答:确实兼容性在这看来实现难度上升了,但是我们固定指令字长速度快实现起来简单,用在手机上很轻便速度很快,对于我们计算机需求比较大,需要运行多样化的任务,所以我们使用可变字长指令也是有原因的,制造成本也会很高,所以兼容不了是无可避免的,计算机还没有发展到这个程度,所以我们很多软件程序手机上的和电脑上的是不能够兼容的,因此这个疑惑解决了
PS:需要知道一点就是,CISC(复杂指令集计算机)和 RISC(精简指令集计算机)是两种不同的指令集架构,它们在设计理念和指令集特性上存在较大差异。尽管这两种架构各自有其优点和适用场景,但它们之间的兼容性并不直接指向趋势。
总结:不兼容就是由此引发,即指令可能不能够在不同的CPU上执行。
但是学到这的时候还不是很懂机器到底是怎么通过指令执行的,或者说他怎么知道我要干嘛… - 固定字长
扩展操作码技术
直接甩图,很优美的一种技术
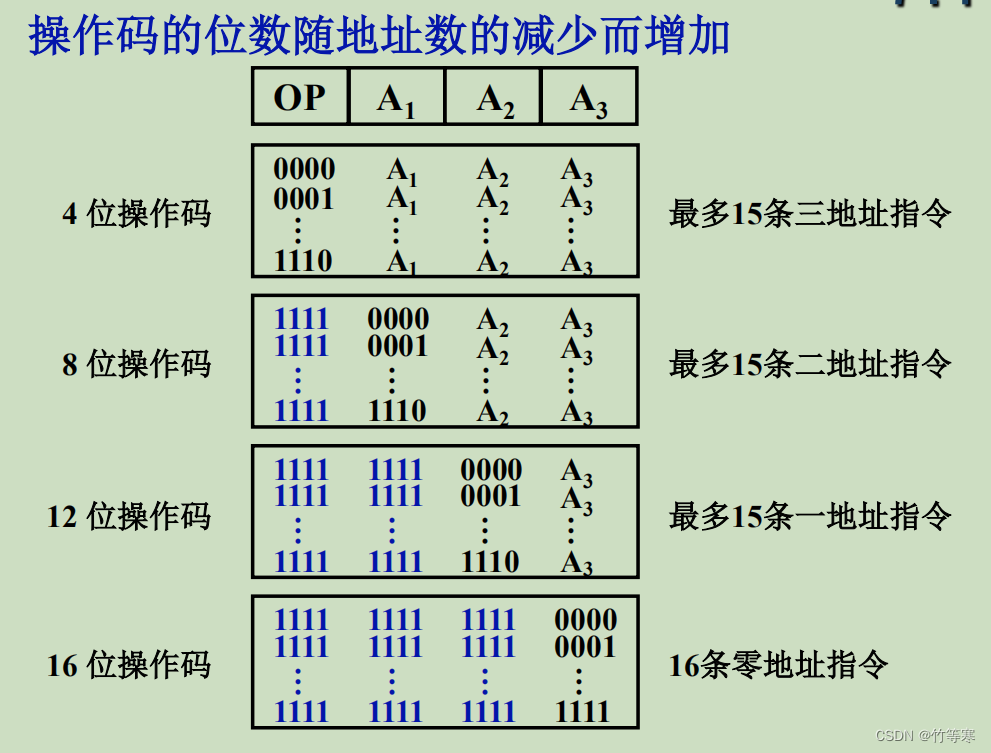
- OP是操作码,A是地址码
- 要求短操作码不能是长操作码的前缀,这也是哈弗曼编码的技术
这个操作到底是为什么?
原因很简单,我们CPU拿到可变长的操作码的时候,
比如:
8位操作码————1111 xxx
12位操作码 ——— 1111 1111 xxx
CPU判断到前面4个1的时候还不能判断到是二地址操作码还是一地址操作码,这时候只需要往后继续后面4位是否为全1即可,如果不是就是8位操作码即二地址指令,如果往后是4个1就表示是12位操作码即一地址指令,这就实现了短的8位操作码不是长的12位操作码的前缀
上面能够实现的原理是因为我们在8位操作码范围中保留了1111 1111留到12位操作码中使用,
我们8位操作码中范围是
1111 0000 ~ 1111 1110,
这导致了我们短操作码中永远不会有1111 1111这个操作码,即短操作码永远不可能是长操作码的前缀
下一个12位操作码最多能够有15条指令,是因为我们短操作码中保留了 1111 1111 ,12位操作码保留了1111 1111 1111给16位操作码当作前缀,
所以我们12位操作码范围只能够在
1111 11111 0000 ~ 1111 11111 1110即15条
- 疑问:我们一定要按照这个方法分吗,我二地址只能够存放15条操作地址?这不是规定死了?
当然不是!上面只是举的一个例子,假设我们要把一地址即12位操作码存的地址范围扩大,我们只需要让表示二地址的前缀变小就行,即我们二地址中保留1111 1110给我们的一地址,即二地址范围最大到1111 1101,那我们的一地址就能从1111 1110开始,即
1111 1110 0000 ~ 1111 1111 1110
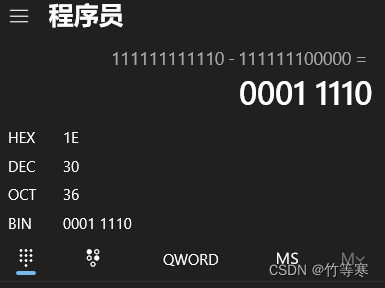
这个范围数一下会是由31条指令,二地址前缀是1111 111以前是1111 1111,所以我们通过减少二地址的地址范围来增大一地址的地址范围
PS:等于30的原因是因为没有加上1111 1111 0000,
比如你要计算3~2有多少个数字,3-2=1,但其实范围是3 和 2 ,2个数字
事实上:当短操作码每减1来保留给下一个长操作码他会增加24,这里的4次方是取决于你每一个A地址码有多少位,这里例子是4位,就表示每次短操作码减一就会让下一个长操作码范围增加24。
- 总结一下:假设学到这不懂,需要去学习一下哈夫曼编码原理就知道怎么回事,说白了就是通过短操作码最大的那一个数,不能够是下一个长操作码的前缀就行了,或者反过来说长操作码前缀不能够是最大的那个短操作,这样短操作码就永远不会是长操作码的前置(领悟这个还是有点难度)
防止我以后会忘记,再聚一个例子:(假设我让短操作码减1用来保留给长操作码)
短操作码: 1111 0000 ~ 1111 1110 (保留了 1111 1111)
长操作码: 1111 1111 0000 ~ 1111 1111 xxxx
可以看到我们CPU在查找操作码的时候如果看到1111他只需要继续判读那下四位是否为全一就可以知道是短操作码还是长操作码了,因为长操作码的前缀不是短操作码范围中任何一个码
注明:我这里长操作码中写x的意思是我可能还会有比长操作码更长的操作码,所以不确定这里的长操作码最大是哪个。
- 还有一个疑问是:这玩意学着有啥用?
首先!这种技术是用在CISC中的,在位数不改变的情况下,丰富指令集系统,因为在分一地址二地址三地址等等的时候,我们只是操作码位数增加,地址位数减少,但是实际上我们总的位数没有改变。
GPT3.5:扩展操作码指令的思想是为每个基本操作分配一个操作码,然后使用额外的字段来指定操作数和其他参数。这样,可以通过扩展操作码的方式在不增加指令数量的前提下,逐步引入新的指令。这种设计使得架构可以灵活地扩展,同时仍然保持对现有指令的向后兼容性。
其实我认为最重要的是能够在丰富的同时,向后兼容是最牛的,即我们在升级CPU指令集的同时,以前的程序还能够继续使用新的CPU指令集进行运行起来,而不是说升级了就以前的程序也用不了了,这是很痛苦的事情。
补充
这里其实还没有说可变长指令集怎么被CPU执行,下面的学习中体现的也不明显,我觉得很有必要解释一下!
首先可变长的指令肯定是在CISC架构中,假设一个短指令地址,CPU地址线位数还短,我们这时候会采用补充技术对位数进行补充或者CPU会有解码技术将其解码为对应的指令地址,在很长的指令地址中,我们CPU怎么读取呢,其实也不用担心,我们的CPU会分几次读取,直到读完一个完整的指令地址,总之我们在可变字长指令中也就是在CISC架构中不用担心指令地址不同的情况,我们一定有办法找到对应的指令,只是性能上肯定会丢失,同时设计硬件电路复杂度也会大大提升而已。
地址码
这个技术能够使我们一条指令能够通过给出操作数个数不同执行不同的操作。就好比一个函数中可变参数一样。


这种技术按照需求来设计,换句话说有了这种设计后我们想要扩充一个指令能表达多种意思的时候方便很多,比如一个汇编指令中:
MOV AX, BX ; 将BX的值移动到AX
MOV ECX, EDX, 4 ; 将EDX中的值移动到ECX,并指定复制的字节数为4
一个指令可以通过操作数的个数不同去执行不同的操作
- 这种设计的优点
- 向后兼容
很明显,我们不用管以前设计的指令,我们只需要对操作数那部分切割或者合并就行,一个指令可以有不同的表达方式,即使更新了新的指令,以前的照样可以使用 - 能够减少指令数量,因为我们在增加新的指令操作仅仅只是在原有的指令操作码的基础上,改变了操作数个数,用这个特点来改变一个指令执行不同的操作,就不用另外的增加一个操作码指令来执行,这也让我们编程灵活性增加,记忆的指令也不用很多(话是这么说)
- 减少访问次数提升速度
- 向后兼容
这个我就要好好唠唠了,减少访存次数在四地址转为0地址或者一地址过程中可以发现,我们是不断减少了访存次数,原因是我们把操作数存放在了其他地方,ACC或者其他寄存器中,我们在执行本条指令的时候就会发现我们访存次数减少了,因为有的操作数放在了寄存器中,我们直接让寄存器中的数据交给运算器执行就行,而不用多次访存。
吐槽:其实这个我认为只是相对于本条指令来说减少了访存次数,因为你将数据存入寄存器中也是需要访存的,所以说总体来说访存次数本质上没有减少,只是对于该指令来说,我需要访存的次数减少了。
但是我们仔细想想,确实会提升速度,因为可能你在运算的结果放在寄存器中,下一条指令需要用到的时候真的是减少了访存次数。
数据存放方式


- 主要说下面的存储方式

- 边界对齐
在学习C语言中都知道我们的结构体会有内存对齐方式,在这里也是,假设我们存的是字节,那么我们就需要在内存中以字节倍数的起始地址找是否有空位就存下来,一个字就以一个字的倍数进行找地址,有空位就存下。这个寻找空位的操作编译器会帮我们找好,你在编译一个程序的时候他就会帮你存好,将内存利用率提高,就是说我们的编译器不会让你的程序产生过多的空余空间。
(那我们如何通过编译器编译好后各种不同的数据存放的位置,因为有可能一个存储单位中有多个不同的数据?
答:我们编译器编译好后的机器指令已经是帮我们设定好了各种访存地址,使用相对寻址就可以在不同计算机中运行的时候防止地址不同的情况!) 总之编译器是神!真的和牛,编译器一般都能够在不同平台根据他的指令集或者操作系统编译出对应可执行程序。
注意:机器字长和存储字长不是一个东西,机器字长是CPU寄存器的宽度位数,而存储字长是CPU的数据总线,这一点理解很重要。
寻址方式
需要提前说明的是,下面会学很多种寻址方式,计算机需要这么多寻址方式的目的是:提高编程灵活性,方便在特定的场合使用特定的寻址方式,灵活且方便
指令寻址
程序计数器(用来标识程序当前要运行的指令的地址),常用PC表示,不要记错的是,PC记录的是指令的地址,也就是说我们要找到该指令的地址才能让程序按照我们想要的逻辑顺序运行下去。
-
顺序寻址
特别注意,PC计数器通常在指令执行前就指向下一条要执行的指令地址,顺序执行会让PC自增,但是自增的长度会因为当前指令的字长,假设该指令字长为"1",那PC就自增"1",有的指令会很长,所以就需要看指令长度自增,所以这里我们说的自增1其实是一个逻辑上的1,指的是下一条指令。 -
跳跃
JMP 指令地址
汇编语言中的无条件跳转指令,这就是一个跳跃寻址的操作,通过JMP后面的指令地址交给PC程序计数器,这样程序计数器就会跳跃到该地址中执行改地址指向的指令。
说白了指令寻址很简单,PC程序计数器存的就是下一条指令的地址,我也不明白还要硬说两个顺序和跳跃寻址出来,确实没啥好说的,就很简单的修改程序计数器地址来控制执行流程而已。
操作数寻址
-
立即寻址需要注意的是我们在汇编语言中如果看到#的话就是立即数寻址而是给出地址,有时候在对一个程序进行反汇编后可能会很多时候看到这个符号,我们需要知道他是立即数就行,即这个数就代表数值大小不是地址。

-
直接寻址

-
隐含寻址意思是我们一个指令是对多个操作数进行运算的时候指令中只显示的写出了一个操作数,另外的操作数隐含的存放在了其他寄存器或者外设中。比如我们汇编指令的乘法指令,只需要给出乘数,而被乘数在乘法指令执行前就应该被存放在AX寄存器中
MOV AX, 5 ; 将被乘数加载到 AX 寄存器
MOV BX, 10 ; 将乘数加载到 BX 寄存器
MUL BX ; 无符号乘法,结果存储在 AX 和 DX 寄存器中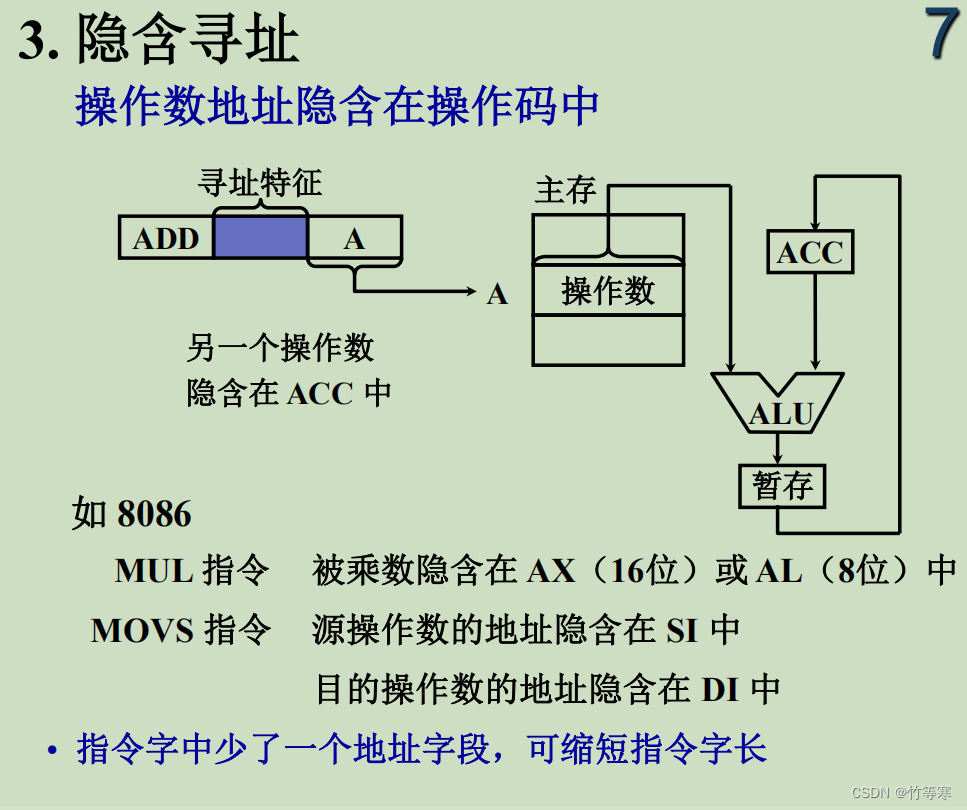
-
寄存器寻址就是把地址放在寄存器中,用寄存器里面的操作数数值,而不去内存中访问找内存中的操作数数值。
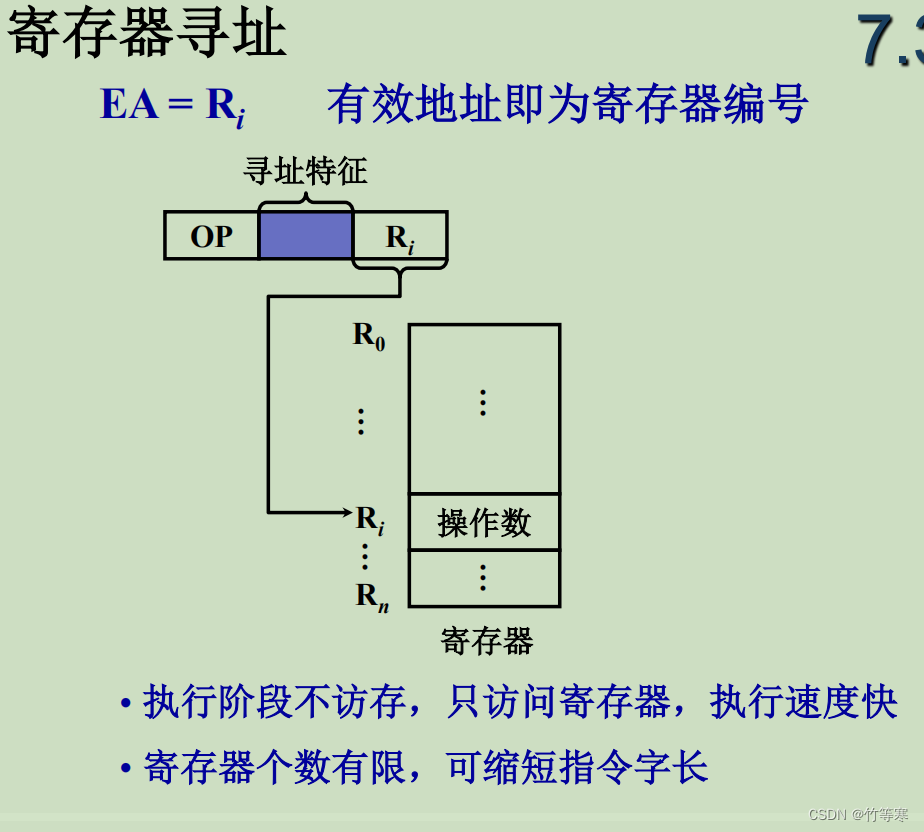
-
间接寻址中,其实我十分纠结,因为我不明白为什么会有不使用寄存器的间接寻址,后来我查了很多资料,发现我们一般情况下都是使用寄存器存好一个地址后再进行间接寻址的,我猜是因为在教学,所以不使用寄存器更容易解释间接寻址的知识点。
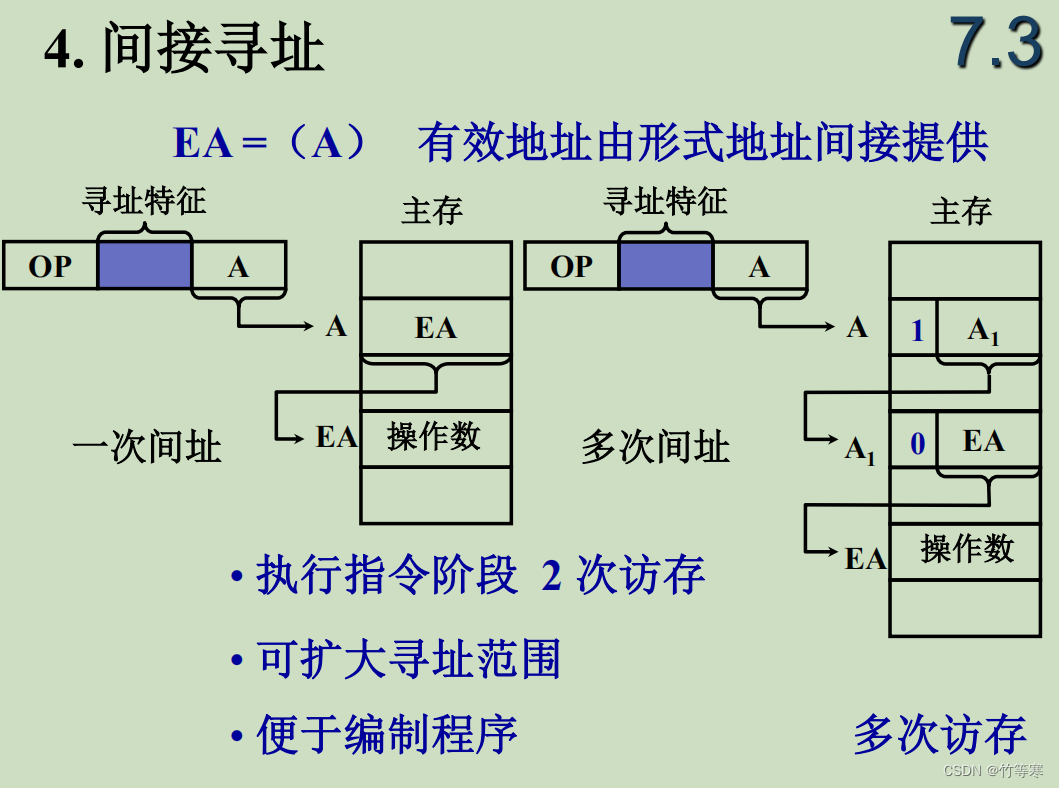
这里多次间接寻址中使用了一个标志,在每个访存到的操作数中有一个0或者1,1表示还需要拿当前的操作数作为地址进行间接寻址找到下一个,一直到那个标志位为0,在这里我想解释一下据我所了解到的知识:在实际中没有这么一个标志,都是我们在程序设计中自己设计多次间接寻址(起码在汇编中是这样),同样我们也不要觉得标志寄存器中有这样一个标志,都是没有的,终止条件通常是通过程序中的逻辑检查来确定的。
寄存器间接寻址一直是我们汇编中用的,所以我们几乎没有看到过间接寻址是像上面的间接寻址那样直接使用一个内存地址,如果在汇编中直接使用一个地址的就变成了直接寻址方式了。我们只能当作是教学需要才弄出来的,但我们自己知道一般都是采用寄存器的方式间接寻址即可。
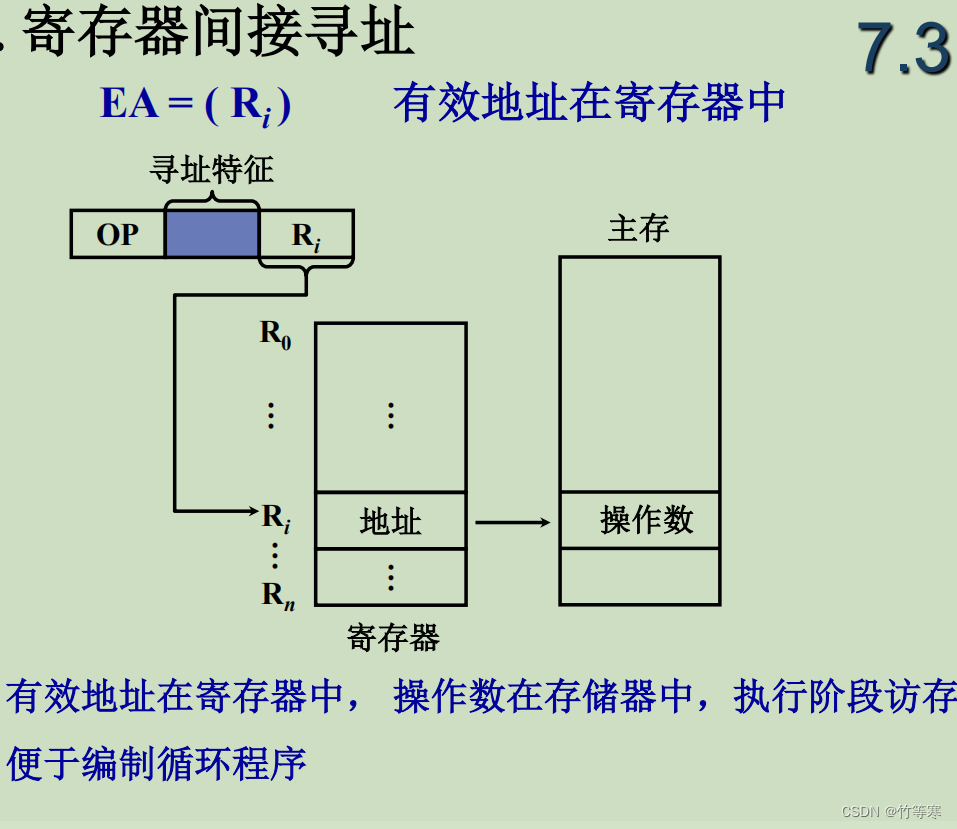
总结一下间接寻址:首先设想一下不使用间接寻址的话我们的地址肯定只有指令地址中的操作数地址部分,表示的地址范围很少,如果我们使用间接寻址的话用一个地址指向主存中存的空间,那个空间存的也是地址,这个空间又肯定比指令地址中的操作数地址大,所以也就是说我们使用间接寻址的寻址范围大大增加了
还有另外一个优点就是编程的灵活性提高了,我们使用间接寻址,我们在指令地址中不必修改操作数的地址,我们只需要修改主存中的数据范围即可,我们使用指令中的操作数地址访问的还是那一个位置,我们的数据可以随时根据需求改变。
个人感受:其实学到这能够明显的感受到编程的雏形了,我们使用的变量之所以如此方便和常用,可能也是来自寄存器的原始模型,因为使用寄存器来访存十分方便。 -
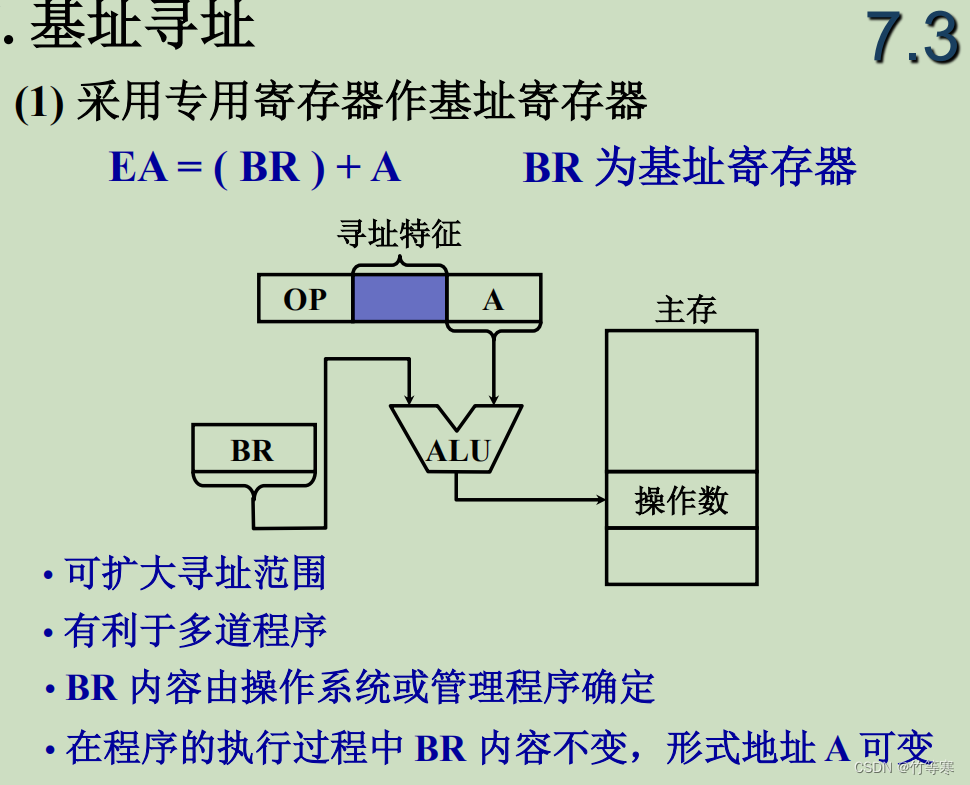
基址寻址是一个规定的地址,假设我们定好了就不可以轻易改变,否则很多数据又要重新定位。同时需要注意的点是,基址寄存器不是!不是!不是段寄存器,他和段寄存器不一样,基址在汇编中可以是一个地址,
比如:MOV AX, [基址 + 0x12345],这个基址的意思可以直接是一个地址,也可以是一个寄存器比如可以使用BX,基址的意思是我们根据给出的这个地址,按照这个例子,我们隐含了一个段寄存器DS,根据段寄存器给出的段,然后我们用一个基地址,是在该段中的一个基地址,然后根据基地址访存附近的数据。(这里需要注意一点,我以前一直以为基地址不就是段地址吗,所以导致我一直不理解为什么基地址寻址还可以不变)
“不变“的意思这里也要解释一下:这里说的是一旦定下来了我们就不可以轻易改变基地址,因为我们要的就是一个基准地址,你还要临时改变他这不是自讨苦吃吗?所以我们只要定义了基地址,无论是你直接给出地址还是存放在寄存器中使用寄存器当作基地址来用,都是不可以随意更改的意思。
-
变址寻址和基址寻址十分的相似,甚至我觉得他们没有区别,只是在理解方面有区别,使用的时候我们能够知道什么时候使用基址寻址和变址寻址。
变址寻址是给出一个固定地址,这个固定地址就是基地址,所以到这我认为和基地址寻址没啥区别,但是他加了一个可变寄存器,那么通过这个可变寄存器能够实现动态改变地址,举例子:MOV AX, [BX + SI],这里的SI可变寄存器就是一个可变的地址,而在我们基址中,第二个不是一个可变寄存器,基址寻址中而是直接给出一个常量地址。通过这样举例子解释后勉强能够接受这个知识点了。
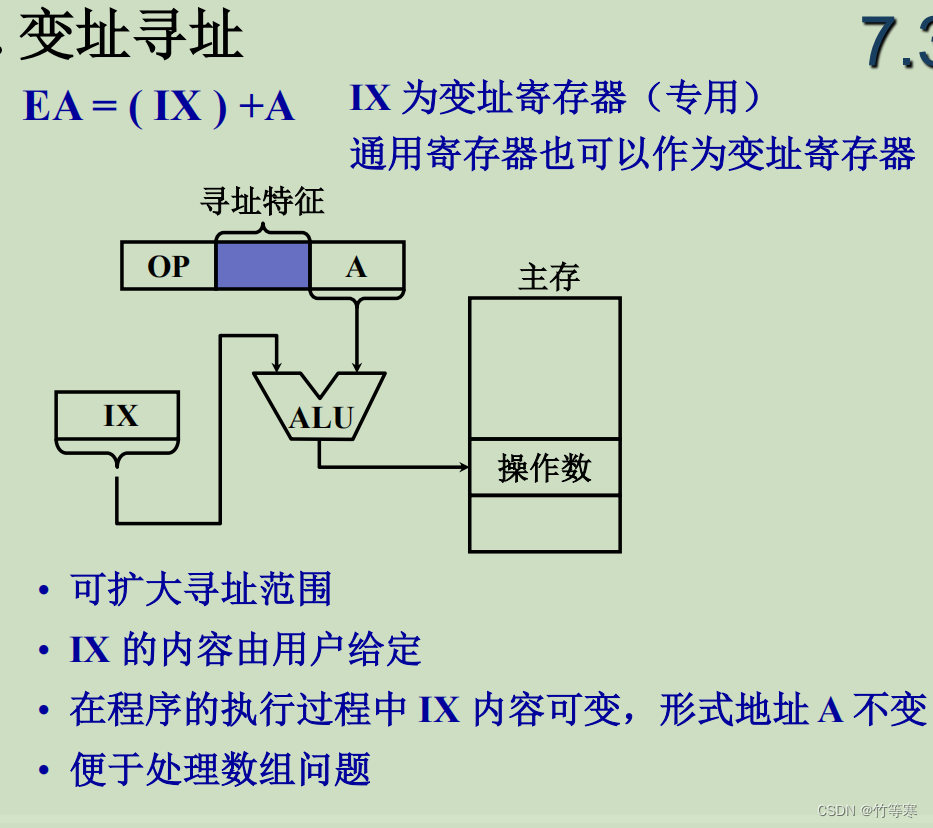
-
相对寻址,在相对寻址中,给出的操作数是一个相对于当前PC程序计数器的位置偏移量,也就是可以理解为我们把当前PC的地址当作基地址然后取出操作数作为偏移量进行访存,该偏移量肯定是可正可负的。
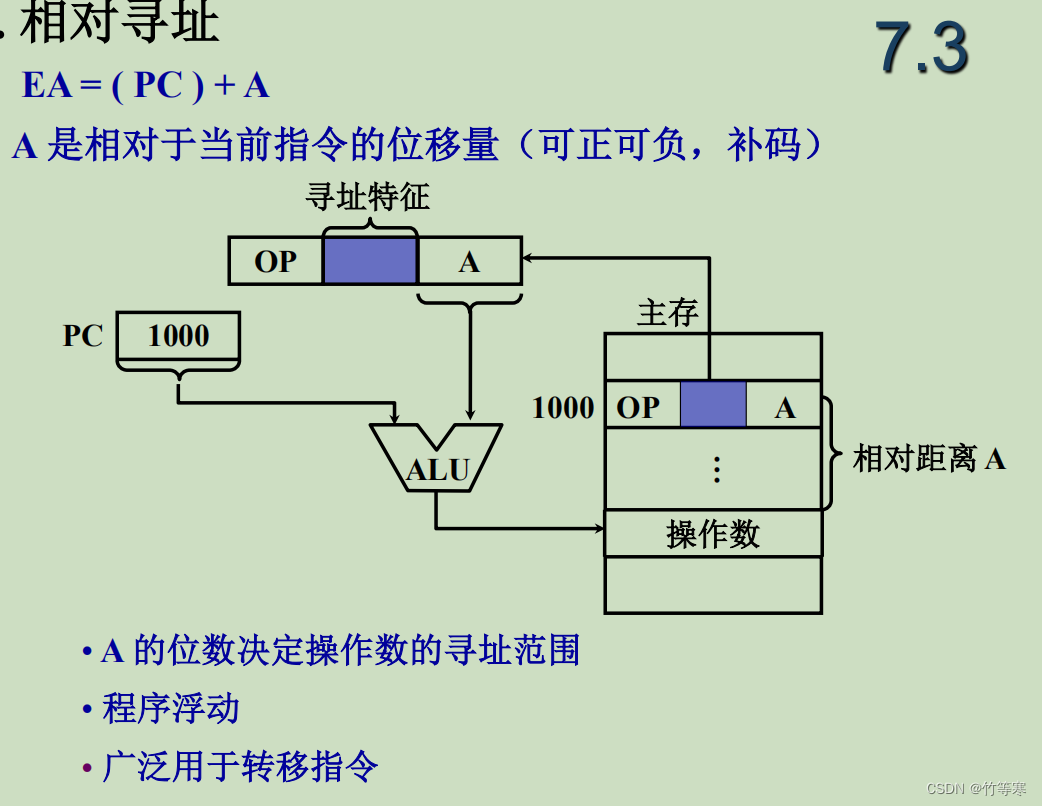
-
堆栈寻址
最后一个寻址方式
在该寻址方式中,我们只要学过出栈入栈是先进后出就行了
其次就是我们寄存器SP是用来保存栈顶,BP寄存器保存栈底部
然后我们栈底部是高地址,栈顶部是低地址为什么我们的函数参数在进栈的时候总是先把排在最右边的进栈?也就是说越靠后的参数先进栈? 我的解释是:因为栈是先进后出的,所以我们把右边的参数先进栈,左边的参数先出栈,那我们在用参数的时候就可以先用左边的,因为按照人类的思维想就是从左到右边数的,所以用的时候我们也理应认为是先从左边的参数先用所以就是为了先用左边的参数而先把右边的压入栈中,先进后出。
GPT3.5:在某些情况下,函数参数是从右往左(后往前)依次压入栈的,这样做可能与函数的调用约定和处理器体系结构的规定有关。这种方式的一个可能的原因是与C语言的语法规定相一致,因为在C语言中,函数的参数列表是从右到左进行的。
另一种方式是从左往右(前往后)依次压入栈。这可能取决于具体的编译器和目标体系结构的实现。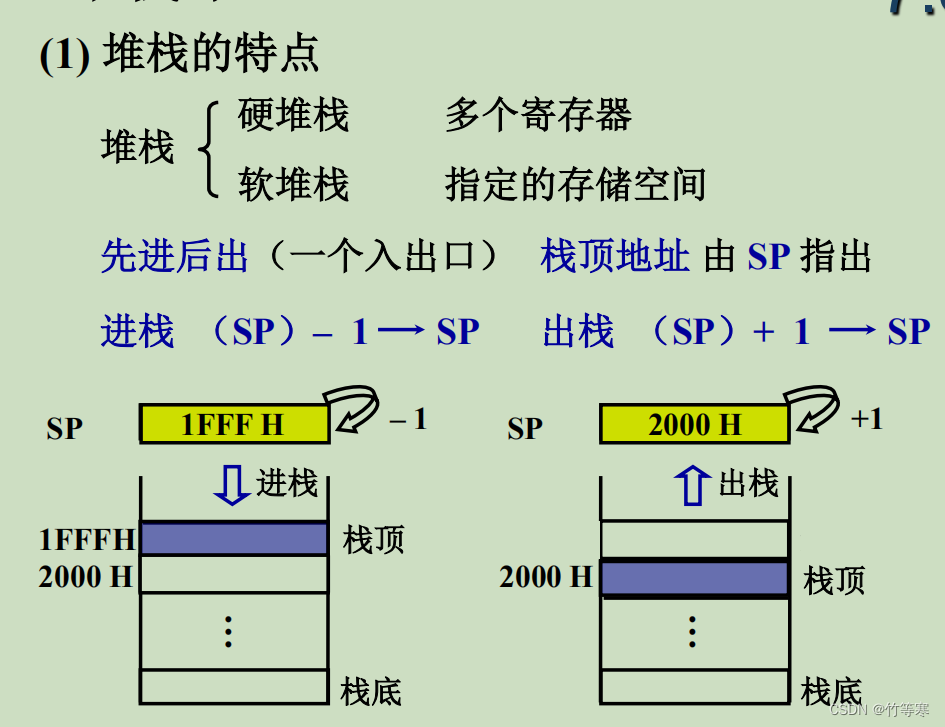
-
在这里可以看到我们SP移动多少是根据编址的大小,举例子:我们C语言中的指针自增后移动多少取决于当前操作系统的位数,32位计算机下的指针通常是4字节,64位的指针通常是8字节等等。

两种架构
总结写在前头:
RISC架构是固定指令字长,因为每一个指令都是固定长度,所以我们CPU在执行的时候不需要像CISC那样要考虑指令的长度,所以速度肯定是很快,并且指令集也很简单,简单的原因是因为固定了指令字长所以注定了该RISC架构中不会有很复杂的指令集,制作CPU的时候也会变得简单且轻便,所以经常用于嵌入式或者移动设备中,我们手机就是使用的RISC架构ARM处理器,精简指令集。
对于CISC中,可变长指令字长,因为字长可变,所以指令集指定丰富且复杂,由于指令集的丰富所以很适合我们计算机使用,因此我们的intel处理器就是使用的CISC架构,复杂指令集.
首先引出一个结论:
由于指令集不同,指令集不同是因为指令地址长度处理不同,所以注定了这两个处理器之间运行的程序难以得到兼容,所以我们可以看到有一些软件下载官网中提供了不同的下载版本对应不同的操作系统和处理器
但是真的无法兼容吗?答:目前看起来是难以实现的
它们在设计理念和指令集特性上存在较大差异。尽管这两种架构各自有其优点和适用场景,但它们之间的兼容性并不直接指向趋势。
最后还有一个重大领悟就是:我终于知道了为什么说能够向下兼容而不能向上兼容,因为新技术只能包庇旧技术,旧技术不能够兼容新技术,不仅仅是因为操作位数不同的问题,更新后我们的指令系统就已经不同了,很多用到的指令压根无法在旧指令系统中运行起来,同时也知道了为什么windows和macOS很多都不兼容,首先CPU不同,其次CPU里面的指令集不同,就无法兼容,我们的程序无法做到同时兼容两种操作系统,所以我们只有一个办法那就是用不同的平台上编译器重新编译一份符合你本机操作系统处理器(CPU)指令系统能够识别的能够执行的程序。
总的来说,这个重大发现对于我来说十分重要,至此我能够明显感受到确实在不断深入了解计算机底层原理了。
-
RISC


-
CISC

-
CISC与RISC比较(给出王道视频中的,写的很清楚很好)
补充:有一个很明显的区别是在复杂指令系统CISC中可以随便访问内存,很多指令都是可以对内存访问,但是到了精简指令中RISC就不可以,每次访问内存都要用特定的指令Load或者Store
还有一个细节是,我们为何精简指令系统中,能够用于手机上面,明明我们手机也很复杂。原因很简单,就好比给你一个编程语言中最简单的几条语句,你也可以实现很多功能,也就是说我们可以用指令系统提供的指令来编写更复杂的指令。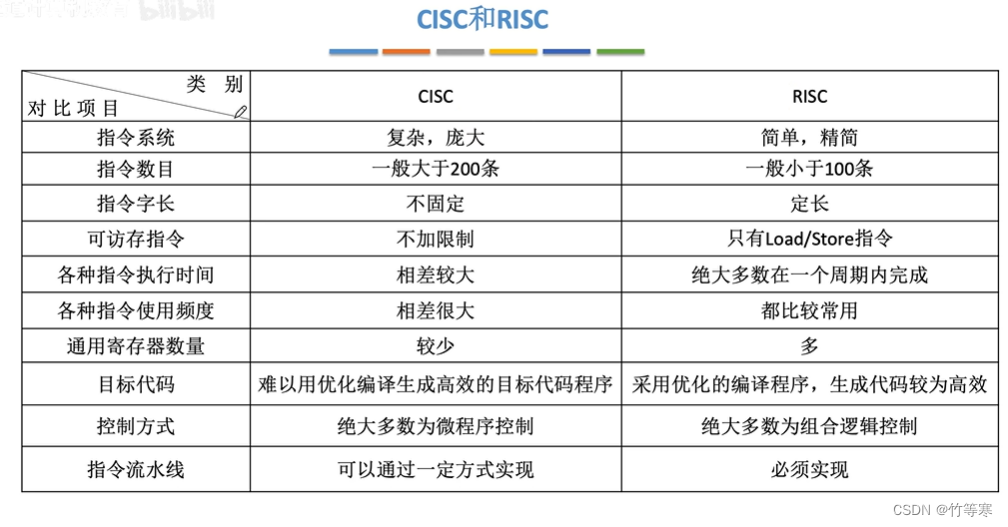
-
解决最后一个疑问:假设我电脑采用ARM处理器,那么我们手机上一般都是使用ARM处理器,那是不是说明我们这个ARM处理器的电脑上面可以运行手机上面的软件?
不一定,其实上面我忽略了一点就是我们计算机使用的操作系统不同的话我们软件之间可能调用的不同操作系统的函数API(手机采用Android系统),就会导致程序运行不起来,就算我们一个程序中没有调用操作系统中的API,那我们每一个操作系统的文件管理系统也会出问题,再假如你这个破程序不会用到文件管理方面的,你运行起来一个程序的时候,界面也会因为不同操作系统使用的GUI不同导致错乱等等,种种原因都会造成不兼容。
但是!但是!还真有一种程序既能够在计算机windows和macOS中运行还能够在手机安卓中运行,这种就属于是程序设计者考虑的,上面所说的都是一种软件程序,还有一个就是Web应用程序,Web是任何手机都能够访问,而且网页对于不同系统根本没有区别,只要IP地址一样访问的都是同一个网页,通过浏览器访问,可以实现跨平台,等等还有很多
兼容性难实现,但是有时候发行不同操作系统版本的也不为是一种解决办法,因为我们要保证运行流畅性,假设要兼容,肯定会放弃掉一些性能方面的,即使不会丢失,那设计起来也会十分困难。
本文来自博客园,作者:竹等寒,转载请注明原文链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号