
Chinese Word Semantic Relation Classification 中文词语语义关系分类
一、任务描述
任务提出是NLPCC2017提出,题目为:
Chinese Word Semantic Relation Classification :
http://tcci.ccf.org.cn/conference/2017/dldoc/taskgline01.pdf
项目测试数据集:
https://github.com/wuyfpku/Chinese-Word-Semantic-Relation-Classification/blob/master/Test%20Data
形式化,给出一个context-free word pair,判别词语对的语义关系,目前限定为限定域内的关系分类,有antonym(反义词)、synonym(同义词)、Meronym(部分关系)、hyponym(上下位)、None。
二、研究现状
1.Classification of Chinese Word Semantic Relations
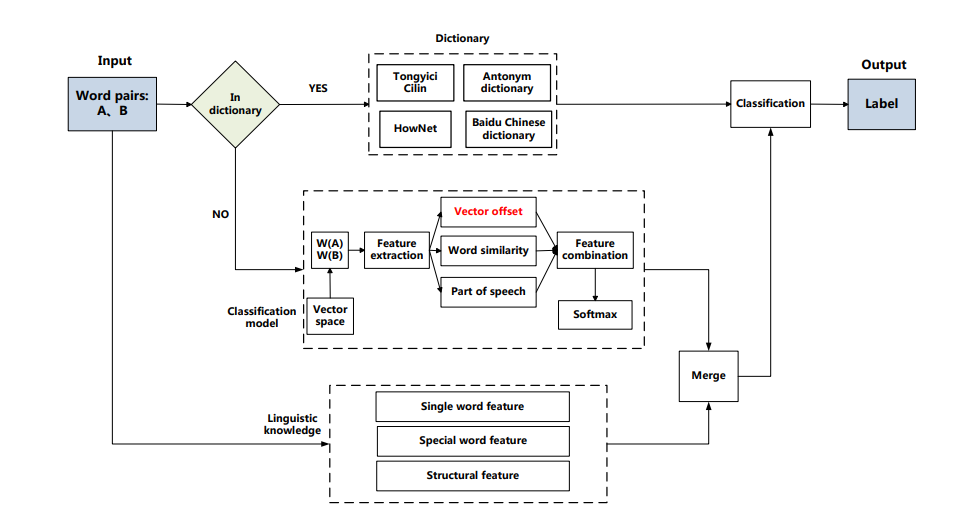
思想描述
主要是通过一个if-else. 首先,针对两个word判断在不在词典(词典主要有大词林、hownet、百度(http://hanyu.baidu.com/s?wd=高兴&from=zici) 等),如果存在直接返回关系;否则通过词嵌入(融入了词向量相减(女王-国王=?这类的信息)、cosine相似度和词性编码(名词or形容词...))通过简单的softmax完成。
同时添加了中文词语知识(“A(树) and AB(树枝)”;A(蛇) and BA(海蛇)和A(花) and BCA(玫瑰花);去除特殊字符(子对于桌子);单个字的为反义;)这种后处理强制进行基于分类器结果的纠正。
2. Hypernym Relation Classification Based on Word Pattern(此论文只关注上下位关系的判别)
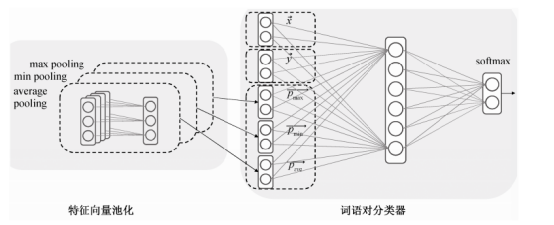
思想描述
由于NLPCC2017任务中只提供了词对,此文通过在文本中进行词对的匹配,希望融入一些上下文信息,将实体x和实体y之间的单词视为模式,将模式之间的单词,通过最大池化、最小池化、平均池化操作串接,结果与x,y串接,通过一个简单的前馈神经网络,完成是否是上下位关系的二分类任务。
3.Effective Semantic Relationship Classification of Context-free Chinese Words with Simple Surface and Embedding Features
特征工程
1.长度特征(|A|, |B|, |A| − |B|, |B| − |A|, |A ∪ B|, |A ∩ B|);
2.词语相似性:Jaccard系数、Dice系数、Overlap系数
3.位置特征:A,B两个词语,从前缀与前缀、前缀与后缀、后缀与前缀、后缀与后缀8个特征(前缀和后缀分别长度为1,2)
4.序列覆盖:最长公共字串。
5.词向量:
串联、相乘(相加、相减、最小池化、最大池化、平均池化 这几类性能不好)。长度为100
6.字符向量:相加、相减(串联、乘减、最小池化、最大池化、平均池化 这几类性能不好)。 长度为300
分类器
SVM,SGD,XGboost。
4.Study on the Chinese Word Semantic Relation Classification with Word Embedding
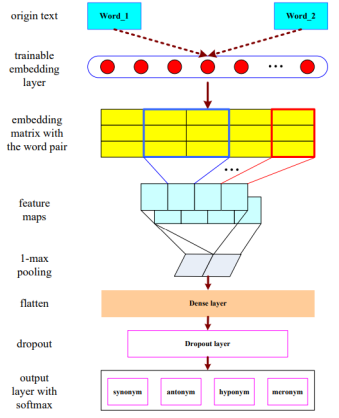
思想描述
采用word2vec,在百度百科和维基百科的预料上完成单词的预训练。采用标准的CNN实验:
三、总结
目前解决词义关系的论文不多,基本的研究现状都是通过词向量这类有一定语义关系的表示完成分类的操作,同时辅助汉语本身的语言的特性辅助。
反义词词典及实现:https://github.com/liuhuanyong/ChineseAntiword
同义词: https://github.com/ashengtx/CilinSimilarity/blob/master/source/cilin.py
https://github.com/BiLiangLtd/WordSimilarity
https://github.com/chatopera/Synonyms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号