
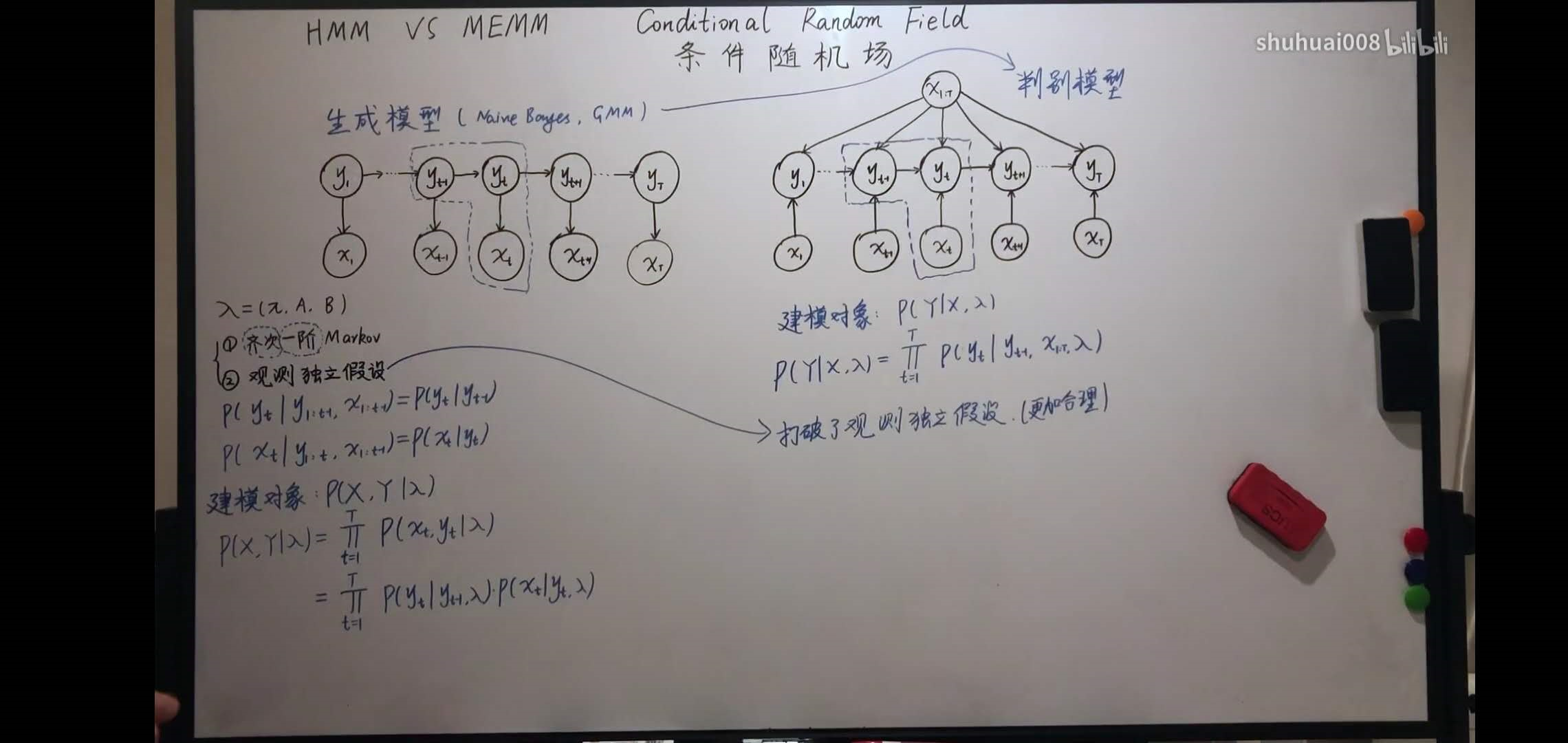
CRF从HMM的演进
1. 首先,HMM是一种生成式模式,它通过对p(x,y)进行联合建模的过程。
他有两个假设,齐次一阶的markov;观测独立假设。
但是:
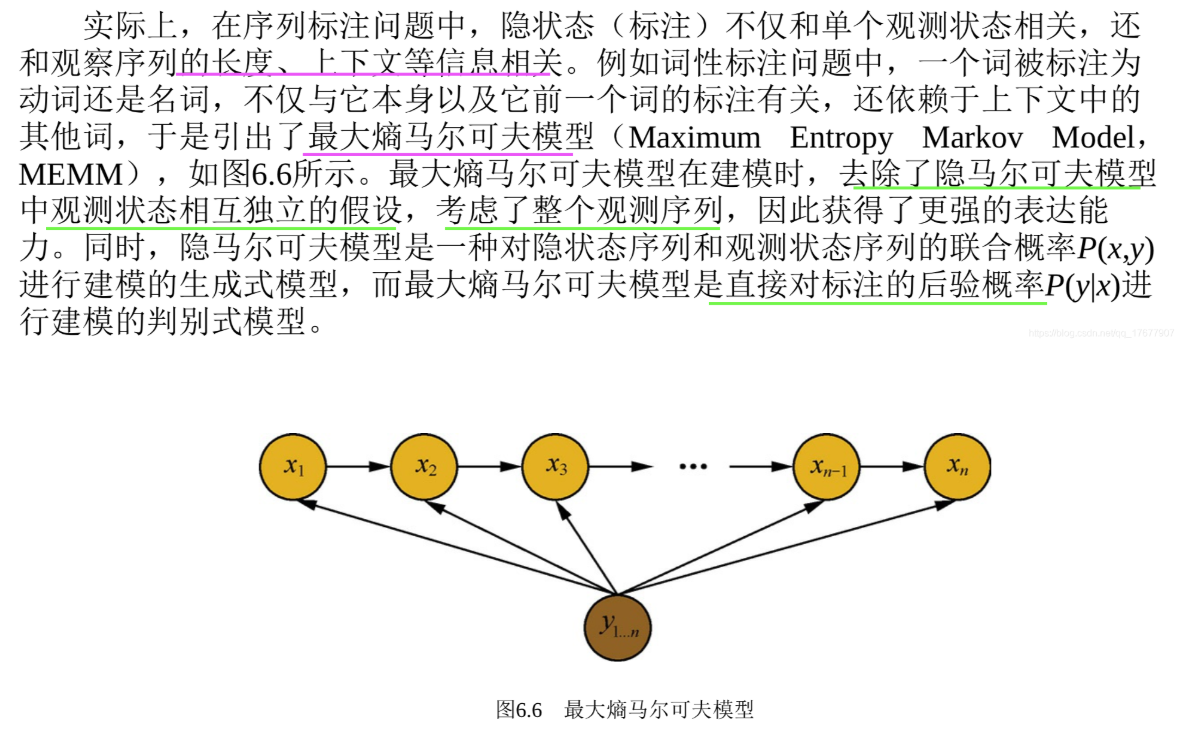
所以说,MEMM打破了观测独立性假设,通过引入了P(x|y)进行建模的判别式模型。
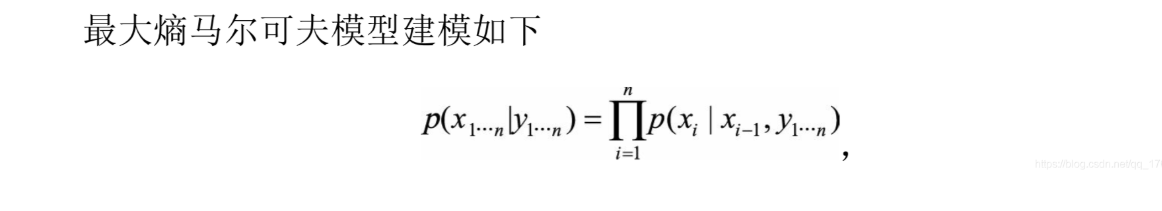

但是MEMM又有一个非常严重的问题,就是标注偏置问题。总的一句话就是:熵越低的条件分布,越不关注观测序列。
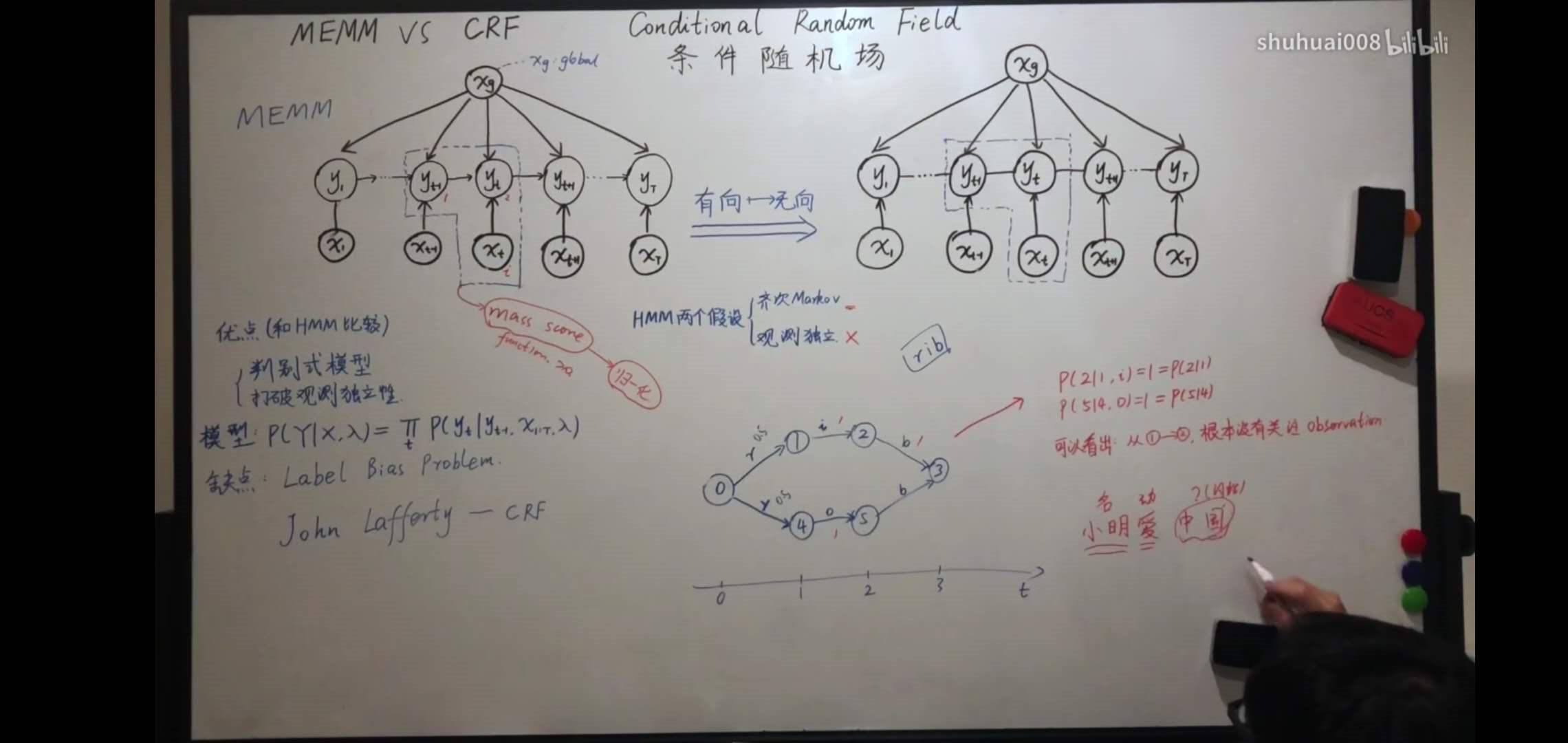
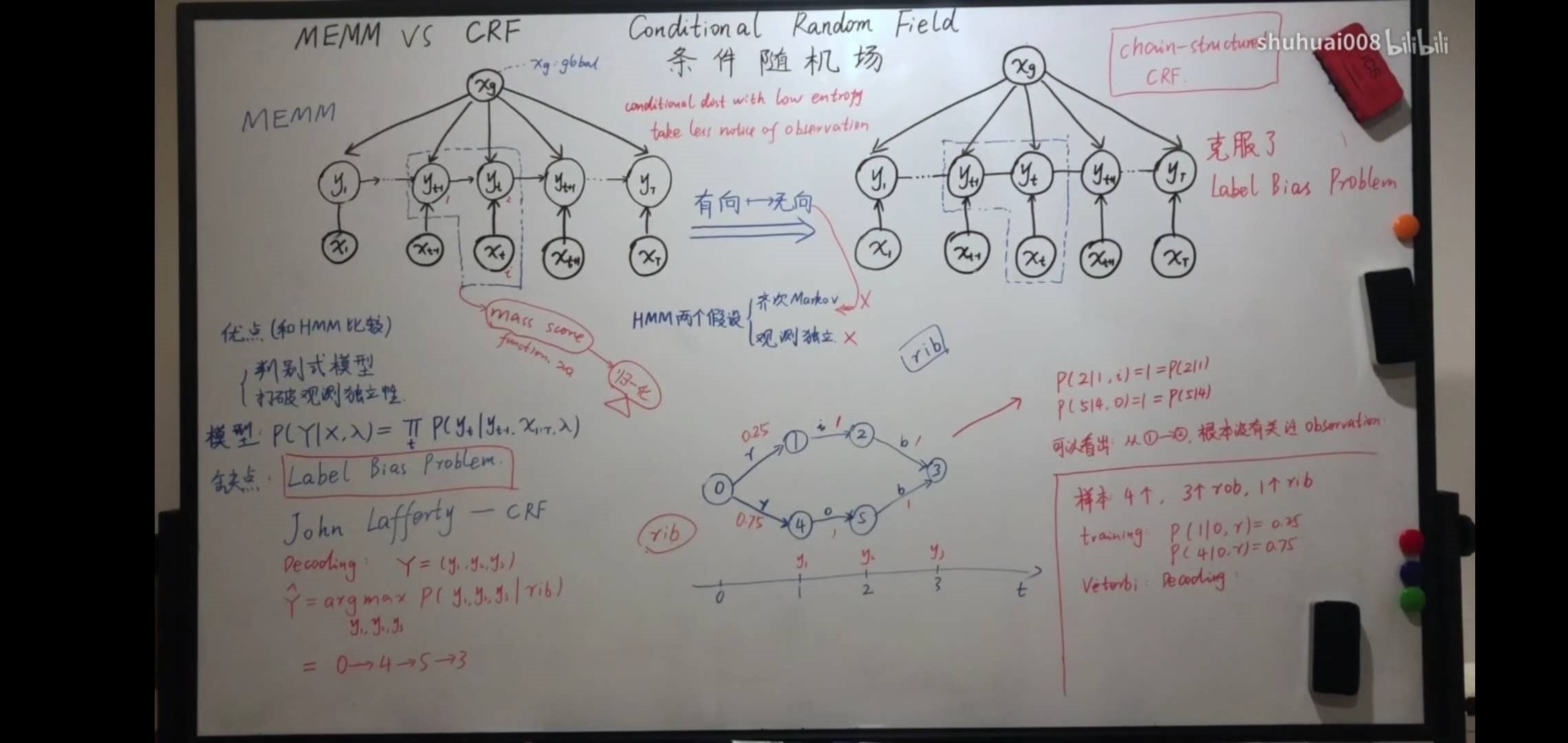

具体来说,他是怎么解决标注偏执的呢?
通过将有向图转为无向图,通过特征函数表示无向图。在完成全局的归一化。
无向图的特征表示,可以通过图下公式:
其中,蓝笔代表对于一个无向图的表达,首先通过最大团,表示出无向图,然后对团进行一个势函数的描述完成当前团的能量表示。


参考:https://www.cnblogs.com/wuxiangli/p/7196984.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号