
主题建模(理论理解)
在优秀的词嵌入方法出现之前,潜在语义分析模型(LSA)和文档主题生成模型(LDA)都是解决自然语言问题的好方法。LSA模型和LDA模型有相同矩阵形式的词袋表示输入。不过,LSA模型专注于降维,而LDA模型专注于解决主题建模问题。
在自然语言理解任务中,我们可以通过一系列的层次来提取含义——从单词、句子、段落,再到文档。在文档层面,理解文本最有效的方式之一就是分析其主题。在文档集合中学习、识别和提取这些主题的过程被称为主题建模。
概述
所有主题模型都基于相同的基本假设:
- 每个文档包含多个主题;
- 每个主题包含多个单词。
换句话说,主题模型围绕着以下观点构建:实际上,文档的语义由一些我们所忽视的隐变量或「潜」变量管理。因此,主题建模的目标就是揭示这些潜在变量——也就是主题,正是它们塑造了我们文档和语料库的含义。这篇博文将继续深入不同种类的主题模型,试图建立起读者对不同主题模型如何揭示这些潜在主题的认知。
LSA:
首先,我们用m个文档和n个词作为模型的输入。这样我们就能构建一个以文档为行、以词为列的m*n矩阵。我们可以使用计数或TF-IDF得分。然而,用TF-IDF得分比计数更好,因为大部分情况下高频并不意味着更好的分类.
该模型的挑战是矩阵很稀疏(或维数很高),同时有噪声(包括许多高频词)。因此,使用分解 SVD 来降维。
SVD,即奇异值分解,是线性代数中的一种技术。该技术将任意矩阵 M 分解为三个独立矩阵的乘积:A=U*S*V,其中 S 是矩阵 M 奇异值的对角矩阵。很大程度上,截断 SVD 的降维方式是:选择奇异值中最大的 t 个数,且只保留矩阵 U 和 V 的前 t 列。在这种情况下,t 是一个超参数,我们可以根据想要查找的主题数量进行选择和调整。
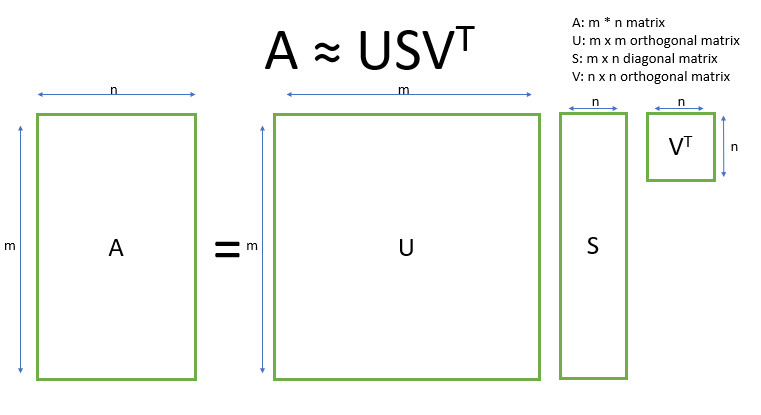
SVD 的思想在于找到最有价值的信息并使用低维的t来表达这一信息。
LDA:
LDA模型,属于无监督学习,而主题模型是其个中典型。它建立的假设在于每份文档都使用多个主题混合生成,同样每个主题也是由多个单词混合生成。
我不打算深入讲解狄利克雷分布,不过,我们可以对其做一个简短的概述:即,将狄利克雷视为「分布的分布」。本质上,它回答了这样一个问题:「给定某种分布,我看到的实际概率分布可能是什么样子?」
考虑比较主题混合概率分布的相关例子。假设我们正在查看的语料库有着来自 3 个完全不同主题领域的文档。如果我们想对其进行建模,我们想要的分布类型将有着这样的特征:它在其中一个主题上有着极高的权重,而在其他的主题上权重不大。如果我们有 3 个主题,那么我们看到的一些具体概率分布可能会是:
- 混合 X:90% 主题 A,5% 主题 B,5% 主题 C
- 混合 Y:5% 主题 A,90% 主题 B,5% 主题 C
- 混合 Z:5% 主题 A,5% 主题 B,90% 主题 C
如果从这个狄利克雷分布中绘制一个随机概率分布,并对单个主题上的较大权重进行参数化,我们可能会得到一个与混合 X、Y 或 Z 非常相似的分布。我们不太可能会抽样得到这样一个分布:33%的主题 A,33%的主题 B 和 33%的主题 C。
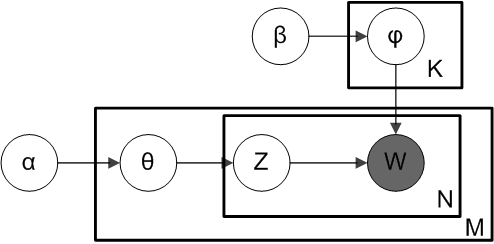
根据狄利克雷分布 Dir(α),我们绘制一个随机样本来表示特定文档的主题分布或主题混合。这个主题分布记为θ。我们可以基于分布从θ选择一个特定的主题 Z。
接下来,从另一个狄利克雷分布 Dir(𝛽),我们选择一个随机样本来表示主题 Z 的单词分布。这个单词分布记为φ。从φ中,我们选择单词 w。
然而,"a","with","can"这样的单词对主题建模问题没有帮助。这样的单词存在于各个文档,并且在类别之间概率大致相同。因此,想要得到更好的效果,消除停用词是关键一步。
参考:https://www.sohu.com/a/234584362_129720

 浙公网安备 33010602011771号
浙公网安备 33010602011771号