

tensorflow环境下实现bert_base量化,完成bert轻量级
环境:
windows 10
python 3.5
GTX 1660Ti
tensorflow-gpu 1.13.1
numpy 1.18.1
1. 首先下载google开源的预训练好的model。我本次用的是 BERT-Base, Uncased(第一个)
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
2. 参考https://www.zybuluo.com/Team/note/1632532 ( https://zhuanlan.zhihu.com/p/91024786?utm_source=wechat_session&utm_medium=social&utm_oi=1035849572991401984)第四部分。也就是下图:

3. 打开nvidia的github官方,对其中的convert部分进行参数修改。
其中代码详情如下:(实现的功能就是将 FP32 convert to FP16)
1 import tensorflow as tf 2 import numpy as np 3 from tensorflow.contrib.framework.python.framework import checkpoint_utils 4 from tensorflow.python.ops import io_ops 5 from tensorflow.python.training.saver import BaseSaverBuilder 6 7 8 def checkpoint_dtype_cast(in_checkpoint_file, out_checkpoint_file): 9 var_list = checkpoint_utils.list_variables(tf.flags.FLAGS.init_checkpoint) 10 11 def init_graph(): 12 for name, shape in var_list: 13 var = checkpoint_utils.load_variable(tf.flags.FLAGS.init_checkpoint, name) 14 recon_dtype = tf.float16 if var.dtype == np.float32 else var.dtype 15 tf.get_variable(name, shape=shape, dtype=recon_dtype) 16 17 init_graph() 18 saver = tf.train.Saver(builder=CastFromFloat32SaverBuilder()) 19 with tf.Session() as sess: 20 saver.restore(sess, in_checkpoint_file) 21 saver.save(sess, 'tmp.ckpt') 22 23 tf.reset_default_graph() 24 25 init_graph() 26 saver = tf.train.Saver() 27 with tf.Session() as sess: 28 saver.restore(sess, 'tmp.ckpt') 29 saver.save(sess, out_checkpoint_file) 30 31 32 class CastFromFloat32SaverBuilder(BaseSaverBuilder): 33 # Based on tensorflow.python.training.saver.BulkSaverBuilder.bulk_restore 34 def bulk_restore(self, filename_tensor, saveables, preferred_shard, 35 restore_sequentially): 36 restore_specs = [] 37 for saveable in saveables: 38 for spec in saveable.specs: 39 restore_specs.append((spec.name, spec.slice_spec, spec.dtype)) 40 names, slices, dtypes = zip(*restore_specs) 41 restore_dtypes = [tf.float32 if dtype.base_dtype==tf.float16 else dtype for dtype in dtypes] 42 # print info 43 for i in range(len(restore_specs)): 44 print(names[i], 'from', restore_dtypes[i], 'to', dtypes[i].base_dtype) 45 with tf.device("cpu:0"): 46 restored = io_ops.restore_v2( 47 filename_tensor, names, slices, restore_dtypes) 48 return [tf.cast(r, dt.base_dtype) for r, dt in zip(restored, dtypes)] 49 50 51 if __name__ == '__main__': 52 tf.flags.DEFINE_string("fp16_checkpoint", "mrpc_output/fp16_model.ckpt", "fp16 checkpoint file") 53 tf.flags.DEFINE_string("init_checkpoint", "bert_base/bert_model.ckpt", "initial checkpoint file") 54 checkpoint_dtype_cast(tf.flags.FLAGS.init_checkpoint, tf.flags.FLAGS.fp16_checkpoint)
其中,main函数的两个参数可以修改。第一个是你convert后的模型最终要输出的地方,第二个是你下载的google的模型的地址.
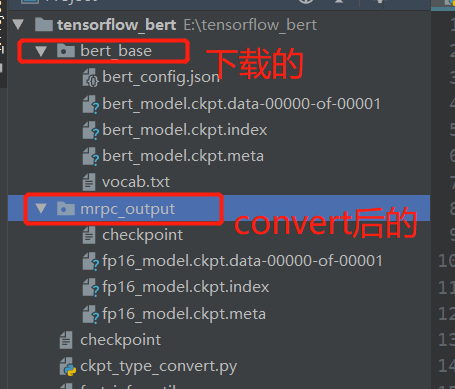
很多读者看到这里就觉得多此一举,为什么不知将通过tensorflow的官方工具,只需要几行代码就可以实现float32->float16(不知道的小伙伴可以看这里),但是需要注意的是,使用TFLite转换得到的量化模型是tflite结构,意味着只能在tflite中运行(大部分场景为移动端)具体可以参考这里。
4.
通过量化后的bert模型,我们就可以进行测试性能了。身边正好有一个错别字中ppl的计算model,所以把bert量化后,直接可以进行性能测试。
(注:由于restore模型时,是通过先加载运算图,再加载图中的变量参数等信息,有很多错误。因此我们需要缕一遍代码,将其中的variable的dtype修改为float16,否则出现类型不一致等错误。)
之后通过bert作为语言模型计算每个句子的ppl的性能和时间作为评测标准,进行了模型轻量级前后的比较:
转换前float32计算一个句子的ppl和时间和显存占用:

转化后float16:

5.
最后我们得出结论:量化后的模型相对于原模型精度会有些许损失,但是显存占用减少了很多。
参考; https://zhuanlan.zhihu.com/p/113734249

 浙公网安备 33010602011771号
浙公网安备 33010602011771号