
关系抽取 ---远程监督 (一种基于word-level的sentence内部去噪)---《Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning》
- 目标(创新点):
因为远程监督而引入的很多质量很低的句子,这些句子包含了一些嘈杂的单词,而这些单词被当前的远程监督方法忽略了,导致了不可接受的精确度。文本提出的目标是为了解决句子内部的噪音单词。
- 主要工作:
1. 提出了消除句子中噪声词的STP(Sub-Tree Parse)和增强关系词语义特征的实体注意机制
2. 提出利用实体类型分类的先验知识初始化关系提取器,增强了关系提取器对低质量语料库的鲁棒性。(也是一种迁移学习的成功实践!)
- 先举例说明文本的必要性:
1.noisy:
It is no accident that the main event will feature the junior welterweight champion miguel cotto, a puerto rican, against Paul Malignaggi, an Italian American from Brooklyn
可以看到,上句话只有 加粗 部分体现出relation--place of birth,,其余部分都是noisy.
2. 先验知识:
Alfead Kahn, the Cornell-University economist who led the fight to deregulate airplanes.
可以看到,上句话是一个 relation -company的体现,如果没有先验知识 (Alfead Kahn is a person and Cornell-University is a company) 很难去get这个relation
- 模型介绍:
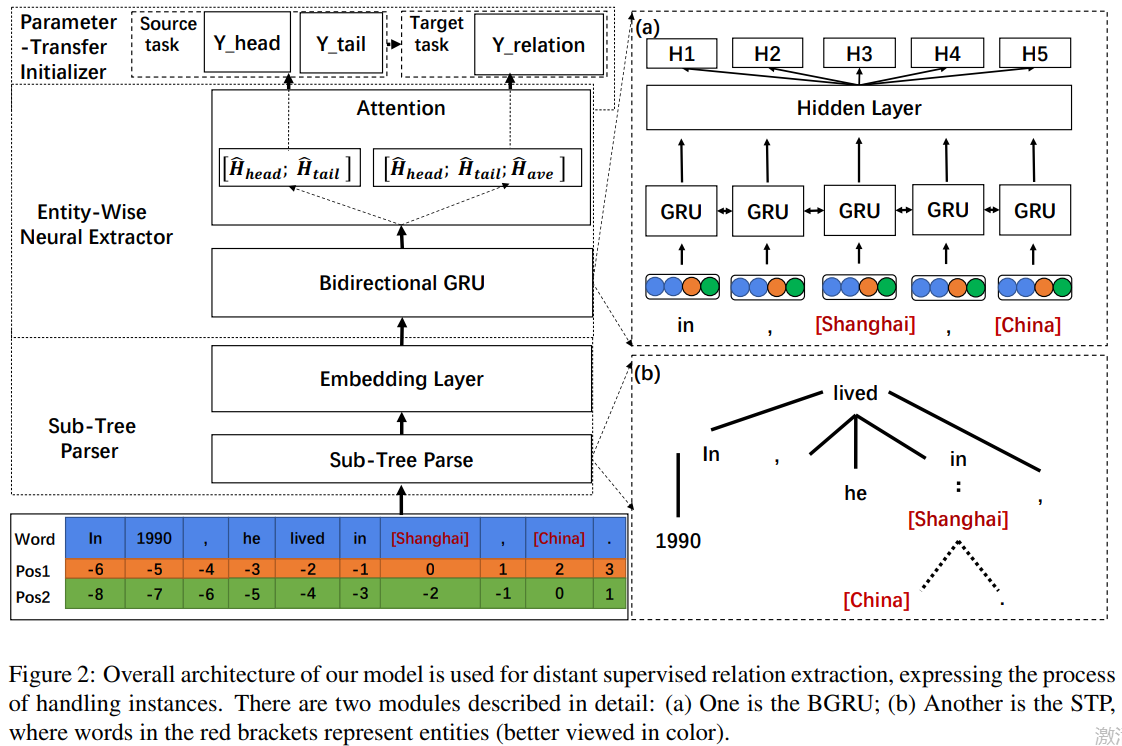
概述:
先将句子用 STP处理以后,将其转化为词向量后,输入到双向GRU内转化为hidden state,然后利用entity-wise attention+Hierarchical-level Attention(Word-level Attention和Sentence-level Attention的综合)后将包含一个实体对的所有句子转化为一个向量,然后将这个向量经过全连接和softmax来进行entity type分类的pre-train和关系分类。
分3个部分进行介绍:
一.Sub-Tree Parser
1.Sub-Tree Parse
通过Stanford parser得到句子的依存句法关系树,找到两个实体最近的共同祖先(非自身),以该祖先为根将子句法树提取出来即可,则该子树的单词和单词位置作为输入
举个例子,看上图,有个句子:
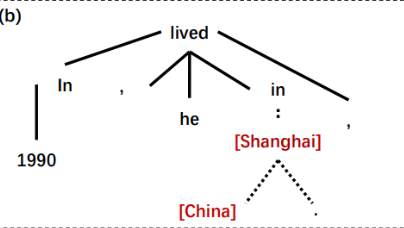
[In 1990, he lives in Shanghai, China.]
实体为Shanghai和China,看图中他们的共同祖先为in,则橘色部分in Shanghai, China就被提取出来,这三个单词的word和position就要被换成词向量输入到双向GRU中了。
这个方法比Shortest Dependency Path (SDP)好,在SDP中,上述句子因为Shanghai和China在句法树中直接相连,则最短嘛,就是提取出Shanghai, China。没有“in”了,但in这个单词才是预测这
个关系最重要的单词。
2.Word and Position Embeddings
包含一个实体对的所有句子叫包,一个包内的第条句子的第
个单词的词向量为
维,记为
,分别和两个实体的距离对应的向量为
维,记为
和
,将三者连起来就是该
单词对应的下一步的输入
二.Entity-Wise Neural Extractor
1.BGRU over STP
GRU unit 可以简单堪称这样的建模:
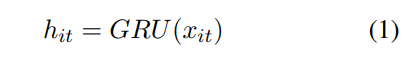
其中,![]() 是第i个句子的t个单词,
是第i个句子的t个单词,![]() 是gru unit的对应位置输出,m是hidden state size
是gru unit的对应位置输出,m是hidden state size
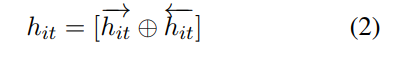
然后将Bi方向的进行拼接。
2.Entity-wise Attention
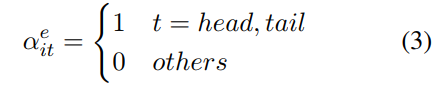
经GRU处理过的第i条句子的第t个单词对应位置的hidden state为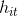 。entity-wise attention给每个单词赋予一个权重,如果该单词是两个实体之一,则该权重为1,否则为0.
。entity-wise attention给每个单词赋予一个权重,如果该单词是两个实体之一,则该权重为1,否则为0.
3. Hierarchical-level Attention
Word-level Attention
Word-level Attention也是给每个单词赋予一个权重。
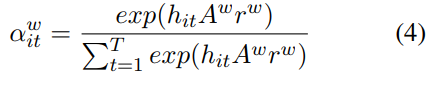
其中 是要学习的参数,
是要学习的参数,
将每个单词的entity-wise attention权重和Word-level Attention权重相加,就是这个单词的权重。将各个单词对应的hidden state按权重相加就是第i条句子的context。如果只用Word-level
Attention则把实体的重要性削弱了,其实entity-wise attention就是把实体的权重增加了1而已,如果只用entity-wise attention也不好,因为其他单词也包含了信息。
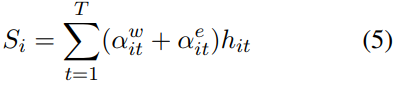
Sentence-level Attention
Sentence-level Attention是给每个句子赋予一个权重。 (这个和刘知远教授的2016的论文机制相同)
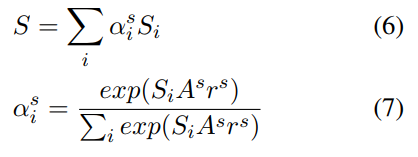
将各个句子对应的context按权重相加就是这个包的context。
三.Parameter-Transfer Initializer
1.Pre-learn the Entity Type
对entity-head和entity-tail进行entity-type的pre-train的先验知识的训练
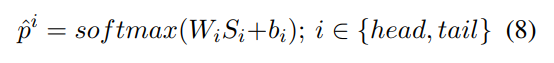

![]() 是每个task的权重,
是每个task的权重,![]() 是共享权重,
是共享权重,![]() 是各自自己的参数,
是各自自己的参数,![]() 是ont-hot的entity-types的向量,贝塔是L2惩罚的权重。
是ont-hot的entity-types的向量,贝塔是L2惩罚的权重。
2.Train the Relation Extractor
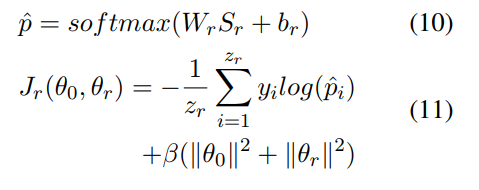
![]() 与enitty-tyoe的参数大致相同
与enitty-tyoe的参数大致相同
3.Optimize the Objective Function
所以,模型最终的优化目标如下:其中![]() ,当
,当![]() ==1时,优化entity-type,反之则是关系抽取
==1时,优化entity-type,反之则是关系抽取
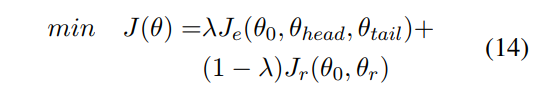
- 实验
因为freebase的实体对会提供实体type(种类),所以我们光用NYT数据集就能完成迁移学习
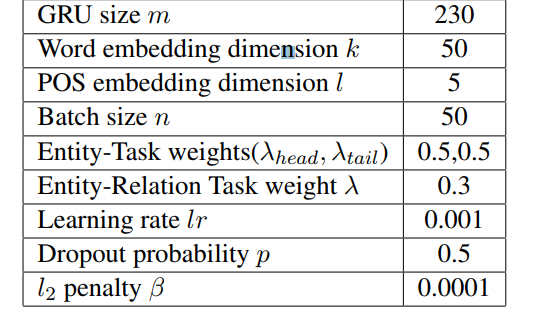
参数列表:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号