
关系抽取 ---远程监督 ---《Ranking-Based Automatic Seed Selection and Noise Reduction for Weakly Supervised Relation Extraction》
- 先说看完本文的一个收获吧:
文章创造性地将关系提取中的自动选种和数据降噪这两个重要任务转换为排序问题。然后,借鉴 HITS、K-means、LSA 和 NMF 等传统算法策略,按照对实例-模式三元组排序的思路,构建出了兼具自动选种和数据降噪功能的算法。实验结果显示,文章提出的算法能够有效完成自动选种和数据降噪任务,并且其性能同基线算法相比也有较大提升。
这篇文章的启发作用在于:对于关系提取中的不同子任务通过问题转换归结为本质相同的同一问题,而后借鉴已有的成熟算法设计出可以通用的解决策略。这种思路上的开拓创新能否应用于其他 NLP 任务,是一个值得思考和探索的方向。
- 文章的贡献主要有以下几点:
1. 创造性的将关系提取中的自动选种和数据降噪任务转换成排序问题;
2. 提出多种既可用于 Bootstrapping 关系提取自动选种,又能用于远程监督关系提取降噪的策略;
- 这篇文章主要对弱监督关系提取中两个相关的任务展开研究:
Bootstrapping 关系提取(Bootstrapping RE)的自动选种任务;
远程监督关系提取(Distantly Supervise RE)的降噪任务。
文章受到 Web 结构挖掘中最具有权威性、使用最广泛的 Hypertext-induced topic search(HITS)算法,以及 K-means、潜在语义分析(LSA)、非负矩阵分解(NMF)等聚类中心选择算法的启发,提出一种能够从现有资源中选择初始化种子、并降低远程标注数据噪声的算法。
问题引入
Bootstrapping RE 算法是机器学习中一种比较常用的弱监督学习方法。首先,利用一个称作“seeds”的小实例集合进行初始化,用以表示特定的语义关系;然后,通过在大规模语料库上迭代获取实例和模式,以发现与初始化种子相似的实例。该算法性能的主要制约因素在于语义漂移问题,而解决语义漂移问题的一种有效手段就是选择出高质量的“seeds”。


Distantly Supervise 技术是一种用于构建大规模关系提取语料库的有效方法。然而,由于错误标注问题的存在,远程监督获取的语料常常包含噪声数据,这些噪声会对监督学习算法性能造成不良影响。因此,如何降低错误标注带来的数据噪声,就成为了远程监督技术的一个研究热点。
问题转化
用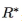 表示目标关系的集合,每一种目标关系
表示目标关系的集合,每一种目标关系 由一个三元组集合 Dr= {(e1, p, e2)} 来表示。其中,e1 和 e2 表示实体,实体对 (e1,e2) 被称为实例,p 表示连接两个实体的pattern。例如,三元组 (Barack Obama, was born in, Honolulu),(BarackObama, Honolulu) 表示一个实例,“was born in”表示pattern。
由一个三元组集合 Dr= {(e1, p, e2)} 来表示。其中,e1 和 e2 表示实体,实体对 (e1,e2) 被称为实例,p 表示连接两个实体的pattern。例如,三元组 (Barack Obama, was born in, Honolulu),(BarackObama, Honolulu) 表示一个实例,“was born in”表示pattern。
结合上述概念,文章将所研究的两个关系提取任务分别定义如下:
Bootstrapping RE 的自动选种任务:以目标关系集合为输入,针对每一个,从由数据集中提取出的三元组集合 Dr 的实例中,选出能使 Bootstrapping RE 算法高效工作的种子。
Distantly Supervised RE 的降噪任务:从由 DS 自动为每个关系生成的三元组集合 Dr 中,过滤出所包含的噪声三元组(错误标注三元组)。
由以上两个任务的描述可以发现,无论是选种还是降噪都是从给定的集合中选出三元组。从排序的角度来看,这两个任务实质上拥有相似的目标。
因此,文章将这两个任务分别转换为:在给定三元组集合 Dr(可能包含噪声)的情况下,实例 (e1,e2 )的排序任务(选种)和三元组 (e1, p, e2 ) 的排序任务(降噪)。
在选种任务中,使用排名最高的 k 个实例作为 bootstrapping RE 的种子。同理,在降噪任务中,对于 DS 生成的三元组,使用其中排名最高的 k 个三元组来训练分类器(降噪任务中的 k 值可能远远小于选种任务中的 k 值)。
自动选种和降噪算法
文章提出的算法受到了 Hypertext-induced topic search(HITS)算法,以及 K-means、潜在语义分析(LSA)、非负矩阵分解(NMF)等聚类中心选择算法的启发。
该算法根据具体的任务来决定是选择实例还是选择三元组:实例用于自动选种任务,三元组用于降噪任务。由于实例即为实体对,而实体对又包含在三元组中,因而可以通过实例和三元组之间的转换,灵活的将提出的方法分别应用到两个任务中。
- 基于K-means的算法
文章提出的基于 K-means 的算法具体描述如下:
1. 确定需要选择的实例/三元组的数目 k;
2. 运行 K-means 聚类算法将输入的三元组中的所有实例划分为 k 个簇,每个数据点通过其对应实体间的嵌入向量差来表示。例如,实例 I=(Barack Obama,Honolulu) 对应于 vec(I)=vec("Barack Obama")-vec("Honolulu");
3. 从每个簇中选出最接近质心的实例。
- 基于HITS的算法 (HITS总结比较好的博客)
Hypertext-induced topic search(HITS)算法又称为 hubs-and-authorities 算法,它是一种广泛用于对 web 页面排序的链接分析方法。
该算法的基本思想是:利用 Hub 页面(包含了很多指向 Authority 页面的链接的网页)和 Authority 页面(指与某个主题相关的高质量网页)构成的二部图,计算每个节点的枢纽度(hubness)得分,然后据此对网页内容的质量和网页链接的质量做出评价。
对于第 2 节描述的两个任务,可通过实例 (e1,e2) 和模式 p 的共生矩阵 A 生成两者的二部图,进而即可利用 HITS 算法的思想计算两者的 hubness 得分。
文章提出的基于 HITS 思想的选种策略描述如下:
1. 确定要选择的三元组的数目 k;
2. 基于实例-模式的共现矩阵 A 构建实例和模式的二部图。下图所示为构建二部图的三种可能思路。思路一:将每一个实例/模式均作为图中的一个节点。思路二:将实例和模式分别作为边和节点。思路三:将实例和模式分别作为节点和边;

3. 对于思路一和思路三,仅保留 hubness 得分最高的 top k 个实例作为输出。对于思路二,选择与得分最高的模式相关联的 k 个实例作为输出。
- 基于HITS和K-means的方法
该方法将 HITS 算法和 K-means 算法组合使用。首先,基于实例和模式的二部图对这两者进行排序;然后,在标注数据集上运行 K-means 算法对实例进行聚类。之后,与常规思路不同,这里不选择距离质心最近的实例,而是选择每个簇中 HITS 算法 hubness 得分最高的实例。
- 基于LSA的算法 (SVD方法总结的比较好的博客)
潜在语义分析(LSA)是一种被广泛应用的多维数据自动聚类方法,该方法利用奇异值分解(Singular value decomposition,SVD)算法构建实例-模式共现矩阵 A 的等价低秩矩阵。
所谓 SVD,是将矩阵![]() 分解为三个矩阵的乘积:SVD 实例矩阵
分解为三个矩阵的乘积:SVD 实例矩阵![]() ,奇异值对角矩阵
,奇异值对角矩阵![]() ,SVD模式矩阵
,SVD模式矩阵![]() :
:

本文提出的基于 LSA 的选种策略具体描述如下:
1. 指定需要的三元组数目 k;
2. 利用 LSA 算法将实例-模式的共生矩阵 A 分解为矩阵 I、S、P。 将 LSA 的维度设置为 K=k;
3. 将 LSA 看作软聚类的一种形式,其中 SVD 实例矩阵 I 的每一列对应一个簇。之后,从矩阵 I 的每一列选出绝对值最高的 k 个实例。
- 基于NMF的方法
非负矩阵分解(Non-negative matrix factorization,NMK)是另外一种用于近似非负矩阵分解的方法。非负矩阵![]() 可以近似表示为
可以近似表示为![]() 和
和![]() 这两个因子的乘积:
这两个因子的乘积:
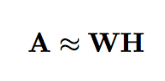
非负约束(non-negativity constraint)是 NMF 与 LSA 之间的主要区别。与基于 LSA 的方法类似,NMF 算法先将期望选择的实例数目设置为 K=k。之后,从矩阵 W 的每一列中选出值最大的 k 个实例。
实验
数据集与设置
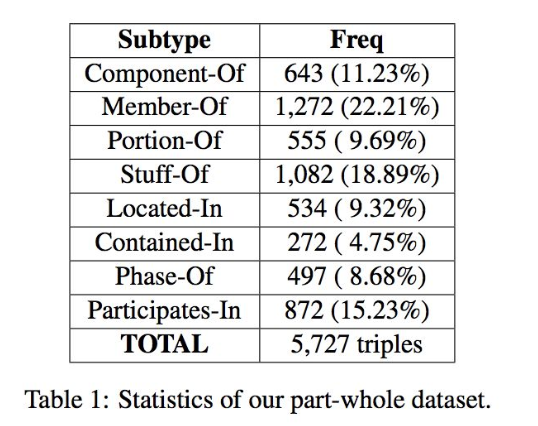
文章使用了一个局整关系的标注数据集做为种子选择的来源。该数据集提取自 Wikipedia 和 ClueWeb。这里,所谓的局整关系并不是指某一种具体的关系,而是指一种类型的关系集合,如下表所示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号