
关系抽取---远程监督 ---《DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction》
在本文理解之前,这个图必须理解,因为这个是本文数据的划分范围。

x为远程监督的负样本,也就是通过远程监督排除的数据。其余的为远程监督产生的样本,即远程正例样本。但是这里还分真的能表达这个关系的true positive data(○),和噪音数据false positive data(△).
- 创新点:
1. 第一次将对抗生成网络应用在关系抽取领域。
2. 模型是的句子层面,与之前的bag-level不同。并且generator是可插拔式,可以安插在任何网络之前,进行对数据的清洗。
文本有强假设(ture postive的data还是在bag中占多大数的)(这个假设有些过于强势,因为relation bag 有几率全是噪音数据)
- 本文思想:
给定一组远程监督产生的句子,generator试图从中生成true positive data; 但是,这些生成的样本被视为nagative data来训练discriminator。因此,当完成一次扫描DS positive data时,generator产生的true positive data越多,discrimnator的性能下降越快。经过对抗性训练,我们希望得到一个鲁棒的genarator,使鉴别器在最大程度上丧失其分类能力。
(可能有点绕口,这么解释吧:
本文的目标就是获得一个generator,可以最大限度的过滤掉噪音数据。那么留下来的正好是true positive data,这些留下的数据用于训练discriminator。按照正常的思维,这些优质数据被discriminator训练的时候,应该最大化true positive data对应relation的概率。但是恰恰相反,本文要让这批数据被discriminator看成是负例数据。所以这样就可以最大限度的降低discrimination的分类能力。)

- pre-trainning strategy:
1. discriminator 用 DS positive dataset P (label 1) and DS negative set N D (label 0) 预训练。(见上图),预训练的目标:accuracy到达90%以上。
2. generator用 DS positive dataset P (label 1) and DS negative set N D (label 0) 预训练.(但是这个negative set 和discriminator不相同,目的就是为了实验的鲁棒性),同时让generator过拟合训练数据。
(过拟合是为了让generator可以最大限度的在对抗学习中逐渐降低 false positive samples)
- Generative Adversarial Training for Distant Supervision Relation Extraction
generator和discriminator都是CNN model. 都是句子输入(word embedding ,position embedding)+entity pair 输入
注:将sentences 分成bags,并不是entityt pair对应的那个bag.
generator:

T是generator认为true positive的数据。(置信度高)

generator的目标就是最大化这个函数。Pd是discriminator对T中的每个句子表达relation的概率
(LG涉及一个离散的采样步骤,因此不能通过基于梯度的算法进行直接优化。我们采用了一种常用的方法:基于策略梯度的强化学习,下一章节说明)
discriminator:
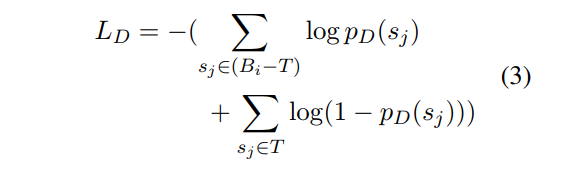
discriminator的目标就是最小化这个函数。(解释:也就是最大化false positive data的概率(大括号上面的部分)和 最小化true positive data的概率 )
算法概述:

注:在每一轮epoch中,discriminator加载相同的初始函数。(原因:我们需要的是genarator而不是discriminator;generator的作用是从数据中筛选出true positive data,而不是取从头到尾生成)
(因此,我们当discriminator的性能在一个epoch内下降最大时,就产生了最鲁棒的genarator。。为了创建相等的条件,每个epoch的包集B是相同的.)
Optimizing Generator:
reward由两部分组成:
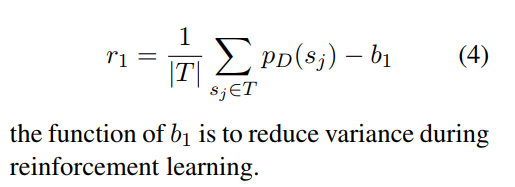

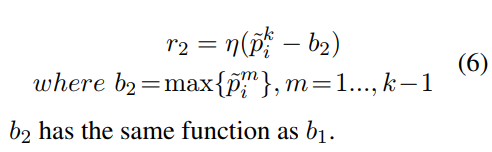
因此,Lg的梯度:
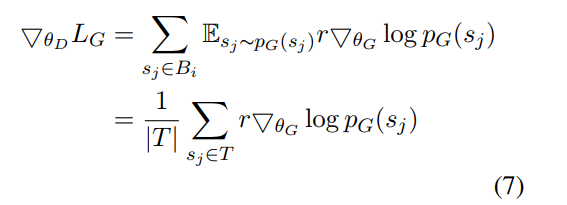
流程概述:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号