
数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九。基于内容的电影推荐
在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理。
本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐。
1.找出各个电影的评分人总数
2.对于每个电影对A和B,找出所有同时对A和B评分的人。
3.找出每两个相关电影之间的关联。在这个阶段,我使用3个不同的关联度算法(pearson,cosine,jaccard)一般要根据具体的数据需求来选择关联度算法。
数据的输入格式:

第一阶段转化完之后:

经过MR阶段2的map阶段后:

经过排序和洗牌之后的输出:
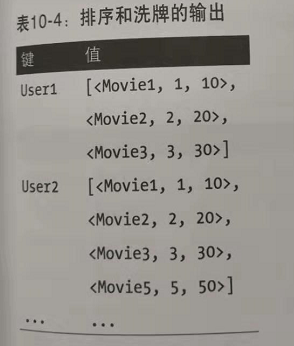
在经过MR阶段2的reduce()后:
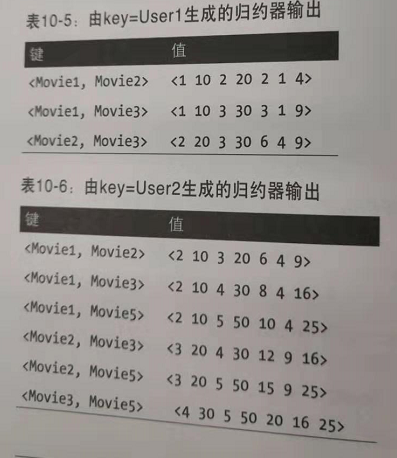
第三阶段MR的map阶段的输出:
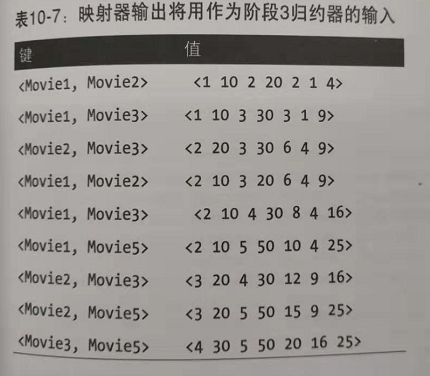
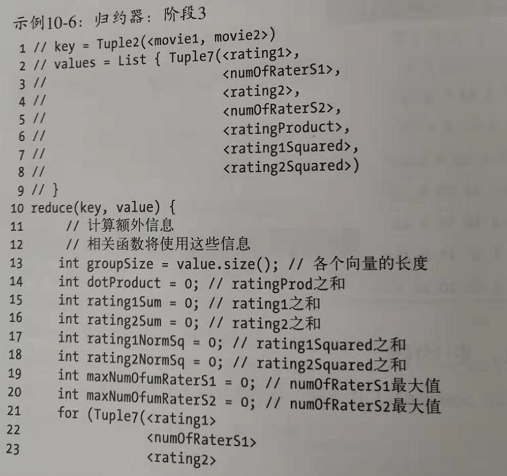
第三阶段MR的reduce的输入:
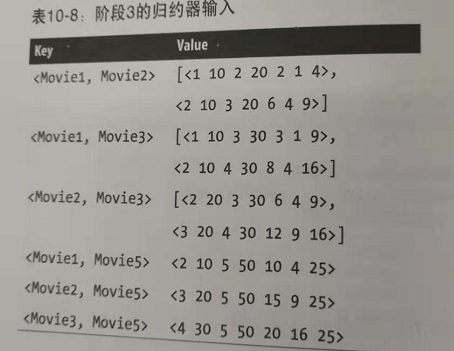
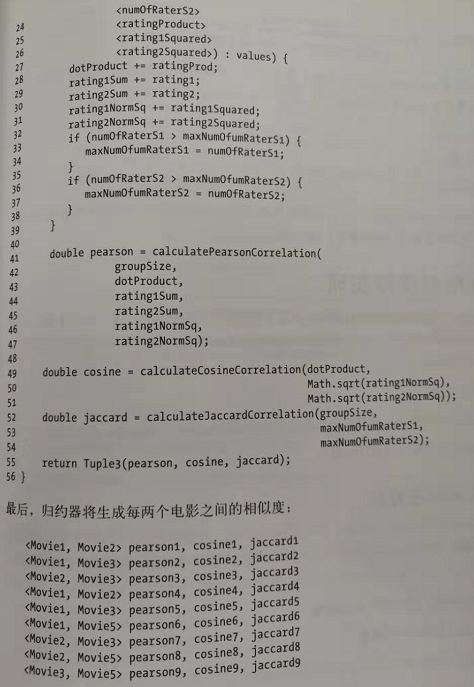
reduce代码:
spark的基本步骤:
1.导入所需要的类和接口;
2.处理输入参数;
3.创建一个spark上下文对象;
4.读取hdfs文件并创建第一个RDD;
5.找出谁曾对这个电影评分;
6.按movie对moviesRDD分组;
7.找出每个电影的评分人数,然后创建(K,V)为usersRDD = <K=user,V=<movie,rating,numberofRaters>>
8.将usersRDD与自身连接,找出所有(movie1,movie2)对 joinedRDD = userRDD.join(userRDD) joinedRDD= (user,T2((m1,r1,n1),(m2,r2,n2)))
9.删除重复的(movie1,movie2)对;
10生成所有的(movie1,movie2)组合。
11.按键(movie1,movie2)对moviePairs分组
12计算每个(movie1,movie2)对的关联度
十。使用马尔科夫模型的智能营销
先说说马尔科夫:


使用马尔科夫的智能营销的大致流程:
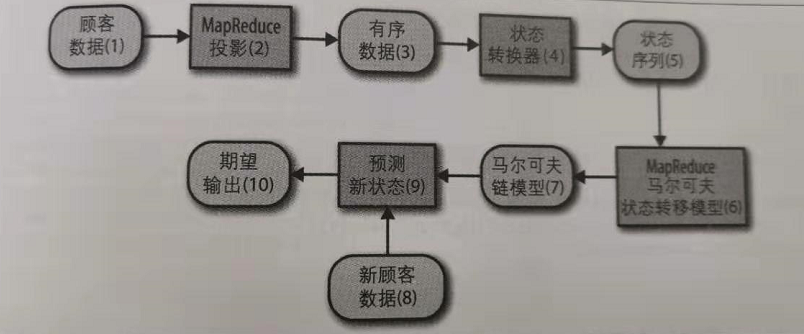
其中使用MR生成有序数据:可以采用之前说的二次排序的方式。
状态序列的生成:


采用的策略:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号