

数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友。
在所有用户对中找出“共同好友”。
eg:
a b,c,d,g
b a,c,d,e
map()-》 <a,b>,<b,c,d,g> ;<a,c>,<b,c,d,g>;.....
<a,b>,<a,c,d,e>
reduce()-> <a,b>,<c,d> 也就是a,b的共同好友是c,d。
上述就是思想。
八,使用MR实现推荐引擎
1.购买过该商品的顾客还购买了哪些商品。
这里,利用MR的两次迭代实现CWBTIAB功能。
阶段1:生成同一个用户购买的所有商品列表。分组由HAdoop框架处理,其中映射器和规约器都会完成一个恒等函数。
阶段2:解决列表商品的共现问题。使用Stripes(条纹)设计模式,只发出5个最常见的商品。


2.经常一起购买的商品(FBT)

3.推荐连接
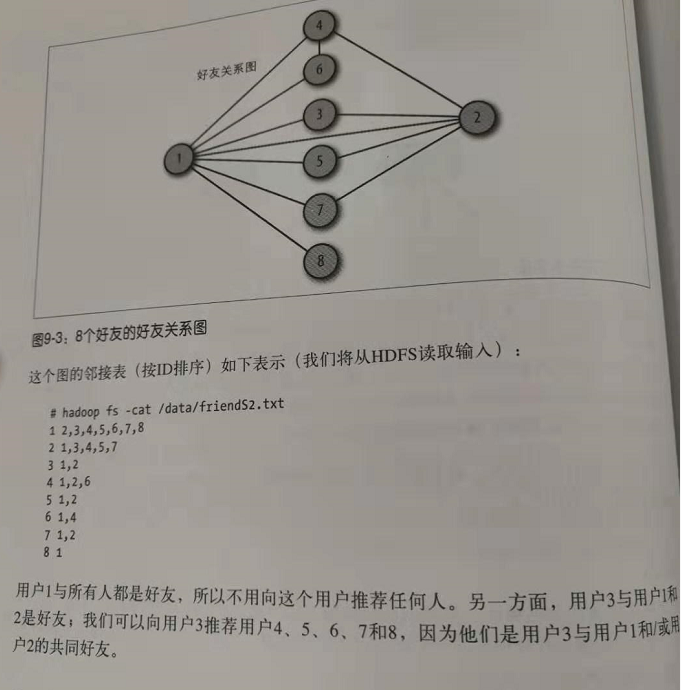
解决方案(实现思路):



 浙公网安备 33010602011771号
浙公网安备 33010602011771号