

数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五。移动平均
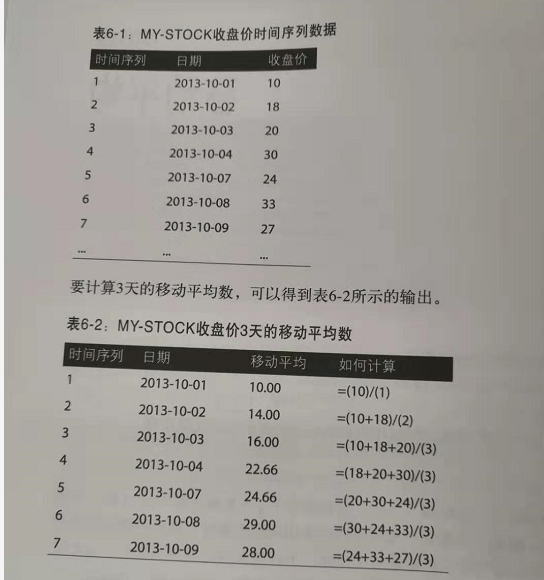
多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均。之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删除最早的值同时增加最新的值,这个平均值会相应地“移动”。
例子:
java代码:


MR方案:
方案1:对于各个规约器键,在RAM种对时间序列数据排序,这个方法存在一个问题:如果没有足够的RAm来完成规约器的排序操作,这种方法就不可行。
方案2:让MRF完成时间序列数据的排序(MR框架的主要特性之一就是按键值排序和 分组,hadoop很擅长这个)。与方案1相比,这个方案可伸缩性要好得多,排序由MRF的sort和shuffle函数完成,如果采用这个方案,我们需要修改键值对,并编写一些定制插件类来完成二次排序。
方案1: map()函数将key进行拆分处理直接发送。 reduce()对key相同的数据进行排序,在进行window内的计算平均。
方案2:二次排序的必要设置: 分区器根据映射器输出键确定。哪个映射器输出发送到哪个规约器。一般的,不同的键会在不同的组中,不过有时我们希望不同的键在同一个组中,这种情况下要使用输出值分组比较器,用来对映射器输出分组。输出键比较器在排序阶段用来比较映射器输出键。

六。购物篮分析
MBA可以揭示不同商品或商品组之间的相似度。数据挖掘的一般目标是从庞大的数据集合中提取有趣的关联信息,例如数百万超市交易。MBA可以帮助我们找出很可能会在一起购买的商品,关联规则挖掘会发现一个交易集中商品之间的相关性。然后可以使用这些关联规则在商店货架上或在线将相关的商品摆放在相邻的位置。这属于计算密集型问题,很适合MRF。
1.对应N阶元祖的MR解决方案,这个放啊你可以查找频繁模式。
2.spark解决方案,不仅可以找出频繁模式,还会为他们生成关联规则。
在数据挖掘中,关联规则有两个度量标准。

1.MR解决方案。 生成频繁模式。
主要算法 :map -》 reduce

2.spark不仅生成频繁模式,同时生成规则。
流程:

流程中第一个MR: (也就是生成频繁模式) 第二个MR:


第二个MR不太好理解:
针对map的的输出(也就是生成所有频繁模式的子模式):
子模式的生成规则:


然后groupByKey():

然后再生成规则:

生成的规则代码为:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号