

数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三。 左外连接
考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易。假设我们有两类数据,用户和交易:
users(user_id,location_id)
transactions(transction_id,product_id,user_id,quantity,amout)
所谓左外连接:令T1(左表)和T2(右表)是以下两个关系(其中t1是T1的属性,t2是T2的属性):
T1=(K,t1)
T2=(K,t2)
关系T1,T2在连接键K上左外连接的结果将包含左表(T1)的所有记录,即使连接条件在右表(T2)中未找到任何匹配的记录。如果关于键K的ON子句匹配T2中的0条记录,这个连接仍会在结果中返回一行,不过T2的各个列为NULL。左外连接会返回内链接的所有值以及左表中未与右表匹配的所有值。
sql: select field1,field2 .. from T1 left outer join T2 on T1.K=T2.k



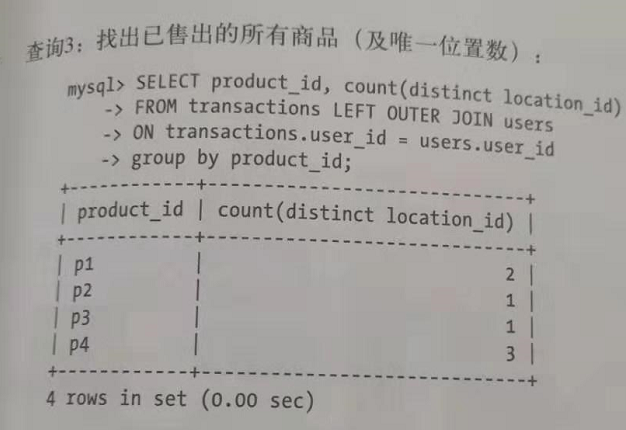
MR左外连接实现:
上图中sql查询3可以提供我们需要的输出,他会找出所有交易中各个售出商品对应的不同用户地址。我们将分两个阶段提供左外连接问题的解决方案。
MR阶段1:找出所有售出的的商品(以及关键的地址)。可以使用上一节中的sql查询1完成这个任务。
MR阶段2:找出所有售出的商品(以及关联的唯一地址数)。可以使用上一届中的sql查询3来实现。

spark左外连接实现:
方案1:通过将两个javaRDD(这里是user和交易RDD),通过javaRDD.union函数返回并集,合并来创建一个新的RDD.
主要方法:transantion.mapToPair.union(users.mapToPair()).goupByKey().flatMapToPair().goupByKey().mapValues().collect()
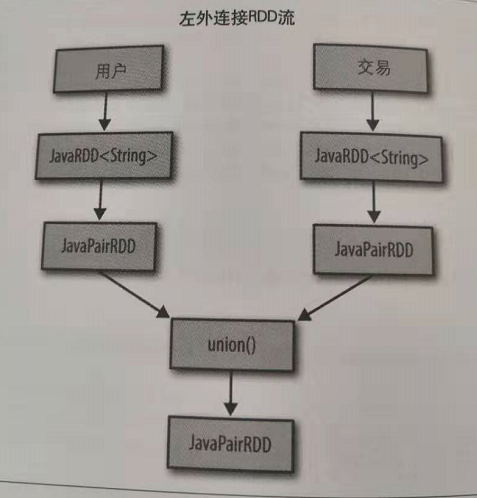
方案2:直接通过leftOuterJoin的方法来实现。
四。反转排序
反转排序(Order Inversion,OI)设计模式,这种设计模式可以用来控制MR框架中规约器值的顺序(这很有用,因为一些计算需要有序的数据。)通常会在数据分析阶段应用OI模式。在Hadoop和Spark中,值到达规约器的顺序是未定义的。(没有明确的顺序,除非我们利用MR的排序阶段将计算所需的数据推至规约器)。OI模式适用成对模式(使用更简单的数据结构,需要更少的规约器的内存),因为规约器阶段不需要额外的规约器值顺序。
为了帮助理解OI模式,下面首先来看一个简单的例子。考虑一个对应组合键(K1,K2)的规约器,假定K1是这个组合键的自然建部分,假设这个规约器接收到下面的值(这些值没有确定的顺序):
v1,v2,v3...
通过实现OI模式,可以对到达规约器(对应键(K1,K2))的值进行排序和分类。使用OI模式的唯一目的是适当的确定提供给规约器的数据的顺序。为了展示OI模式,下面假设K1是组合键的固定部分,在这里K2只是3个不同的值(K2a,K2b,K2c),这将生成下表所示的值。(需要说明,必须把键{K1,K2a}{K1,K2b}{K1,K2c}发送到相同的规约器)。

在这个表中:
m+p+q = n
排序顺序: K2a<K2b<K2c(升序) 或 K2a>K2b>K2c (降序)
利用适当的OI模式实现,可以对规约器值排序,如下所示:
A1,A2,A3,。。。Am ,B1,B2,....Bn,C1,C2,....Cn
由于规约器值是有序的,这就允许我们首先从Ai开始,再到Bi,最后到Ci完成一些计算。需要说明,这里不需要在内存中缓存值。关键问题是如何得到所需的行为。答案就是定义一个定制分区值,他只关注组合键(K1,K2)左边的部分(K1,即自然规约器键)。也就是说,定制分区器只根据左键(K1)的散列进行分区。
例子:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号