


百度百科采集策略(如何能尽可能采集全所有词条)
一.分析
若从分类开始:
1.百科库中显示的分类是不全的,只有一些开放分类。
2.一个分类的数量不固定,每一页最多显示30个。
比如url:

参数解析:
https://baike.baidu.com/fenlei/此处替换分类
Limit:30 每个页最多显示30条。
Index:第几页。
Offset:下标。 此url显示的就是这个分类下 30到30+offset之间的词条。
直接优化:
上述例子,直接改成:
http://baike.baidu.com/fenlei/文化遗产?limit=999999999
即可显示此分类下所有的目前开放的词条。无须遍历一直遍历“下一页”标签。
上述第1点:分类不全的问题。
上述第2点:某一个分类下 词条不全的问题。
若从词条进行拓扑,往外蔓延,不能保证所有词条之间都是相通的。
综上,我计划从分类和词条两个点同时出发,去统计所有的分类,再去统计所有的词条。
具体步骤如下:
二.步骤
1.分类出发
先定义所有的一级分类。

除了这些一级分类,还有两个需要额外单独考虑的:
https://baike.baidu.com/science
然后遍历这些一级分类,通过正则,提取所有a标签中的

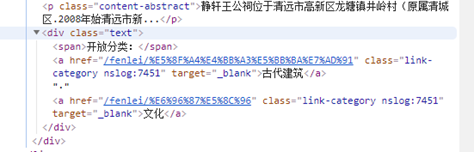
将这些可能的分类url全部规则化:
http://baike.baidu.com/fenlei/?
存到一个set集合中。
2.词条出发
1.在遍历每一个词条的同时,同时也需要一个词条的set集合,找到一个词条的url就往set中add。
具体情况:
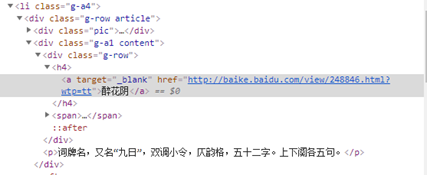
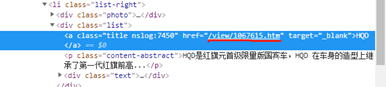
同样规则化:
https://baike.baidu.com/item/?
存到这个集合中,其中每个词条有一个需要筛选的内容:

这些词条标签也可能是分类,通过组装url:
https://baike.baidu.com/fenlei/政治人物.
去访问看返回状态进行判断是否需要add到词条的set中。
2.可以将https://baike.baidu.com/view/+数字,通过判断这个html是否返回正常进行上述操作。
三.汇总
将分类中出现的词条,分类汇总到词条的set,和分类的set.
将词条中出现的词条,分类汇总到词条的set,和分类的set.
最后遍历分类set找词条add到词条的set,最后形成一个从词条和分类出发的词条set。
最后再在每一个词条url中提取需要的内容。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)