

spark读取文件机制 源码剖析
Spark数据分区调研
Spark以textFile方式读取文件源码
textFile方法位于
spark-core_2.11/org.apache.spark.api.java/JavaSparkContent.scala

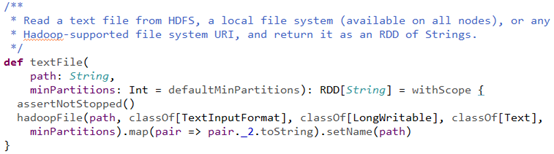
参数分析:
path :String是一个URI,可以是HDFS、本地文件、或者其他Hadoop支持的文件系统
minPartitions:用于指定分区数,具体代码如下,

其中,defaultParallelism对应的就是spark.default.parallelism。如果是从HDFS上
面读取文件,其分区数为文件分片数(Hadoop 1.x中默认为64MB/片,在Hadoop
2.x中默认为128MB/片)。
在textFile中进入hadoopFile,源码如下,
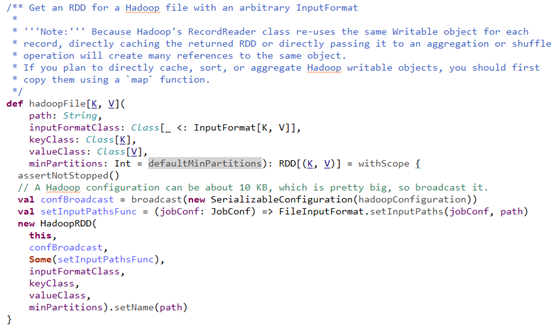
上面代码做了几件事情:
1、获取hadoopConfiguration,并将hadoopConfiguration进行广播;
2、设置任务的文件读取路径;
3、实例化HadoopRDD。
进入到HadoopRDD中,找到getPartitions()方法,源码如下,

getPartitions()方法做了三件事情:
1、获取JobConf,并将其添加信任凭证;
2、获取输入路径格式,并将其按照minPartitions进行split;
3、根据输入的split的个数创建对应的HadoopPartition。
其中getSplits方法的源码如下,
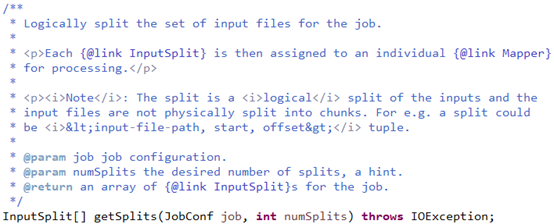
源码在org.apache.hadoop.mapred.FileInputFormat中268行,具体实现如下,
/** Splits files returned by {@link #listStatus(JobConf)} when * they're too big.*/ public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException { //FileStatus对象封装了文件系统中文件和目录的元数据,包括文件的长度、块大小、备份数、修// 改时间、所有者以及权限等信息 FileStatus[] files = listStatus(job); // 从job中获取输入文件状态信息 // Save the number of input files for metrics/loadgen job.setLong(NUM_INPUT_FILES, files.length); //将输入文件个数保存到job中 long totalSize = 0; // compute total size for (FileStatus file: files) { // check we have valid files if (file.isDirectory()) { throw new IOException("Not a file: "+ file.getPath()); } // 遍历当前作业的所有输入文件,然后将累积这些文件的字节数并保存到变量totalSize中 totalSize += file.getLen(); } // 按用户要求划分输入,确定每个split的目标大小goalSize long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // minSplitSize 是FileInputFormat类的成员 ,允许的分区的最小的大小,默认为1B //job.getLong("mapred.min.split.size", 1)是获取配置文件中设置的值,若没有设置,则取1 long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize); // generate splits // 申请一个初始大小为numSplits的数组,来存放划分结果 ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits); // 申请一个网络拓扑,用于划分过程中保存整个网络的拓扑结构 NetworkTopology clusterMap = new NetworkTopology(); for (FileStatus file: files) { Path path = file.getPath(); // 获取文件路径 long length = file.getLen(); // 文件长度(字节数) if (length != 0) { FileSystem fs = path.getFileSystem(job); // 获得hdfs文件系统中的路径信息 BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { // 获得此文件每个block所在位置(节点),可能存在于不同的节点上,所以是个数组 blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(fs, path)) { // 调用文件的getBlockSize方法,获取文件的块大小并存储在变量blockSize中 long blockSize = file.getBlockSize(); // 计算分片的大小,具体实现见后文 long splitSize = computeSplitSize(goalSize, minSize, blockSize); long bytesRemaining = length; // 文件剩余字节数 // 文件剩余大小 大于 切片大小的1.1倍才会继续切片 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { // 获得此split所在的主机位置 String[] splitHosts = getSplitHosts(blkLocations, length-bytesRemaining, splitSize, clusterMap); // 添加分片到结果集,splitHosts表示此文件(path指定)的此分片 //(length-bytesRemaining和splitSize指定)所在的hosts splits.add(makeSplit(path, length-bytesRemaining, splitSize, splitHosts)); bytesRemaining -= splitSize; // 剩余大小 } // 将文件的最后一部分作为一个split if (bytesRemaining != 0) { String[] splitHosts = getSplitHosts(blkLocations, length - bytesRemaining, bytesRemaining, clusterMap); splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining, splitHosts)); } } else { // 文件不可分片,则将整个文件作为一个分片 String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap); splits.add(makeSplit(path, 0, length, splitHosts)); } } else { // 文件长度为0,则生成一个空分片 //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } LOG.debug("Total # of splits: " + splits.size()); return splits.toArray(new FileSplit[splits.size()]); }
其中,每个分片的大小计算方法如下,

goalSize:是根据用户期望的分区数算出来的,每个分区的大小,总文件大小/用户期望分区数
minSize :InputSplit的最小值,由配置参数mapred.min.split.size(在/conf/mapred-site.xml文件中配置)确定,默认是1(字节)
blockSize :文件在HDFS中存储的block大小(在/conf/hdfs-site.xml文件中配置),不同文件可能不同,默认是64MB或者128MB。
结论
Spark从HDFS上读取文件时,按照文件的大小对数据进行分区,具体每个分区的大小通过上述cpmputeSplitSize(long goalSize,long minSize,long blockSize)方法进行计算,一般情况都是取goalSize和blockSize中较小的值。对于不同的文件形式具体可以从以下几个方面进行考虑 :
数据以单文件且文件内容以一行的形式表现
在上述getSplits方法中输出类型InputSplit是对文件进行处理和运算的输入
单位,只是一个逻辑概念,每个InputSplit并没有对文件进行实际的切割,只是记录了要处理的数据的位置(包括文件的path和hosts)和长度(由start和length决定)。因此以行记录形式的文本,可能存在一行记录被划分到不同的block,甚至不同的DataNode上去。通过分析getSplits方法,可以得出,某一行记录同样也可能被划分到不同的InputSplit。但是不会对map之类的操作造成影响,原因是与FileInputFormat关联的RecordReader中的readLine方法在读取数据的时候不会受到InputSplit划分的限制,当读取一行的时候会一直读取直到读取到行结束符为止,因此其能够读取不同的InputSplit,直到把这一行数据读取完成。且当下一次在另外一个InputSplit中再次读取到该行的数据时不会再次进行计算。
数据以单文件且文件内容以多行的形式表现
如果一条请求的内容以多行的形式存储在一个文件中,一条请求的内容可能
会被划分开,出现解析错误,不能保证信息的完整性。
数据以多文件的形式表现
根据getSplits方法的具体实现,由于数据划分的时候是以文件为单位进行遍历的,当一个文件最后的部分不足splitSize时,将单独组成一个InputSplit,不会与下一个文件中的数据进行合并,因此不同文件中的数据不会被分到同一个InputSplit中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号