

向Spark集群提交任务
1.启动spark集群。
启动Hadoop集群
- cd /usr/local/hadoop/
- sbin/start-all.sh
启动Spark的Master节点和所有slaves节点
- cd /usr/local/spark/
- sbin/start-master.sh
- sbin/start-slaves.sh
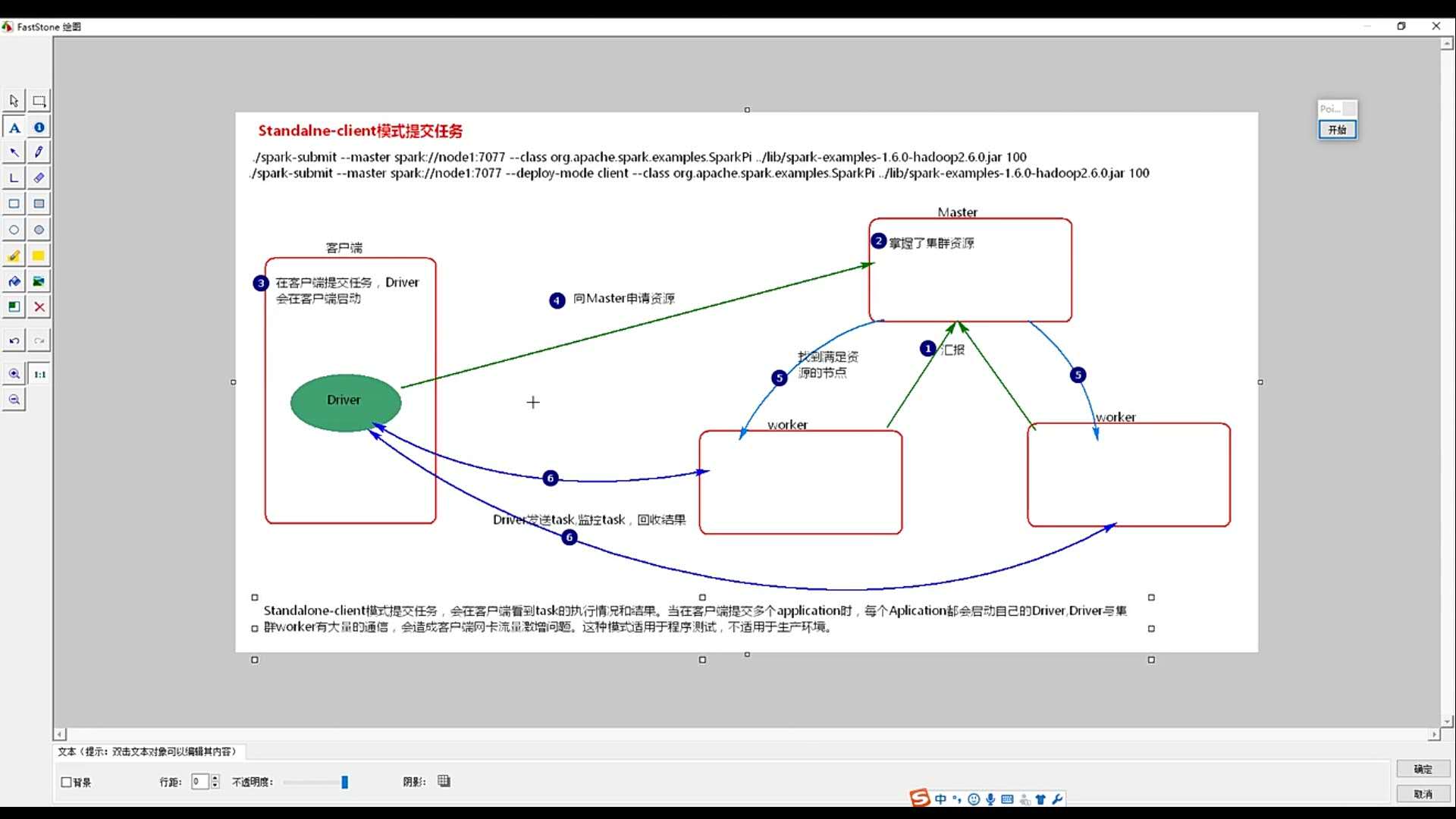
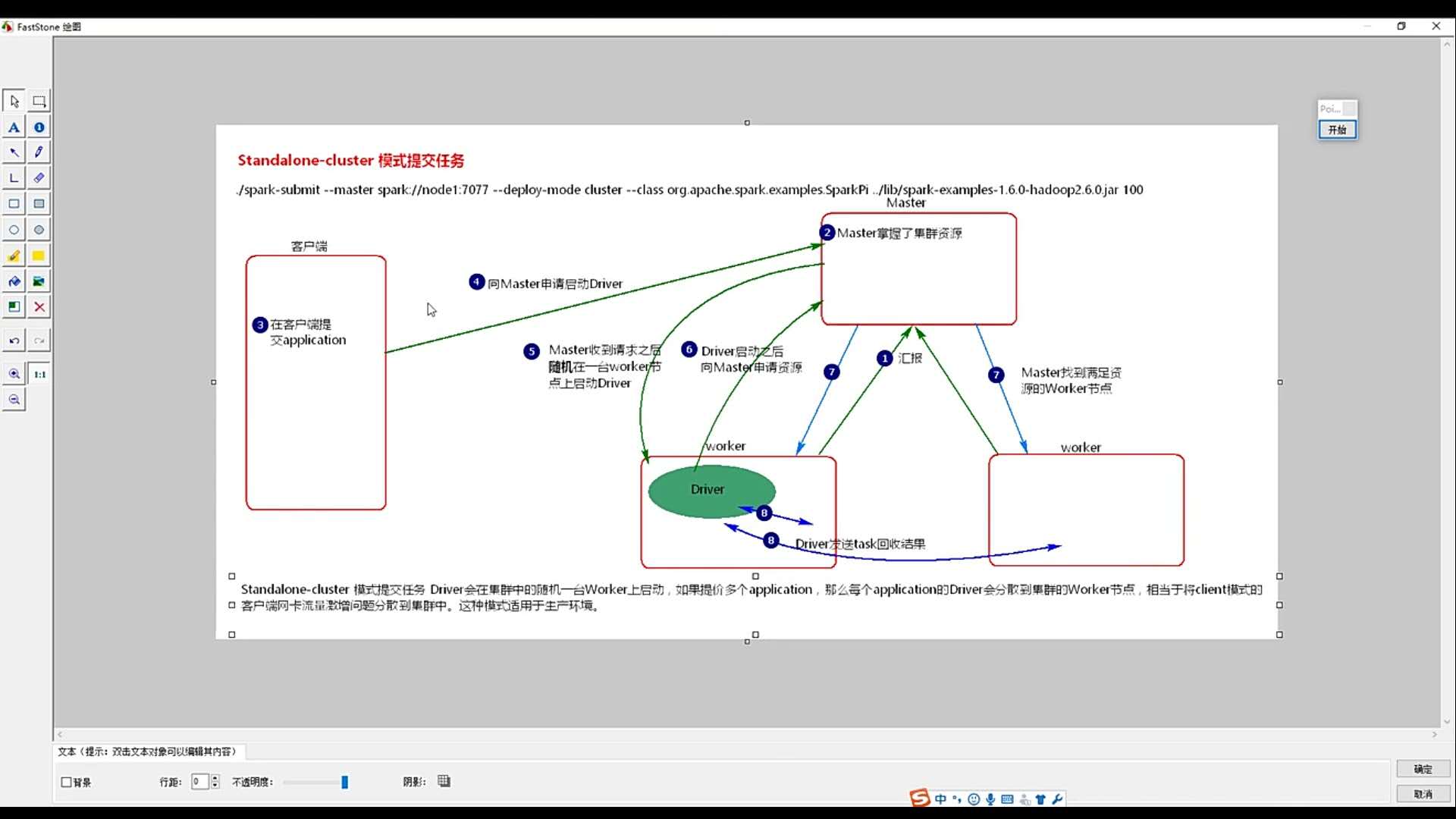
2.standalone模式:
向独立集群管理器提交应用,需要把spark://master:7077作为主节点参数递给spark-submit。下面我们可以运行Spark安装好以后自带的样例程序SparkPi,它的功能是计算得到pi的值(3.1415926)。
在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.11-2.0.2.jar 100 2>&1 | grep "Pi is roughly"
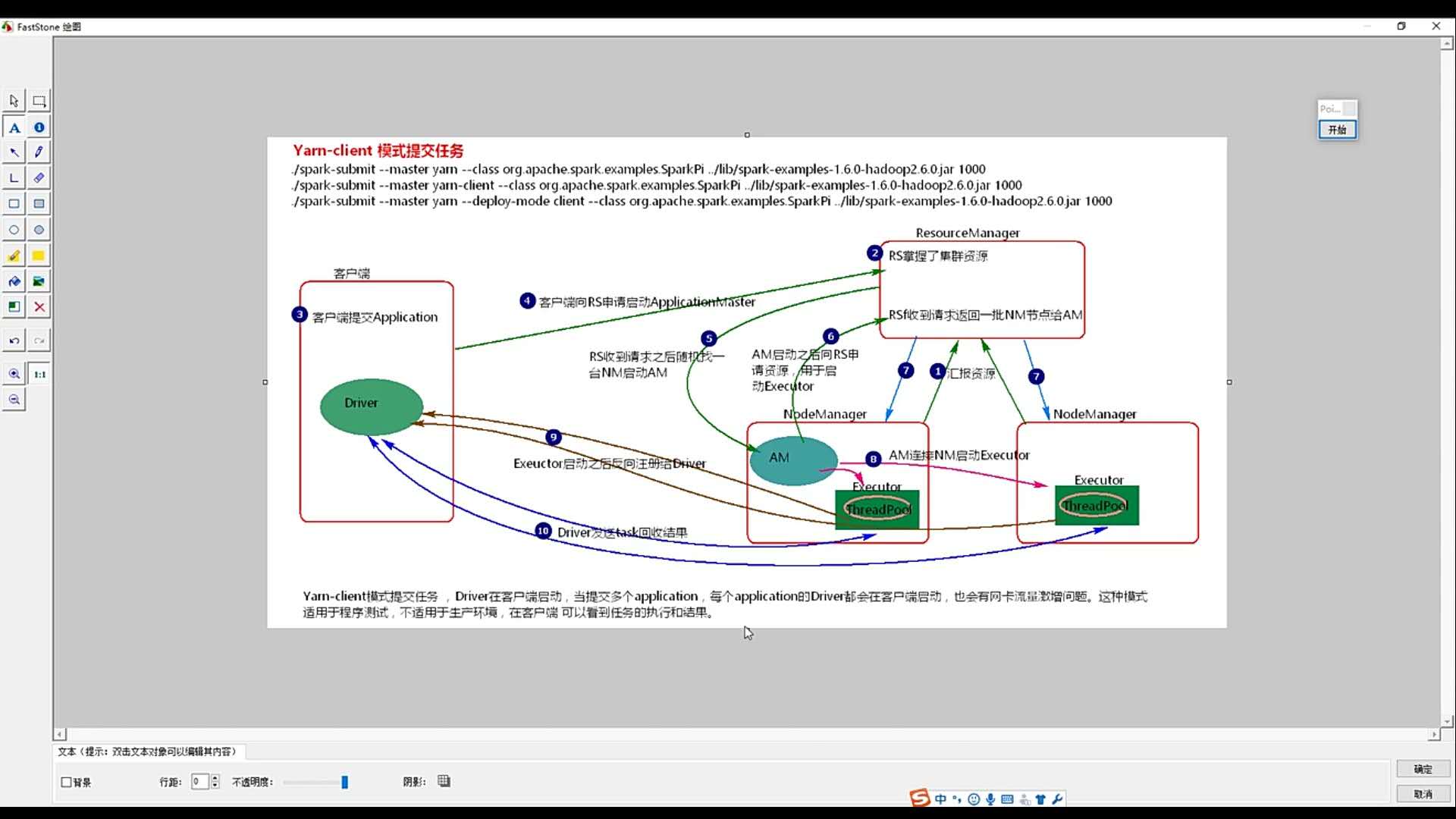
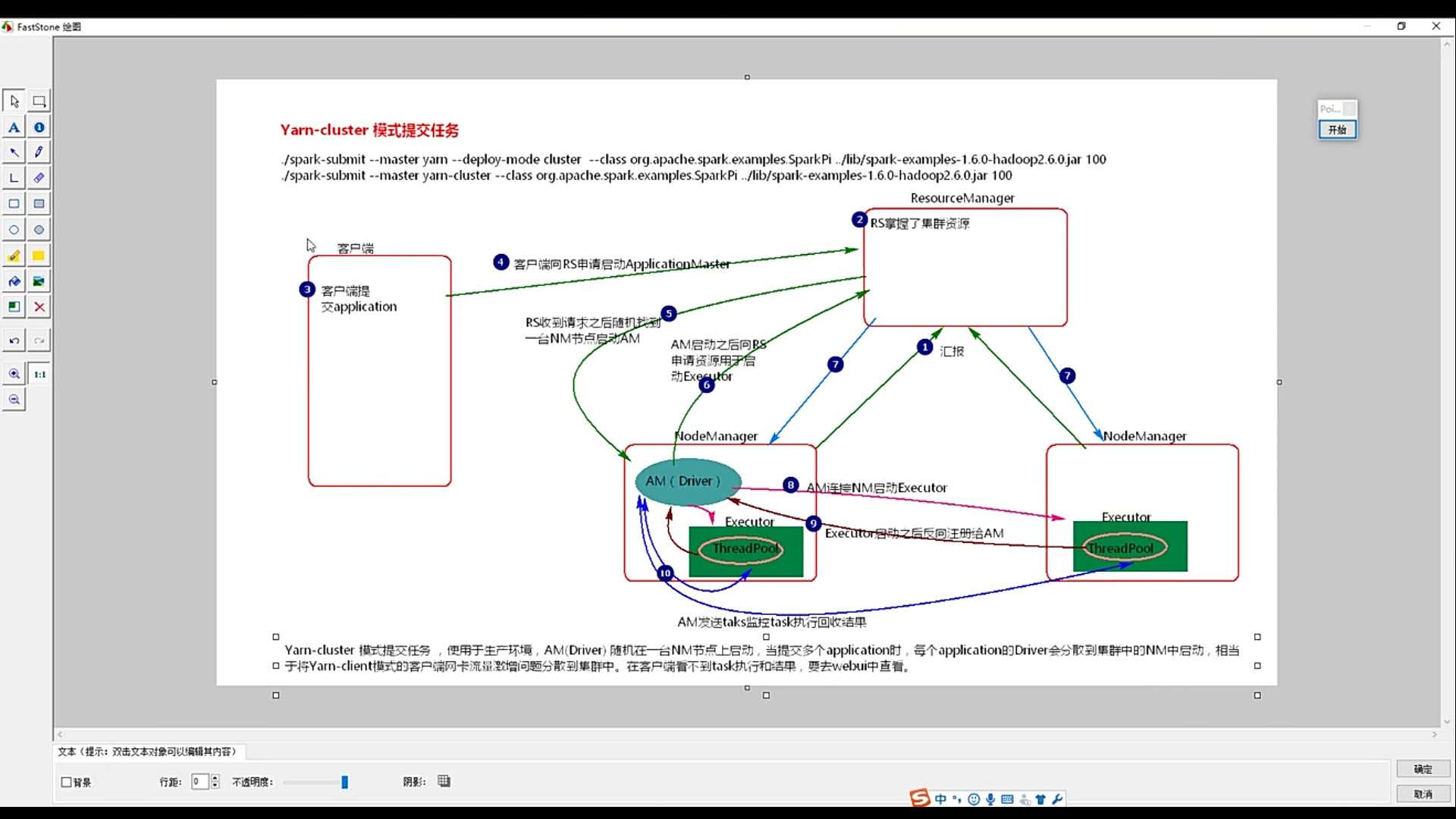
3.hadoop yarn 管理模式:
向Hadoop YARN集群管理器提交应用,需要把yarn-cluster作为主节点参数递给spark-submit。请登录Linux系统,打开一个终端,在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.0.2.jar

输入途中的urI,即可查看任务进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号