mysql redis es对比/梳理
数据存储方式
. mysql:
行存储, 存储结构分为聚簇索引(innodb)和非聚簇索引(myisam),均是采用b+树结构。
聚簇索引:
必有主键索引,主键索引的叶子节点存储了表的数据。非叶子节点都是索引关键字,但是不是记录数据或者数据地址。
可能会有二级索引,二级索引的叶子节点存储的是主键值(而不是行指针)。
(这样可以减少当前行移动时,二级索引的维护,但会让二级索引占用更多的空间)。
非聚簇索引:
主键索引和二级索引存储上没有任何区别,所有的节点都是索引,叶子节点存储的是索引+索引对应的记录的数据。
区别:
- 聚簇索引读一定范围的数据比较快。
- 聚簇索引主键和行数据会缓存到buffer中,用主键查数据更快
- 聚簇索引数据变更减少二级索引的维护工作。
- 插入速度严重依赖于插入顺序,聚簇索引更新主键代价高。
- 聚簇索引二级索引占用一些空间
redis
redis整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。
持久化分为AOF和RDB两种,RDB生成快照文件,AOF日志记录命令。
提供了write和fsync两种方式写入内存。
es
https://zhuanlan.zhihu.com/p/33671444
倒排索引的方式存储。
主要是通过建立一个term index(trie树),这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找(二分法查找term dictionary)。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。
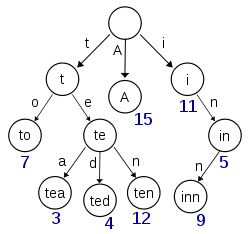
- 为什么比mysql快?
因为比mysql多了term index(存在内存中,以FST(finite state transducers)的形式保存)加快检索,从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。
对于mysql来说,如果你给age和gender两个字段都建立了索引,查询的时候只会选择其中最selective的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。
- es联合索引利用Skip List / bitset 合并。
每一行叫document,每个单词叫term,单词列表叫dictionary。存储的doc-id list叫posting-list(int的数组,存储了所有符合某个term的文档id)。
读写
mysql
- 读
二级索引查找到主键索引-查找到相关数据 - 写
如果主键连续,innodb顺序写io。如果乱序需要取出每条记录对应的物理block,会引起大量的随机io。(innodb提供了insert buffer,合并插入操作,改乱序为顺序)
Redis
- 读内存
- 写入到内存中,如果开了aof,aof会以日志的形式记录每个写操作。
触发方式:有写操作就写、每秒定时写(也会丢数据)。
ES
- 读
查询倒排索引 - 写
先写入buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件。
2)如果buffer快满了,或者到一定时间,就会将buffer数据refresh到一个新的segment file中,但是此时数据不是直接进入segment file的磁盘文件的,而是先进入os cache的。这个过程就是refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会产生一个新的磁盘文件,segment file,这个segment file中就存储最近1秒内buffer中写入的数据。
但是如果buffer里面此时没有数据,那当然不会执行refresh操作咯,每秒创建换一个空的segment file,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中。
操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。
只要buffer中的数据被refresh操作,刷入os cache中,就代表这个数据就可以被搜索到了 - 数据写入 --> 进入ES内存 buffer (同时记录到translog)--> 生成倒排索引分片(segment)
2、将 buffer 中的 segment 先同步到文件系统缓存中,然后再刷写到磁盘
数据一致性保证/容灾
mysql
单节点:
https://sq.163yun.com/blog/article/172546631668785152
mysql存在redo日志和undo日志。通过redo日志和checkpoint保证单机数据不丢失。
redo log记录了对实际数据文件的物理变更(数据文件的什么位置数据做了如何的变更)。
InnoDB也是采用了WAL(日志优先落盘)。
数据库down机回放log文件恢复。
多节点:
MySQL提供了master-slave和group replication 集群级别的容灾方案。
- Master-Slave架构主要思路是:master负责业务的读写请求,然后通过binlog复制到slave节点.
- 主从架构存在数据不一致的问题,所以MySQL5.7出现了Mysql Group Replication方案,mgr采用paxos协议实现了数据节点的强同步,保证了所有节点都可以写数据,并且所有节点读到的也是最新的数据。
ES
单节点也是通过translog的方式恢复,多节点通过增加replica shard解决。
primary shard首先接收client端发送过来的数据,然后将数据同步到replica shard中,当replica shard也写入成功后,才会告知client数据已正确写入,这样就防止数据还没写入replica shard时,primary挂掉导致的数据丢失。
分布式
mysql
master-slave和group replication
Redis
- 主从同步,读写分离。
Master会将数据同步到slave,而slave不会将数据同步到master。Slave启动时会连接master来同步数据。缺点是数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力 - 数据分片模型
可以将每个节点看成都是独立的master,然后通过业务实现数据分片。
结合上面两种模型,可以将每个master设计成由一个master和多个slave组成的模型。
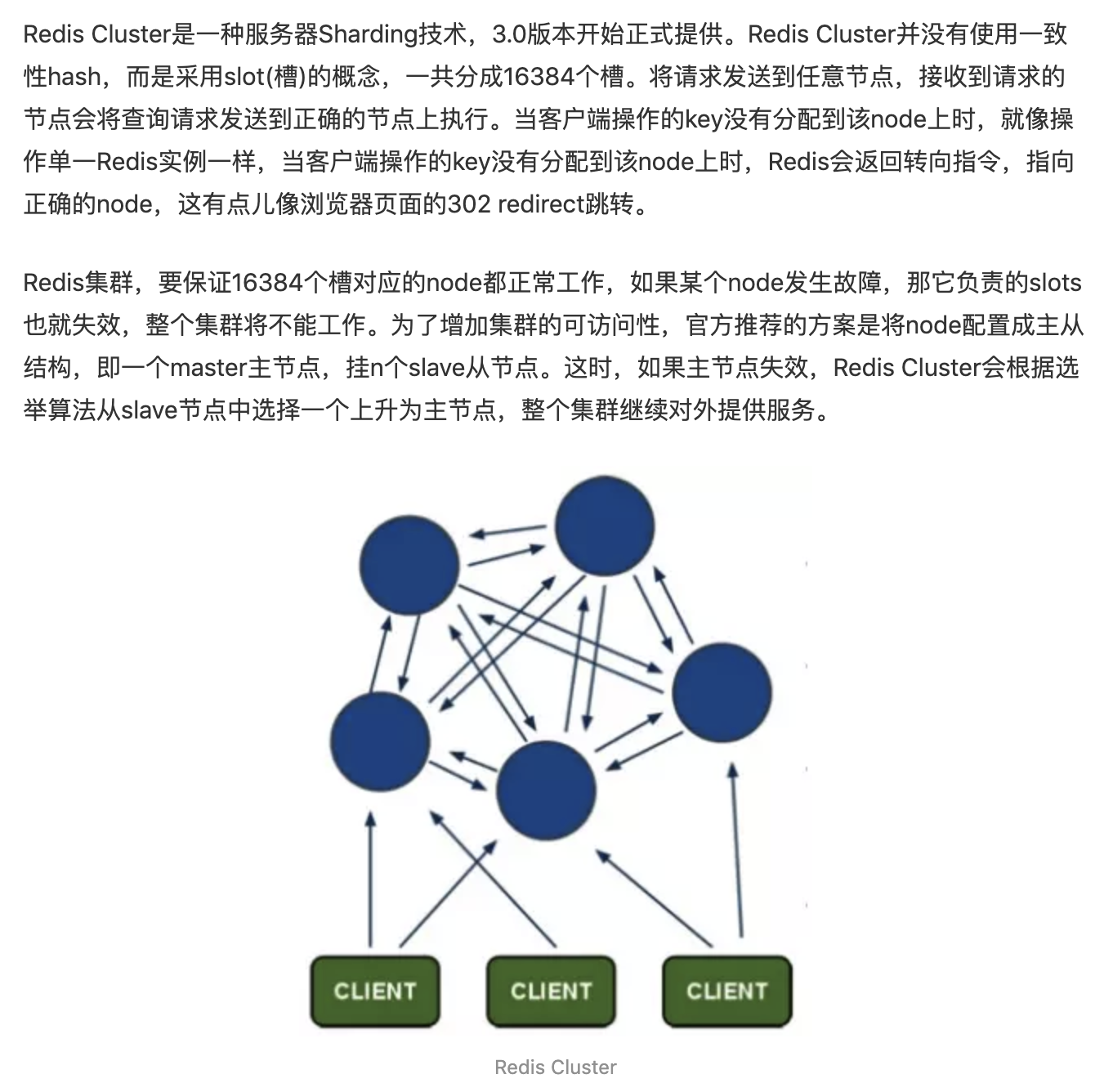
- RedisCluster,存储单元化
将所有存储区域划分为16384个slots(槽位),每个节点负责一部分槽位,槽位的信息存储于每个节点中。当客户端请求进来时候会拉去一份槽位信息列表缓存在本地,RedisCluster的每个节点会将集群的配置信息持久化到自己的配置文件中,所以需要引入一套可维护的配置文件管理方案,尽量做到自动化。
槽位算法:
RedisCluster 默认会根据key使用crc32算法进行hash得到一个整数,然后用这个整数对16384取模定位key所在的槽位。它还运行用户在key字符串里面嵌入tag将key强制写入指定的槽位。
迁移:
- 首先使用CLUSTER GETKEYSINSLOT 命令获取该slot中所有的key, 然后每个key依次用MIGRATE命令转移数据。
- 数据转移完毕之后,正式将slot指派给新的节点
当有新的节点加入或者断开节点时,就会触发Redis槽位迁移。
当一个槽位正在迁移时候在原节点的状态为migrating,在目标节点的状态为importing。
原节点的单个key执行dump指令得到序列化内容,再向目标节点发送restore携带序列化内容作为参数的指令,目标节点接收到内容后反序列化复制到内存中,响应给原节点成功。原节点收到成功响应后把当前节点的key删掉就完成了节点数据迁移。

- Redis主库的灾备模式(Redis Sentinel)
主节点down机的时候只能手动切换机器。所以redis引入了自动切换机器的哨兵架构模式。
前提:
首先哨兵服务单独部署,需要保证高可用。然后引入zookeeper等分布式协调组件,保证哨兵可以感知redis集群的状态。
作用:
哨兵负责监控主节点的监控状态,当主节点不可用时,自动选一个从节点切换为主节点。
触发:
客户端在请求主节点时访问失败,会通过Redis哨兵查询主节点的地址。
成功后再将新的主节点列表缓存到客户端中。
等故障主节点恢复后会作为一个新的只读从节点加入集群。
ES
自己实现的分布式算法,类似raft。
提供分片功能,并且每个分片都有replica。写入时,replica shard会同步数据。
一台机器down机,replica shard会变成primary shard。
如果master down机,重新选主。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号