Redis 梳理
redis
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
内存
内存存储的是命令还是数据页?
redis 持久化, AOF/RDB (数据完整性)
RDB
- RDB生成快照文件:
- 命令:bgsave:redis创建子进程,子进程处理持久化,主进程只会阻塞fork的过程
- 自动触发bgsave:
- save设置,如‘save m n’表示m秒之内数据集存在n次修改时
- 从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
- 执行debug reload命令重新加载Redis时,也会自动触发save操作。
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
- RDB文件处理:
保存:在dir配置指定的目录下,文件名通过dbfilename配置指定。
压缩:Redis默认采用LZF算法对生成的RDB文件做压缩处理
校验:如果Redis加载损坏的RDB文件时拒绝启动 - RDB优点:
- 数据恢复速度快
- 是一个紧凑压缩的二进制文件
- 适用于备份和全量复制或者灾备
缺点:
- 不能做到实时持久化/秒级持久化。
- 每次操作都需要创建子进程,成本高
- RDB文件使用特定二进制格式保存,格式存在新老版本兼容问题
AOF
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
- 过程
1) 所有的写入命令会追加到aof_buf(缓冲区)中。(文本协议格式)
2) AOF缓冲区根据对应的策略向硬盘做同步操作。
3) 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
异步写入硬盘:
写入缓存区后直接返回,同步硬盘操作依赖于系统调度机制。
提供write(延迟写入)fsync(强制写入),
- 配置为always时,每次写入都要同步AOF文件,在一般的STAT硬盘上,Redis只能支持大约几百TPS写入,显然跟Redis高性能特性背道而驰,不建议配置。
- 配置为no,由于操作系统每次同步AOF文件的周期不可控,而且会极大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
- 配置为everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性,理论上只有在系统突然宕机的情况下丢失1s的数据。(严格来说最多丢失1s数据是不准确)
- 重写AOF
- 去掉过期命令 2. 删除无效命令 3. 合并命令
分布式
- 主从同步,读写分离。
Master会将数据同步到slave,而slave不会将数据同步到master。Slave启动时会连接master来同步数据。缺点是数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力 - 数据分片模型
可以将每个节点看成都是独立的master,然后通过业务实现数据分片。
结合上面两种模型,可以将每个master设计成由一个master和多个slave组成的模型。
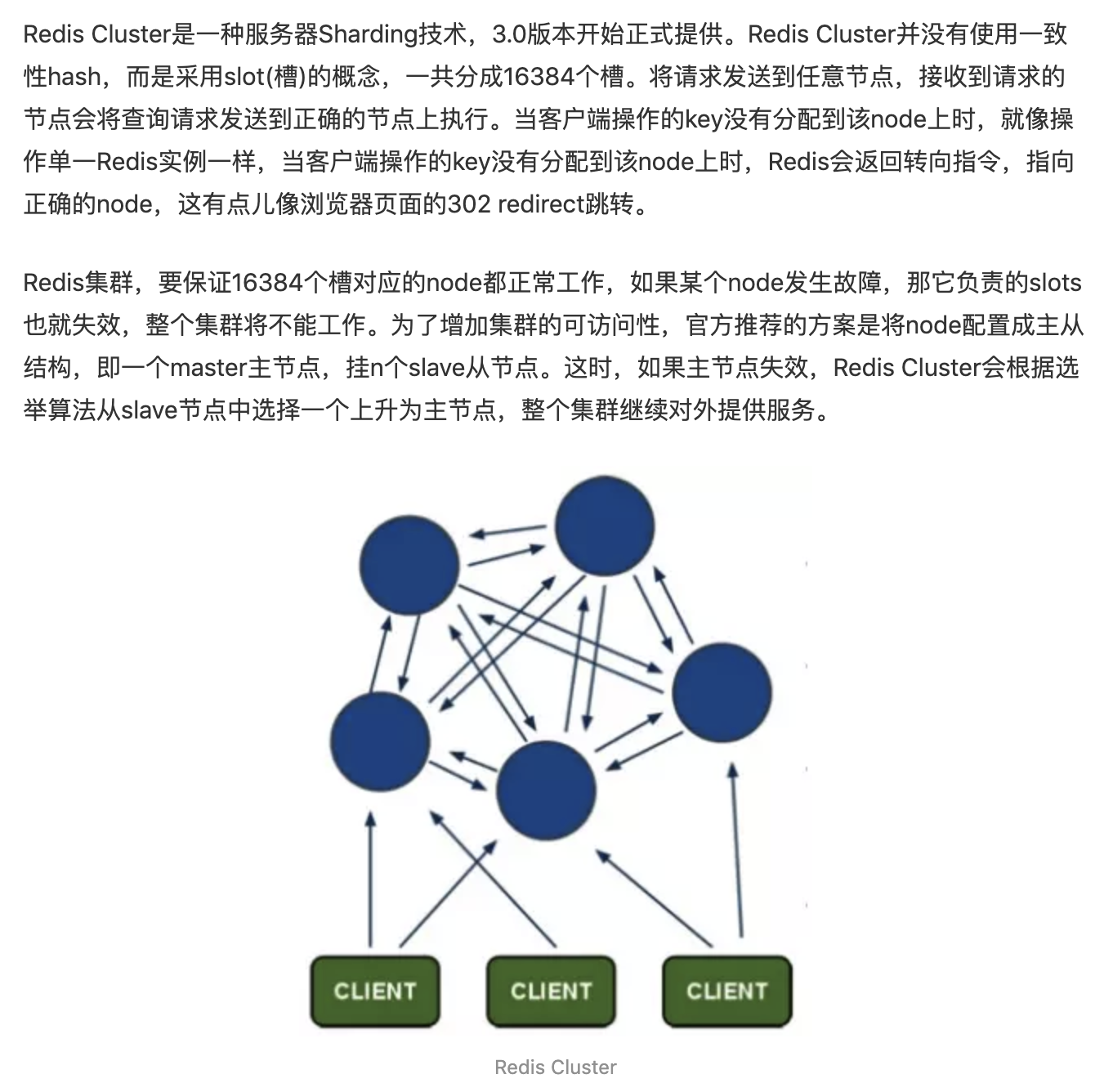
RedisCluster
将所有存储区域划分为16384个slots(槽位),每个节点负责一部分槽位,槽位的信息存储于每个节点中。当客户端请求进来时候会拉去一份槽位信息列表缓存在本地,RedisCluster的每个节点会将集群的配置信息持久化到自己的配置文件中,所以需要引入一套可维护的配置文件管理方案,尽量做到自动化。
槽位算法:
RedisCluster 默认会根据key使用crc32算法进行hash得到一个整数,然后用这个整数对16384取模定位key所在的槽位。它还运行用户在key字符串里面嵌入tag将key强制写入指定的槽位。
迁移:
- 首先使用CLUSTER GETKEYSINSLOT 命令获取该slot中所有的key, 然后每个key依次用MIGRATE命令转移数据。
- 数据转移完毕之后,正式将slot指派给新的节点
当有新的节点加入或者断开节点时,就会触发Redis槽位迁移。
当一个槽位正在迁移时候在原节点的状态为migrating,在目标节点的状态为importing。
原节点的单个key执行dump指令得到序列化内容,再向目标节点发送restore携带序列化内容作为参数的指令,目标节点接收到内容后反序列化复制到内存中,响应给原节点成功。原节点收到成功响应后把当前节点的key删掉就完成了节点数据迁移。
在复制完成之前原节点时处于阻塞状态的,不会进入新的数据,直到原节点的key被删除完成。如果key内容过大就会导致迁移阻塞时间过长,出现卡顿现象,所以再次强调大key的危害

redis主从同步
增量同步:
- 主节点将自己存储在Buffer中的操作指令异步同步给从库,从节点收到同步成功指令后会像主节点上报自己同步到文件偏移量。
- Redis主库的Buffer使用的是环形数组,如果Buffer满了会从数组的头部开始覆盖写入,如果主从延迟过大,就会存在Buffer中的写入速度大于同步速度而导致指令丢失的可能。
快照同步: - 当发现增量同步有丢失数据的风险时,主节点会fork个进程进行RDB发送给从库,从库回放RDB文件,回放完成后通知主库再进行增量同步。
- 如果复制回放rdb文件的时间比Buffer前移的更慢的话,就会导致在RDB同步的过程中Buffer中未同步的指令又被覆盖则rdb同步失败,这样就会导致主库再次进入快照过程中,将新的Rdb文件同步给从库。这样就陷入一个死循环中,我们在平时设计中要考虑到主从延迟导致的Buffer堆积空间大小,给定一个包含网络延迟导致的Buffer堆积的合理大小,做到不低估,不浪费。
无盘复制:
一般为了提升主节点性能我们会将日志文件刷盘的操作交给从库来操作。所谓无盘复制就是主节点通过Socket将快照发生到从节点,主节点一边遍历内存一边发送RDB文件内容,从节点将收到的完整的RDB文件存储到磁盘,再进行回放。
同步复制:Redis的主从复制大部分都是异步的,想要保证数据的强一致性,我们可以使用Redis提供的wait指令进行同步复制,假如将wait的等待时间设置为无限等待从库同步完成,那么当网络发生分区或者延迟较高的时候,就出现严重阻塞,影响Redis的可用性。
过期key的的主从同步:需要注意的一点是在中从同步过程中对于过期key处理是不同的。有一条中原则就是:过期key统一由主节点删除。主节点在删除一条key时会显示的向所有从节点发送一条del指令,从节点在自己的内存遇到过期key时只需要向客户端返回过期,不做删除动作,等待主节点同步del来删除。
Redis主库的灾备模式(Redis Sentinel)
主节点down机的时候只能手动切换机器。所以redis引入了自动切换机器的哨兵架构模式。
前提:
首先哨兵服务单独部署,需要保证高可用。然后引入zookeeper等分布式协调组件,保证哨兵可以感知redis集群的状态。
作用:
哨兵负责监控主节点的监控状态,当主节点不可用时,自动选一个从节点切换为主节点。
触发:
客户端在请求主节点时访问失败,会通过Redis哨兵查询主节点的地址。
成功后再将新的主节点列表缓存到客户端中。
等故障主节点恢复后会作为一个新的只读从节点加入集群。
数据结构底层实现
string:sds
存储长度,可以避免遍历字符串。
按free分配内存,避免每次str变化都要分配内存。
SDS的设计由于根据字符串长度来判断字符串的末尾,因此中间可以存储任何数据包括空字符
struct sdshdr {
//记录buf中字符串的实际长度
int len;
//记录buf数组空闲长度
int free;
//字节数组,用于保存字符串
char buf[];
};
list: zipList + linkedList(双向链表)
ZIPLIST相比LINKEDLIST可以节省内存,默认用ziplist,但由于在zip list添加和删除元素会涉及到数据移动,当list内容较多时,使用双向链表。
hash:zipList + hash table
默认也使用ziplist存储value,保存数据过多时,使用hast table。
-
hashTable:
-
哈希表使用链地址法解决链冲突。每个hash节点都有next指针,多个next构成单向链表。
-
rehash:hash表保存的键值对过多/少,需要对hash表的槽位数组扩展或收缩,以获得更好的性能/内存利用,这个操作成为rehash。redis采用渐进式rehash,同时维护h[0]和h[1]两个表,设置rehash_idx设置为0,在0< rehash_idx < 槽位数组长度时, 会将h[0]槽位数组rehash_idx索引上所有键值对rehash到h[1]。这个过程中查找会同时使用两个表操作。保证h[0]只增不减,rehash完成后,hash表指针指向hd[1],释放hd[0]内存。
-
并不是一次完成rehash,每次curd都会推进rehash的流程,将h[0]的某个dictEntry迁移h[1],rehashidx记录了当前尚未迁移(有待迁移)的ht[0]的bucket位置。
-
什么时候拓展内存?每次addkey的时候,如果装载因子(load factor)超过预定值时自动扩展内存。装载因子 = (used / size);size = dictEntry指针数组的长度
Set:intset + hash table
创建Set类型的key-value时,如果value能够表示为整数,则使用intset类型保存value。
数据量大时,切换为使用hash table保存各个value。
Sorted Set: zipList + skiplist
好文
http://www.uml.org.cn/sjjm/201803161.asp redis原理
https://zhuanlan.zhihu.com/p/97527245 深入了解Redis分布式集群架构
https://juejin.im/post/5a54a6fbf265da3e3f4c9048 Redis Cluster路由查询
https://www.codercto.com/a/57955.html redis-cluster
https://zhuanlan.zhihu.com/p/32540678 redis qa
http://zhangtielei.com/posts/blog-redis-dict.html dict 实现
https://www.jianshu.com/p/872cd13015a8 ziplist && linkedList
https://www.cnblogs.com/binyue/p/5342281.html redis数据结构底层实现list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号