MySQL基础
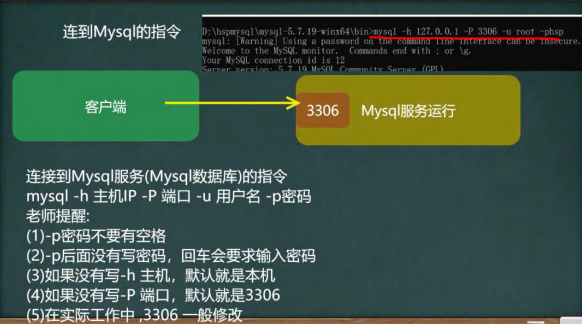
使用命令行窗口链接MySQL数据库。#
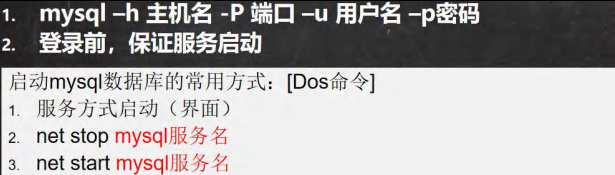
操作示意图。#
数据库三层结构。#
1.所谓安装MySQL数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库。DBMS(database manage system)
2.一个数据库中可以创建多个表。以保存数据。
3.数据库管理系统(DBMS)、数据库和表的关系如图所示。
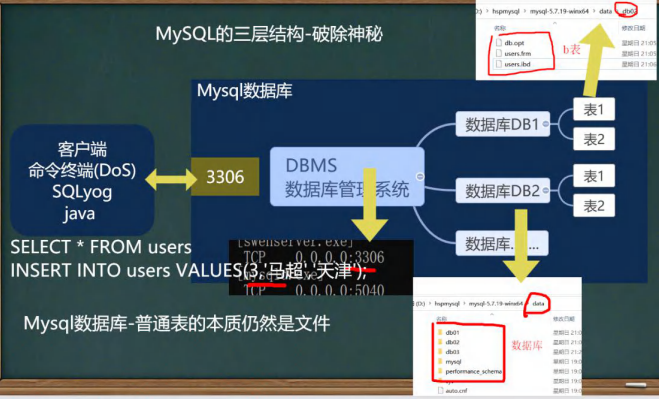
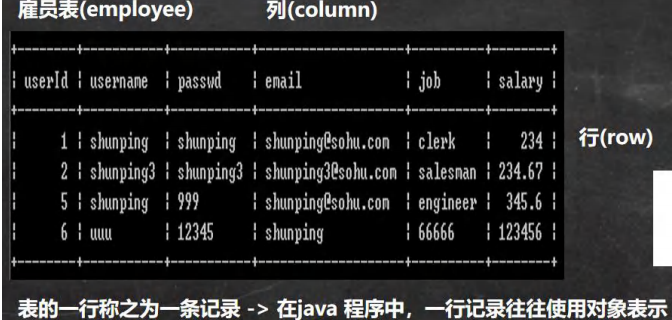
数据在数据库中的方式。#
SQL语句分类。#

操作数据库。#
1.创建一个数据库: CREATE DATABASE zb_db01;
2.删除一个数据库: DROP DATABASE zb_db01;
3.查询字段 :SELECT * FROM WHERE NAME = "tom"
解析:1.select 查询 * 表示所有字段 2.FROM 从哪个表 3.WHERE 从哪个字段 NAME = 'tom' 4.查询名字是 tom
4.查看所有数据库: SHOW DATABASES
5.查看指定数据库:SHOW CREATE DATABASE zb_db01;
6.反引号的使用:为了避免名字与关键字重复可以使用反引号来解决 name;
备份数据库。#
1.备份(注意:只可以在DOS执行(CMD命令行)): mysqld -u 用户名 -p -B 数据库1 数据库2 > 文件名.sql
例:mysqldump -u root -p -B hsp_db02 hsp_db03 > d:\bak.sql
2.恢复(注意:进入MySQL命令再执行): source 文件名.sql
例:source d:\bak.sql
创建表#
1.在数据库中创建一个表:
CREATE TABLE `user`(
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255)
)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
解析: 1.CHARACTER SET 字符集(如果不指定为所在数据库字符集) 2.COLLATE 校对规则(如果不指定为所在数据库校对规则) 3.ENGINE 存储引擎
数据库的基本类型#

1.数据类型也称列类型。
2.默认情况下,基本类型都是默认有符号的,如果想要变成无符号那么就在字段定义后加UNSIGNED
例:
CREATE TABLE t3 (
id TINYINT //默认有符号
age TINYINT UNSIGNED //无符号
);
数值型的基本使用#
一、TINYINT使用说明:
1.说明:在能够满足条件的情况下,尽量选择占用空间小的。
2.使用:
CREATE TABLE t3 (
id TINYINT //有符号 范围:-128~127
);
CREATE TABLE t4 (
id TINYINT UNSIGNED //无符号 范围:0~255
);
INSERT INTO t3 VALUES(255) //超出有符号范围值,插入失败
INSERT INTO t4 VALUES(-1) //超出无符号范围值,插入失败
二、BIT使用说明:
1.bit(m) 中的m的范围值在 1-64
2.添加数据范围按照你给定的数值来确定 比如:bit(8) m=8 代表一个字节 那么他的范围就是 0~255
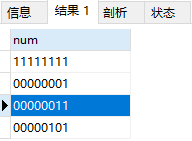
3.显示数据用位来显示:
INSERT INTO t05 VALUES(3);
SELECT * FROM t05; //返回值为3的二进制 11
三、小数值的基本使用:
1.FLOAT(单精度)、DOUBLE(双精度)。
2.DECIMAL(M,D)
1.)可以支持更加精确的小数。 M(精度)是小数位数,D是小数点(标度)后面的位数
2.)如果D是0,则值没有小数点或分数部分。M最大65。D最大30。如果D被省略,默认是0,如果M被省略,默认是10。
3.建议:如果想要小数的精度高,那就是用DECIMAL。
使用示例:
//创建表
CREATE TABLE t06 (
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20)
);
//添加数据
INSERT INTO t06 VALUES(88.12345678912345, 88.12345678912345,88.12345678912345);
SELECT * FROM t06;

四、字符串的基本使用。
1.char(size)固定长度字符串 最大255字符
2.varchar(size)可变长度字符串 最大0~65535字节
使用细节:
1.char(4) 4表示字符数,不是字节数,不管是中文还是字母都是放四个。
varchar(4) 4表示字符数,不管是中文还是英文字母,都是最多存放4个,按照字符来存放。
2.char(4) 是定长(固定长度),即使你插入了两个字符,也会自动占用四个字符的空间。
varchar(4)是变长(变化的长度),如果你插入了两个字符,会按照实际占用的空间来分配。
3.如果数据是固定时,使用char,比如邮编、手机号、身份证号、密码。
如果数据时不固定式,使用varchar,比如留言、文章。
4.char的查询速度比varchar的要快。
5.在使用时,系统会自动预留1-3个字节用来记录数据大小,所以计算字节时要减3
使用案例:
CREATE TABLE t09 (
`name` CHAR(255)
);
CREATE TABLE t10 (
`name` VARCHAR(32766)
)
CHARSET gbk;
// CHAR(size)
// 固定长度字符串 最大 255 字符
// VARCHAR(size) 0~65535 字节
// 可变长度字符串 最大 65532 字节 【utf8 编码最大 21844 字符 1-3 个字节用于记录大小】
// 如果表的编码是 utf8 varchar(size) size = (65535-3) / 3 = 21844
// 如果表的编码是 gbk varchar(size) size = (65535-3) / 2 = 32766
创建表#
1.新建一个表
CREATE TABLE t2(
id INT,
sex CHAR(1),
`name` VARCHAR(6),
birthday DATE,
entry_date DATETIME,
job VARCHAR(32),
salary DOUBLE,
`resume` TEXT
) CHARSET utf8 COLLATE utf8_bin ENGINE INNODB;
2.添加一条数据
INSERT INTO t2 VALUES(1,'男','小妖怪','1999-06-12','2021-6-28 09:15:35','前端',20000,'我是一个小前端,小呀么小前端')
3.修改表
1)ALTER TABLE t2
ADD `image` VARCHAR(32) NOT NULL DEFAULT ''
AFTER resume
//解读:改变 表 t2 添加 image 字段 类型varchar 长度32 不可为空 默认值为空字符串 在resume之后
2)ALTER TABLE t2
MODIFY job VARCHAR(60)
//解读:改变 表 t2 修改 job的长度
3)ALTER TABLE t2
DROP sex
//解读:改变 表 t2 删除 sex字段
4)RENAME TABLE t2 TO `employee`
//解读:将表名改为 employee
5)ALTER TABLE employee CHARSET utf8
//解读:改变表的字符集
6)ALTER TABLE employee
CHANGE `name` `user_name` VARCHAR(32) NOT NULL DEFAULT ''
//解读:修改 表 employee 更换 name 字段为 user_name
7) DESC employee
//解读:查看表的属性
insert插入#
1.insert插入基本使用
CREATE TABLE goods(
id INT,
goods_name VARCHAR(30),
price DOUBLE
)
INSERT INTO goods (id,goods_name,price)
VALUES(1,'华为手机',2000)
INSERT INTO goods (id,goods_name,price)
VALUES(2,'苹果',3000)
2.insert插入的细节说明:
-- 细节说明:
-- 1.插入的数据应与字段的数据类型相同
-- 2.数据的长度应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
-- 3.values中列出的数据位置必须与被加入数据中的位置相对应。
-- 4.字符和日期对象都应该包含在单引号中
-- 5.字段的值可以是空值【前提是该字段允许为空】
-- 6.INSERT INTO goods2 VALUES(),(),() 形式添加多条记录
-- 7.如果是给表中的所有字段添加数据可以不写前面的字段名称
-- 8.默认值的使用,当不给某个字段值时,如果有默认值就会添加,否则报错
update语句#
1.update基本使用:
1)UPDATE employee SET salary = 5000
//解析:更新 employee表 修改 salary字段值为 5000
2)UPDATE employee
SET salary = 3000
WHERE user_name = '小妖怪'
//解析:更新 employee表 修改 salary字段值为 3000 过滤条件 user_name 为 小妖怪的列数据
3)UPDATE employee
SET salary = salary + 1000,resume = '斤斤计较'
WHERE user_name = '老妖怪'
//解析:更新 employee表 修改 salary字段值为 salary的基础+1000 resume字段值改为 斤斤计较 过滤条件 user_name 为 老妖怪的列数据
//注意:如果有多条字段需要修改,使用逗号隔开即可
2.update语句使用细节:

delete语句#
1.delete语句基本使用:
1) DELETE FROM employee
WHERE user_name = '老妖怪'
//解析:删除 来自 employee表 user_name 为 老妖怪的数据
2)如果使用delete语句,不指定where的话,会删除所有的数据,但是不会删除表。
select语句(重点!!)#
1.select语句的基本使用:
CREATE TABLE student(
id INT NOT NULL DEFAULT 1,
NAME VARCHAR(20) NOT NULL DEFAULT '',
chinese FLOAT NOT NULL DEFAULT 0.0,
english FLOAT NOT NULL DEFAULT 0.0,
math FLOAT NOT NULL DEFAULT 0.0
);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(1,'韩顺平',89,78,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(2,'张飞',67,98,56);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(3,'宋江',87,78,77);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(4,'关羽',88,98,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(5,'赵云',82,84,67);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(6,'欧阳锋',55,85,45);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(7,'黄蓉',75,65,30);
-- 1.查询表中所有的学生数据
SELECT * FROM student;
-- 2.查询表中所有学生的姓名和英语成绩
SELECT `name`,english from student
-- 3.过滤表中重复数据
SELECT DISTINCT english FROM student
-- 4.如果筛选条件有两个的话 需要两个字段一致才可以去重
SELECT DISTINCT `name`,english FROM student
-- 5.统计每个学生的总分 使用A
SELECT `name`,(english + chinese + math) FROM student
-- 6.查询姓名为赵云的同学
SELECT * FROM student WHERE name = '赵云'
-- 7.查询英语成绩大于90分的同学
SELECT * FROM student WHERE english > 90
-- 8.查询总分大于200的同学
SELECT * FROM student WHERE (english + chinese + math)
-- 9.查询math大于60分的同学并且id大于90的学生成绩
SELECT * FROM student WHERE math > 60 AND id > 4
-- 10.查询英语成绩大于语文成绩的同学
SELECT * FROM student WHERE english > chinese
-- 11.查询英语成绩在80-90之间的同学
SELECT * FROM student WHERE english BETWEEN 80 AND 90;
-- 12.查询数学分数为 89 90 91的同学
SELECT * FROM student WHERE math IN(89,90,91)
-- 13.查询所有姓李的学生成绩
SELECT * FROM student WHERE `name` LIKE '韩%'
-- 14.查询数学分>80 和 语文分>80的同学
SELECT * FROM student WHERE math > 80 AND chinese > 80;
-- 15.查询语文分数在 70 - 80 之间的同学
SELECT * FROM student WHERE chinese BETWEEN 70 AND 80
-- 16.查询总分为 170 171 172的同学
SELECT * FROM student WHERE (chinese + math + english) IN(170,171,172)
-- 17.查询所有姓韩 或者 姓宋的学生成绩
SELECT * FROM student WHERE `name` LIKE '韩%' OR `name` LIKE '张%'
//解析:LIKE表示模糊查询,
-- 18.查询语文比数学多10分的同学
SELECT * FROM student WHERE chinese - math = 10
-- 19.查询数学成绩从低到高的数据 -desc 从高到低
SELECT * FROM student ORDER BY math
SELECT * FROM student ORDER BY math DESC
-- 20.对总分从高到低的顺序输出 --使用别名
SELECT `name`,(chinese + english + math) AS total_score FROM student
ORDER BY total_score DESC
-- 21.过滤表中重复数据
SELECT DISTINCT english FROM student
-- 22.如果筛选条件有两个的话 需要两个字段一致才可以去重
SELECT DISTINCT `name`,english FROM student
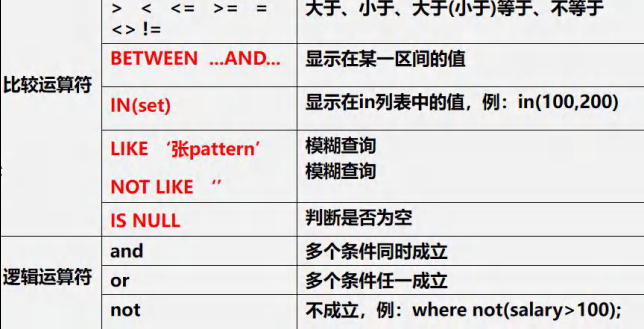
运算符#
合计函数/统计函数#
1.count()返回行(数据)的总数
示例:SELECT COUNT(*) FROM emp
2.sum () 统计一个总数。
示例:SELECT SUM(math) FROM student;
// 查询到所有数学成绩的总分
3.avg() 查询一个数的平均数。
示例:SELECT AVG(math) FROM student;
// 求一个班级总分平均分
4.max/min 返回最大值/最小值
示例:SELECT MAX(math) AS math_high_socre, MIN(math) AS math_low_socre FROM student;
// 求出班级数学最高分和最低分
5.group by having 以某个字段分组
示例:SELECT AVG(sal), MAX(sal) , deptno
FROM emp GROUP BY deptno
having (其他条件);
-- 按照部门来分组查询
字符串相关函数#
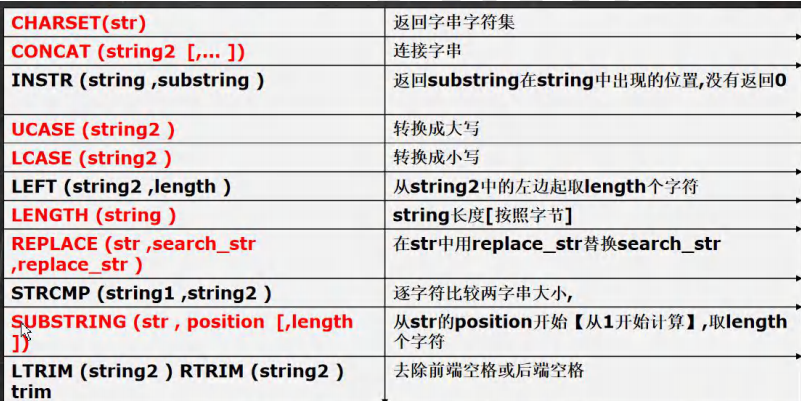
-- 1. CHARSET 返回字段的字符集
SELECT CHARSET(ename) FROM emp;
-- 2.concat 连接字符串 将多个列拼接成一列
SELECT CONCAT(ename,'的工作是',job) FROM emp;
SELECT CONCAT(ename,'的薪资是',sal) FROM emp;
-- 3.UCASE 将字母全部转换为大写
SELECT UCASE(ename) FROM emp;
-- 4.LCASE 将字母全部转换为小写
SELECT LCASE(ename) FROM emp;
-- 5.LENGTH 获取字段长度
SELECT LENGTH(ename) FROM emp;
-- 6.REPLACE 替换指定字段 参数说明:(cloumn,要替换的字段,值)
SELECT ename, REPLACE(job,'MANAGER', '经理') FROM emp;
-- 7.SUBSTRING 截取字符串 参数说明:(cloumn,开始位置,截取长度)
SELECT SUBSTRING(ename, 2, 5) FROM emp;
数学相关函数#
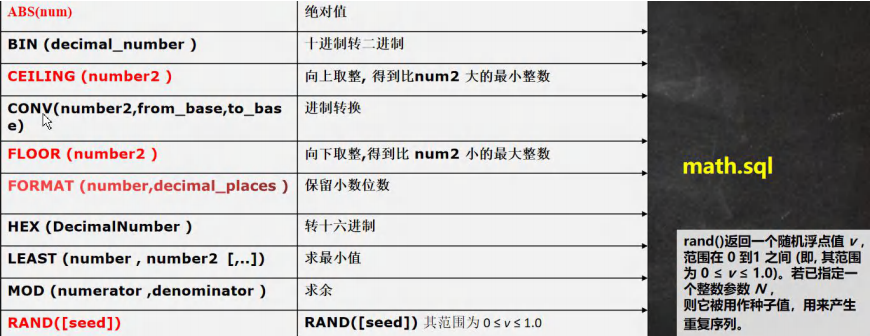
-- 演示数学相关函数
-- 1.ABS(num) 绝对值
SELECT ABS(- 10 ) FROM DUAL;
-- 2.BIN (decimal_number )十进制转二进制
SELECT BIN( 10 ) FROM DUAL;
-- 3.CEILING (number2 ) 向上取整, 得到比 num2 大的最小整数
SELECT CEILING(- 1.1 ) FROM DUAL;
-- 下面的含义是 8 是十进制的 8, 转成 2 进制输出
-- 4.CONV(number2,from_base,to_base) 进制转换
SELECT CONV( 8, 10, 2 ) FROM DUAL;
-- 5.下面的含义是 8 是 16 进制的 8, 转成 2 进制输出
SELECT CONV( 16, 16, 10 ) FROM DUAL;
-- 6.FLOOR (number2 ) 向下取整,得到比 num2 小的最大整数
SELECT FLOOR(- 1.1 ) FROM DUAL;
-- 7.FORMAT (number,decimal_places ) 保留小数位数(四舍五入)
SELECT FORMAT( 78.125458, 2 ) FROM DUAL;
-- 8.LEAST (number , number2 [,..]) 求最小值
SELECT LEAST( 0, 1, - 10, 4 ) FROM DUAL;
-- 9.MOD (numerator ,denominator ) 求余
SELECT MOD ( 10, 3 ) FROM DUAL;
-- 10.随机数 RAND()
-- 1. 如果使用 rand() 每次返回不同的随机数 ,在 0 ≤ v ≤ 1.0
-- 2. 如果使用 rand(seed) 返回随机数, 范围 0 ≤ v ≤ 1.0, 如果 seed 不变,
-- 该随机数也不变了
-- RAND([seed]) RAND([seed]) 返回随机数 其范围为 0 ≤ v ≤ 1.0
SELECT RAND() FROM DUAL;
SELECT RAND(1) FROM DUAL;
时间日期相关函数#
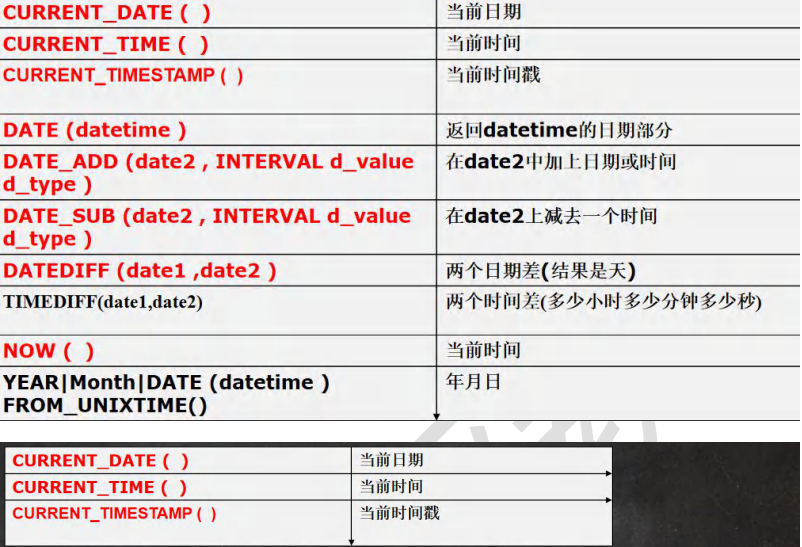
-- 1.返回当前日期
SELECT CURRENT_DATE FROM DUAL
-- 2.返回当前时间
SELECT CURRENT_TIME FROM DUAL
-- 3.返回当前时间戳
SELECT CURRENT_TIMESTAMP FROM DUAL
-- 4.返回DATETIME的日期部分
SELECT DATE('2023-06-12 15:25:00') FROM DUAL
-- 5.计算两个时间相差多久 返回相差天数
SELECT DATEDIFF('2023-04-25','1999-09-13') FROM DUAL
-- 6.在指定日期中 加上一个时间 并返回符合条件的数据
SELECT * FROM mes WHERE DATE_ADD(send_time,INTERVAL 30 MINUTE) >= NOW();
-- 7.在指定日期中 减去一个时间 并返回符合条件的数据
SELECT * FROM mes WHERE DATE_SUB(NOW(),INTERVAL 40 MINUTE) <= send_time
PS:详情请查看 MySQL文件夹中datetime.sql文件。
多表查询#
说明:多表查询是指基于两个或者两个表以上的表查询。
示例:SELECT * from emp,dept (两个表)
注意:1.当多表查询时,过滤条件得是表的数量-1,否则会出现笛卡尔集
2.当使用两个表中的相同字段时,要表明要使用的是哪个表的哪个字段,否则会报错。
自连接#
说明:自连接是指在同一张表的连接查询【将同一张表看做两张表】。
示例:SELECT woker.ename as '职工表', boss.ename as '上级表'
FROM emp woker,emp boss
WHERE woker.mgr = boss.empno
注意:使用自连接时一定要使用别名 否则就会报错。
子查询#
-- 什么是子查询?
-- 子查询是嵌入在其他SQL语句中的select语句,也叫嵌套查询
-- 1.单行子查询是指 只返回一行数据的子查询
-- 2.多行子查询是指 返回多行数据的子查询,使用关键字In
-- 单行子查询 查询与Smith同一部门的所有员工
SELECT deptno FROM emp WHERE ename = 'SMITH'
SELECT * FROM emp
WHERE deptno = (
SELECT deptno
FROM emp
WHERE ename = 'SMITH'
)
-- 多行子查询 查询部门10的工作相同的雇员
-- 名字 岗位 工资 部门号 但不含10自己
SELECT DISTINCT job FROM emp WHERE deptno = 10
SELECT ename,job,sal,deptno
FROM emp WHERE job in (
SELECT DISTINCT job
FROM emp
WHERE deptno = 10
) AND deptno != 10




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现