最近公共祖先 和 树上区间操作(树上差分、树链剖分)
LCA#
基本定义:最近公共祖先简称 LCA(Lowest Common Ancestor)。两个结点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。
简单来讲,就是两个点到根的路径上,深度最深的重合点
常用的求解方法:
- 朴素方法
每次选择深度较深的那个结点,往上走一步,直到两个结点重合,这个重合点就是
此方法查询一次 的时间复杂度为
const int maxn = 5e5 + 10;
vector<int>gra[maxn];
int dep[maxn], fa[maxn];
// 预处理深度
void dfs(int now, int pre, int d)
{
dep[now] = d;
fa[now] = pre;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == pre) continue;
dfs(nex, now, d + 1);
}
}
// 一步步向上求 LCA
int LCA(int a, int b)
{
while(a != b)
{
if(dep[a] < dep[b]) swap(a, b);
a = fa[a];
}
return a;
}
- 倍增法
上述方法慢的地方在于,每次都只走一步,因此我们优化的时候考虑每次走向上走 步
具体实现:
-
如果两个点深度不一致:选取较深的点,往上跳,直到深度一致
-
深度相同,判断一下是不是同一个点,如果是,则说明 就是该点,否则进行 步骤 3
-
两个点同时往上走,从大到小枚举,判断他们的第 级祖先是否相等,如果不相等,则证明肯定不是 LCA,往上跳
-
步骤 3 结束后,得到的应该是两个 的子结点,因此直接返回其中一个结点的父结点
第三个步骤,类似于二分的过程
接下来考虑如何计算所有结点的第 级祖先
设 结点的第 级祖先为
可以直接求出第 级祖先(父亲),即
考虑状态转移:
因此我们只要先计算出所有结点的第 级祖先,就可以计算出其第 级祖先
预处理时间复杂度:
询问一次 LCA 的时间复杂度:
const int maxn = 5e5 + 10;
vector<int>gra[maxn];
int fa[maxn][25], dep[maxn];
// 求深度 以及 所有结点的第 0 级祖先
void dfs(int now, int pre, int cur)
{
if(dep[now]) return;
dep[now] = cur;
fa[now][0] = pre;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == pre) continue;
dfs(nex, now, cur + 1);
}
}
// 预处理
void init()
{
for(int i=1; i<=20; i++)
for(int j=1; j<=n; j++)
fa[j][i] = fa[fa[j][i-1]][i-1];
}
// 查询 LCA
int LCA(int a, int b)
{
if(dep[a] < dep[b]) swap(a, b);
int dif = dep[a] - dep[b];
for(int i=20; i>=0; i--)
{
if(dif >= (1 << i))
{
a = fa[a][i];
dif -= 1 << i;
}
}
if(a == b) return a;
for(int i=20; i>=0; i--)
{
if(fa[a][i] != fa[b][i])
{
a = fa[a][i];
b = fa[b][i];
}
}
return fa[a][0];
}
树上两点的最短路径#
树上最短路径显然就是从一个结点上升到 后再下降到另一个结点的路径
考虑如果多次询问两点间的最短路径:
-
考虑预处理 级祖先的时候,同时加上距离来预处理
-
考虑利用容斥:两个点到根的距离,再减去 到根的距离
显然第二种方法更优秀:
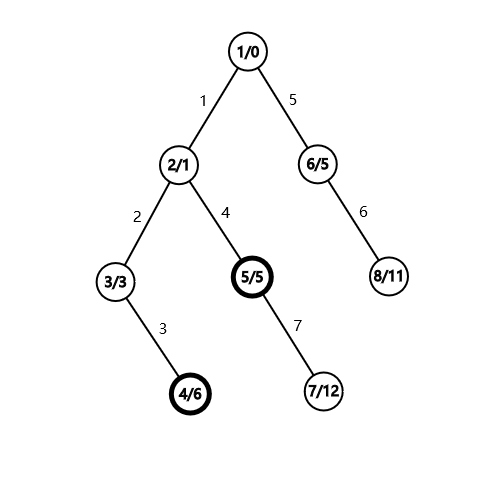
ll query(int u, int v)
{
int lca = LCA(u, v);
return dis[u] - dis[lca] * 2 + dis[v];
}
树上差分#
树上差分用于树上两点间路径的区间修改,能做到修改时间复杂度 ,查询的时间复杂度为
虽然这个时间复杂度上不及树链剖分,但是好写,核心代码就几行
我们定义点 的值为 ,并且定义一个差分数组 ,有
根据上述的定义,我们可以先求子节点的值,再求本身的值,所以整个查询过程就是 的过程
代码的话其实可以不考虑点原始的初始值,只用给 数组进行操作就行,最终的答案就是 修改后的增值 + 初始值
const int maxn = 1e5 + 10;
int dif[maxn];
void dfs(int now, int pre)
{
for(int nex : gra[now])
{
if(nex == pre) continue;
dfs(nex, now);
dif[now] += dif[nex];
}
}
考虑修改的过程:
如果让树上一个点的 ,根据查询的过程,就会将树上从 到 根 的整一条链都加上一个值,如果在这条链上的某个点 同样进行 的操作,我们就使链 到 区间加和了
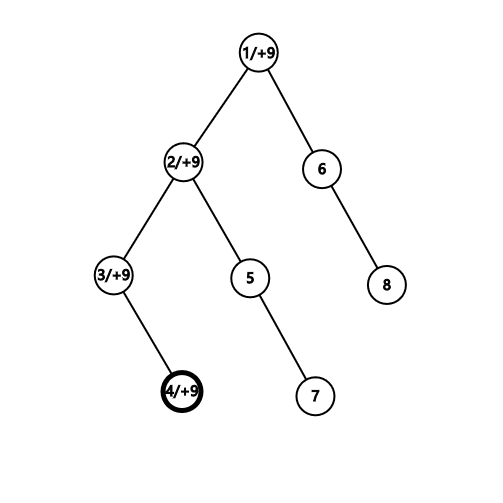
将 号结点视为
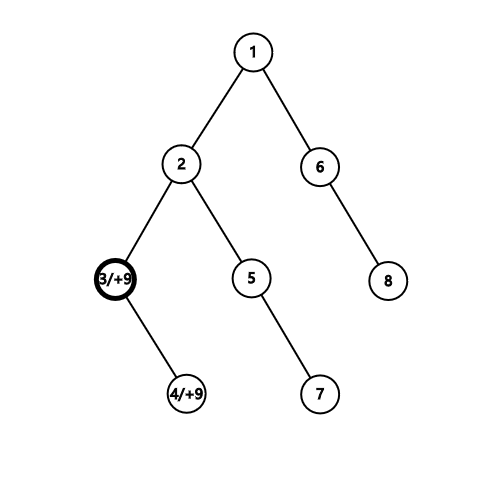
将 号结点视为
无论是怎样的两点之间树上路径,我们都可以将其差分成两个直链
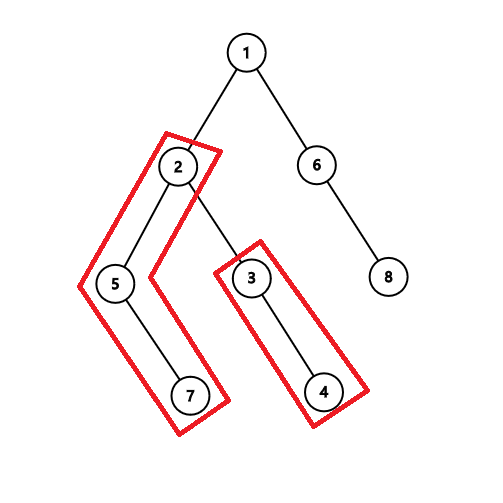
因此树上差分可以写成以下方式
inline void add (int u, int v, int x)
{
int lca = LCA(u, v);
dif[u] += x;
dif[v] += x;
dif[lca] -= x;
dif[fa[lca]] -= x;
}
有的时候并不是维护树上点权,而是维护树上边权,就要考虑将边权化为点权
我们可以利用树上每个点仅有一条边是指向根的方向,将所有的边权视为它深度较深的点的点权
但是差分的时候并不用考虑 的值,因此是变成两个不相交的直链
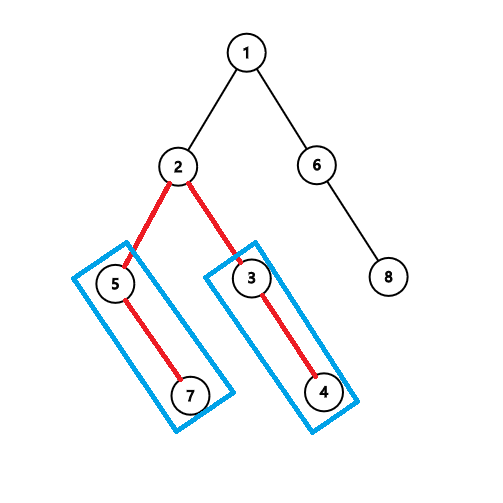
inline void add(int u, int v, int x)
{
int lca = LCA(u, v);
dif[u] += x;
dif[v] += x;
dif[lca] -= x * 2;
}
序#
序:每个结点在 深度优先遍历中的进出栈的时间序列
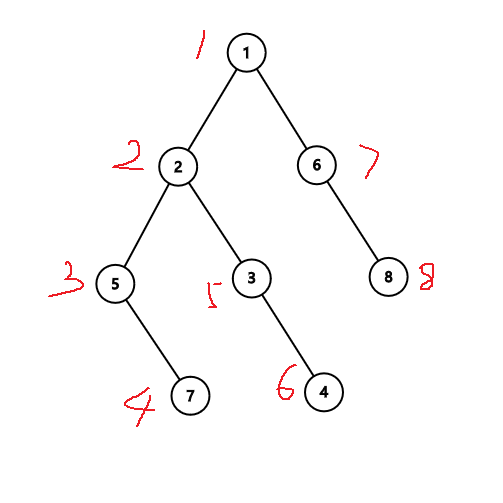
const int maxn = 1e5 + 10;
int dfn[maxn], tp = 0;
void dfs(int now, int pre)
{
tp++;
dfn[now] = tp;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == pre) continue;
dfs(nex, now);
}
}
序,其实相当于重新给每个点进行编号,根据搜索回溯的过程,可以发现子树上的 序是连续的一段
在上述的基础上,我们可以以子树为单位维护一些信息
例如:子树上所有点都加上 ,我们可以直接套用 分块、线段树、树状数组 等数据结构,将其视为连续序列,直接修改
因此我们的 序要维护两个东西,子树中,连续 的左端和右端
const int maxn = 1e5 + 10;
int dfn[maxn], bot[maxn], tp = 0;
void dfs(int now, int pre)
{
tp++;
dfn[now] = tp;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == pre) continue;
dfs(nex, now);
}
bot[now] = tp;
}
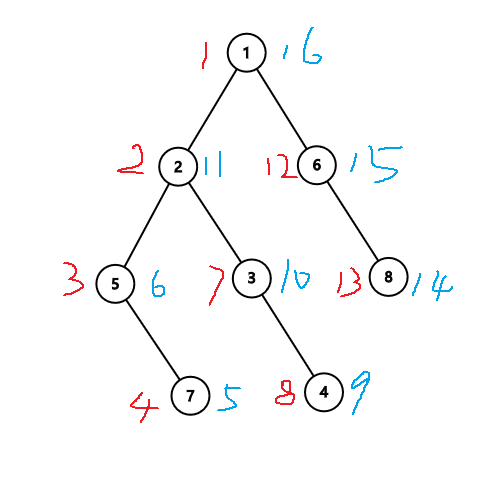
针对于 序,还有另外一种写法:每进入和回溯的时候都记录一下当时的时间戳,并让时间戳
这样做的好处是, 预处理后,可以在 的复杂度下,判断两个点之间的祖先关系
const int maxn = 1e5 + 10;
int in[maxn], out[maxn], tp = 0;
void dfs(int now, int pre)
{
dfn[now] = ++tp;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == pre) continue;
dfs(nex, now);
}
out[now] = ++tp;
}
inline bool is_ance(int u, int v)
{
return in[u] <= in[v] && out[u] >= out[v];
}
上述这种维护方式也可以引申出一个 欧拉序 的求解 的做法:将 问题在 的复杂度下,转化为 问题
树链剖分#
树链剖分的形式有很多种:重链剖分、长链剖分、 中的剖分,我们下面讲的是重链剖分
考虑在树上求解一些区间问题:
-
子树区间修改、查询
-
两点之间路径的修改、查询
上述所说的 序能够很好的处理第一个问题,但是第二个问题仍得到不到解决
思考我们现有的区间修改数据结构:差分、分块、线段树、树状数组
线段树和树状数组要求是在下标连续的区间内作修改,因此我们考虑能不能利用 序,将一棵树剖分成若干条链,然后维护每一条链上的信息,做到区间修改
构造重链剖分#
给出部分定义:
-
重子结点:该结点的子结点中子树最大的子结点,且每个结点最多只有一个重子结点,如果有多个最大的子结点,则选取其中一个作为其重子结点
-
轻子结点:除了重子结点外的所有子结点
-
重边:结点到重子结点的边
-
轻边:结点到轻子结点的边
的时候,就优先按照重子结点搜,形成一条条链
图源:oi-wiki
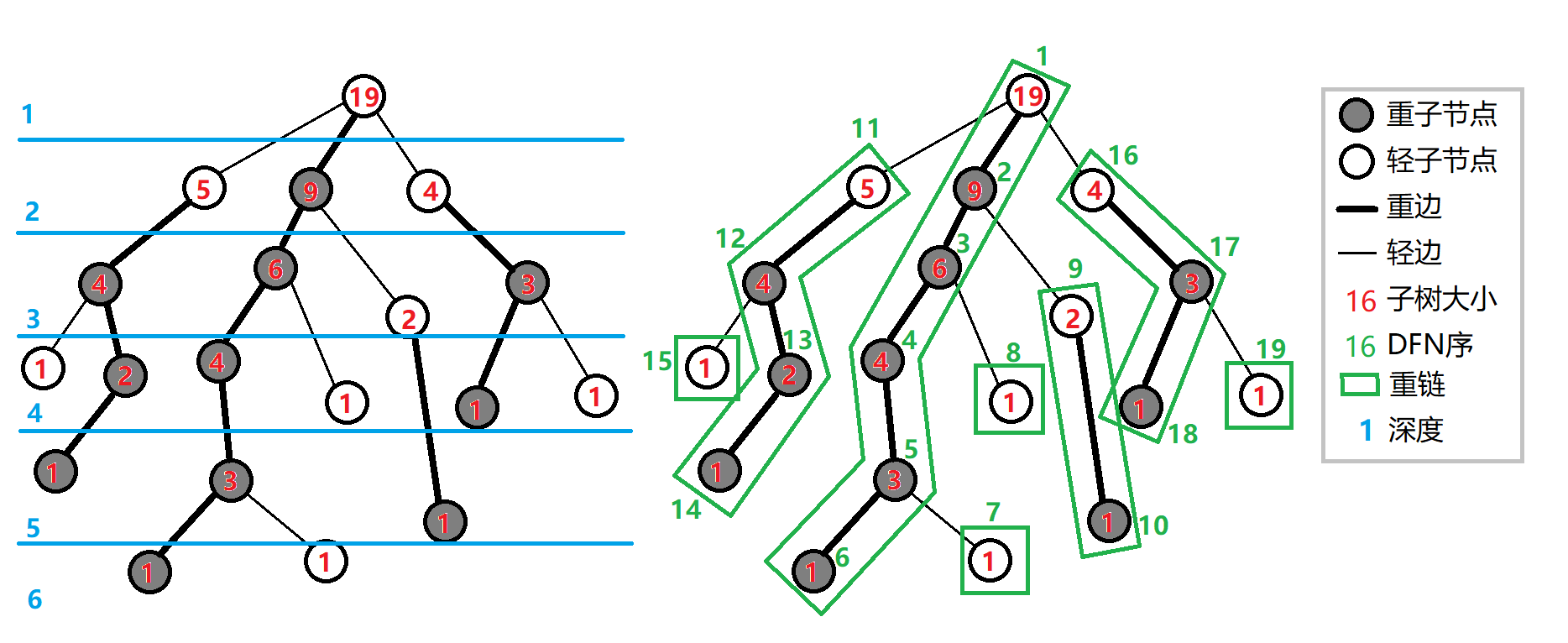
树链剖分总共要维护以下信息:
-
: 结点的父结点
-
: 结点所在的深度
-
:以 为根的子树大小(所含结点数)
-
: 结点的重子结点
-
: 结点的 序
-
: 序的第 个结点,
-
: 结点所在链的链顶结点(深度最小)
-
:以 为根的子树中,最大的 序
上述信息建议分成两次 来解决
第一次 维护:、、、 的信息
int dep[maxn], siz[maxn], hson[maxn], fa[maxn];
void dfs1(int now, int pre, int d)
{
dep[now] = d;
siz[now] = 1;
hson[now] = -1;
fa[now] = pre;
for(auto nex : gra[now])
{
if(nex == pre) continue;
dfs1(nex, now, d + 1);
siz[now] += siz[nex];
if(hson[now] == -1 || siz[hson[now]] < siz[nex])
hson[now] = nex;
}
}
第二次 维护:、、、
int tp = 0;
int dfn[maxn], bot[maxn], rnk[maxn], top[maxn];
void dfs2(int now, int t)
{
tp++;
dfn[now] = tp;
rnk[tp] = now;
top[now] = t;
if(hson[now] != -1)
{
dfs2(hson[now], t);
for(auto nex : gra[now])
{
if(nex == fa[now] || nex == hson[now]) continue;
dfs2(nex, nex);
}
}
bot[now] = tp;
}
综上,可以保证每个结点属于且仅属于一条重链,树链剖分预处理的时间复杂度为:
树链剖分后,在树上遍历任意一条路径的时间复杂度:
与启发式合并相类似,如果当前点处于一个轻边上,则每往上走一步,整颗子树的大小必然增大至少一倍
这样每个结点最多切换 次轻边
重链剖分使用#
- 求
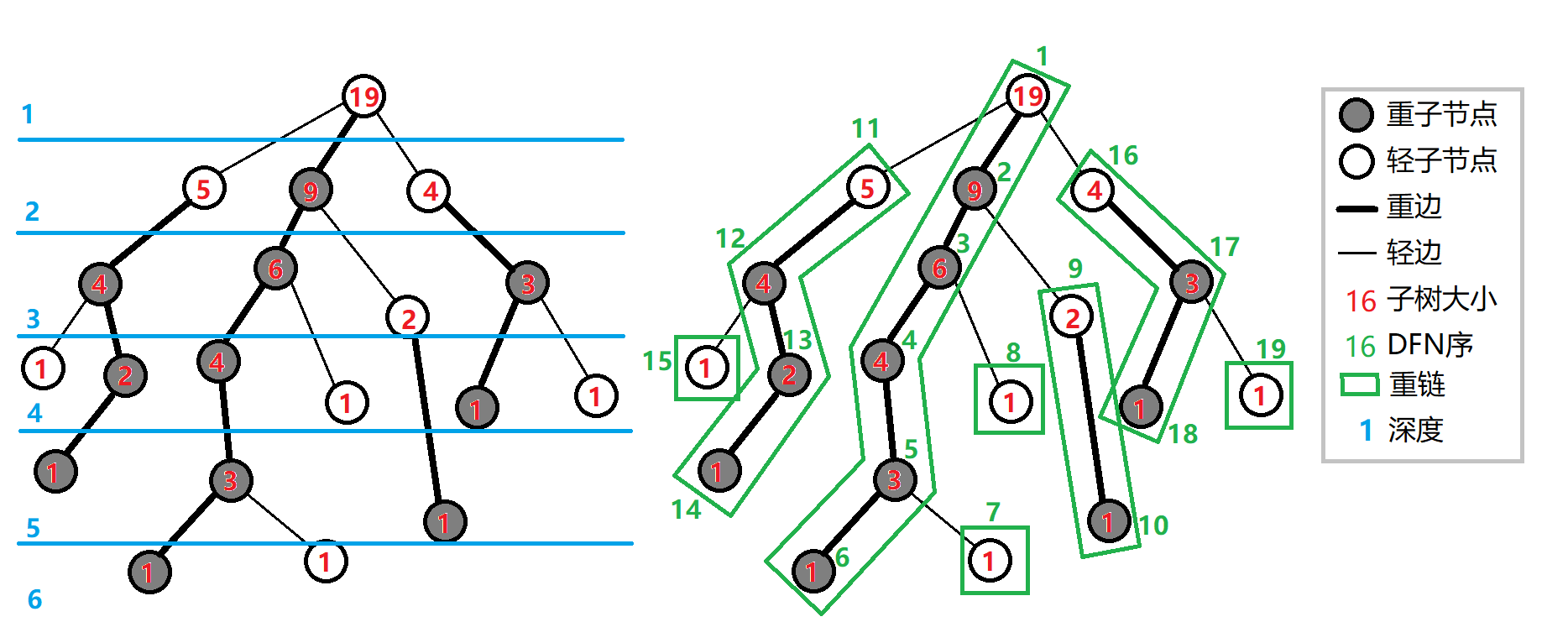
分割重链之后,每次都选取两个结点所在的重链中, 较深的那个,然后往上升,直到两个结点同处于一条链中
如果同处于一条链中,则 为深度较浅的那个点
int LCA(int a, int b)
{
while(top[a] != top[b])
{
if(dep[top[a]] < dep[top[b]]) swap(a, b);
a = fa[top[a]]; // 一定要记得到了链顶还要再往上走一步,上升到另外一条重链
}
return dep[a] < dep[b] ? a : b;
}
- 路径上维护信息
例题:Aladdin and the Return Journey
大意:给出一个树,每个点有点权,有两种操作:
-
给一个点的点权加上
-
求两个点的最短路径上的全部点权和
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
const int maxn = 3e4 + 10;
vector<int>gra[maxn];
int dep[maxn];
int siz[maxn];
int hson[maxn];
int fa[maxn];
int top[maxn];
int dfn[maxn];
int rnk[maxn];
int tr[maxn << 2];
int w[maxn]; // 每个点的起始点权
// 建树,特别要注意的是,建树是根据 dfn 来建树的!
// 这里的 l r 是 dfn 的值,而不是点的编号
void build(int now, int l, int r)
{
if(l == r)
{
// rnk[l],返回 dfn 第 l 个点的编号,然后赋初值
tr[now] = w[rnk[l]];
return;
}
int mid = l + r >> 1;
build(now << 1, l, mid);
build(now << 1 | 1, mid + 1, r);
tr[now] = tr[now << 1] + tr[now << 1 | 1];
}
// 区间查询
int query(int now, int l, int r, int L, int R)
{
if(L <= l && r <= R)
return tr[now];
int mid = l + r >> 1;
int ans = 0;
if(L <= mid)
ans += query(now << 1, l, mid, L, R);
if(R > mid)
ans += query(now << 1 | 1, mid + 1, r, L, R);
return ans;
}
// 单点修改
void update(int now, int l, int r, int x, int val)
{
if(l == r)
{
tr[now] = val;
return;
}
int mid = l + r >> 1;
if(x <= mid)
update(now << 1, l, mid, x, val);
else
update(now << 1 | 1, mid + 1, r, x, val);
tr[now] = tr[now << 1] + tr[now << 1 | 1];
}
// 第一次 dfs
void dfs1(int now, int pre, int d)
{
siz[now] = 1;
hson[now] = -1;
dep[now] = d;
fa[now] = pre;
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == fa[now]) continue;
dfs1(nex, now, d + 1);
siz[now] += siz[nex];
if(hson[now] == -1 || siz[hson[now]] < siz[nex])
hson[now] = nex;
}
}
int tp = 0;
// 第二次 dfs
void dfs2(int now, int t)
{
top[now] = t;
tp++;
dfn[now] = tp;
rnk[tp] = now;
if(hson[now] != -1)
{
dfs2(hson[now], t);
for(int i=0; i<gra[now].size(); i++)
{
int nex = gra[now][i];
if(nex == fa[now] || nex == hson[now]) continue;
dfs2(nex, nex);
}
}
}
// 初始化
void init(int n, int rt = 1)
{
tp = 0;
dfs1(rt, rt, 1);
dfs2(rt, rt);
build(1, 1, n);
for(int i=0; i<=n; i++) gra[i].clear();
}
int solve(int a, int b, int n)
{
int ans = 0;
// 在寻找 LCA 的过程中,顺便统计路径上的全部值
while(top[a] != top[b])
{
if(dep[top[a]] < dep[top[b]]) swap(a, b);
ans += query(1, 1, n, dfn[top[a]], dfn[a]);
a = fa[top[a]];
}
if(dep[a] > dep[b]) swap(a, b);
// 在同一条链上的时候统计最后一段
ans += query(1, 1, n, dfn[a], dfn[b]);
return ans;
}
int main()
{
int t;
scanf("%d", &t);
for(int casee=1; casee<=t; casee++)
{
printf("Case %d:\n", casee);
int n;
scanf("%d", &n);
for(int i=0; i<n; i++) scanf("%d", &w[i]);
for(int i=1; i<n; i++)
{
int x, y;
scanf("%d%d", &x, &y);
gra[x].push_back(y);
gra[y].push_back(x);
}
init(n, 0);
int q;
scanf("%d", &q);
while(q--)
{
int x;
scanf("%d", &x);
if(x == 0)
{
int i, j;
scanf("%d%d", &i, &j);
// 询问
printf("%d\n", solve(i, j, n));
}
else
{
int i, v;
scanf("%d%d", &i, &v);
// 单点修改
update(1, 1, n, dfn[i], v);
}
}
}
return 0;
}
题单#
| 题号 | 题目 | 标签 | 难度 | 题解 |
|---|---|---|---|---|
| 洛谷-P3379 | 【模板】最近公共祖先(LCA) | LCA | 1 | 👍 |
| SPOJ-QTREE2 | Query on a tree II | LCA | 2 | 👍 |
| CodeForces-1328E | Tree Queries | LCA + 思维 + dfs序 | 3 | 👍 |
| CodeForces-1304E | 1-Trees and Queries | LCA + 思维 | 3 | 👍 |
| CodeForces-1702G | Passable Paths | LCA + 思维 | 3 | 👍 |
| HDU-3830 | Checkers | LCA + 思维 | 5 | 👍 |
| HDU-2874 | Connections between cities | 树上距离 | 1 | 👍 |
| POJ-1986 | Distance Queries | 树上距离 | 1 | 👍 |
| 洛谷-P3258 | 松鼠的新家 | 树上差分 | 1 | 👍 |
| POJ-3417 | Network | LCA + 树上差分 | 3 | 👍 |
| 洛谷-P2680 | 运输计划 | 二分 + 树上差分 | 4 | 👍 |
| HDU-3966 | Aragorn's Story | 树链剖分 | 1 | 👍 |
| POJ-2763 | Housewife Wind | 树链剖分 | 1 | 👍 |
| LightOJ-1348 | Aladdin and the Return Journey | 树链剖分 | 1 | 👍 |
| 洛谷-P3178 | 树上操作 | 树链剖分 | 1 | 👍 |
| POJ-3237 | Tree | 树链剖分 | 2 | 👍 |
| 计蒜客-39272 | Tree | 树链剖分 | 3 | 👍 |
| SPOJ-QTREE3 | Query on a tree again! | 树链剖分 + 二分 | 3 | 👍 |
| 洛谷-P2486 | 染色 | 树链剖分 | 3 | 👍 |
| HDU - 5052 | Yaoge’s maximum profit | 树链剖分 | 4 | 👍 |
| HDU - 5840 | This world need more Zhu | 树链剖分 + 分块 | 5 | 👍 |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)