

promethues + alertmanager 监控centos7.4 主机 systemd 服务 (20201203)
注: 个人学习记录
官网:https://prometheus.io/
下载地址:https://prometheus.io/download/
文档:https://prometheus.io/docs/introduction/overview/
环境:
192.168.11.153 Prometheus + alertmanager # prometheus服务端和报警
192.168.11.114 node-export # 被监控主机
安装prometheus服务端
1. 在192.168.11.153安装prometheus服务端
[root@jenkins soft]# wget https://github.com/prometheus/prometheus/releases/download/v2.23.0/prometheus-2.23.0.linux-amd64.tar.gz # 下载软件 [root@jenkins soft]# tar -xf prometheus-2.23.0.linux-amd64.tar.gz # 解压缩 [root@jenkins soft]# mv prometheus-2.23.0.linux-amd64 /usr/local/prometheus/ # 移动到/usr/local/下叫prometheus目录
2. 查看配置文件等
[root@jenkins soft]# cd /usr/local/prometheus/ # 进入prometheus目录

# prometheus: 可执行程序,GO语言编写,已经打包好的,可以直接执行
# prometheus.yml: prometheus配置文件
# promtool: promethues检查工具
# 此配置文件是经过修改过后的配置文件,添加了规则文件存放路径和文件动态发现node配置,注释了静态发现。配置了于aletermanger的连接。
[root@jenkins prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting: # alertmanager配置文件
alertmanagers:
- static_configs:
- targets: # 地址
- 127.0.0.1:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: # 创建告警规则存放文件
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#static_configs:
#- targets: ['localhost:9090']
- job_name: 'test_cluster' # 创建一个job
file_sd_configs: # 此job基于文件动态添加node
- files: ['/usr/local/prometheus/sd_config/*.yml'] # 动态添加node的文件路径
refresh_interval: 5s
#- job_name: 'test_docker'
# static_configs: # 静态添加node
# - targets: ['192.168.11.114:9100']
# labels:
# name: docker
3. 将Prometheus添加进systemd进行管理
[root@jenkins prometheus]# cat /usr/lib/systemd/system/prometheus.service [Unit] Description=prometheus.service [Service] ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml # 启动指定配置文件 Restart=on-failure [Install] WantedBy=multi-user.target
4. 启动prometheus
[root@jenkins prometheus]# systemctl start prometheus
[root@jenkins prometheus]# ss -antulp | grep :9090
tcp LISTEN 0 128 :::9090 :::* users:(("prometheus",pid=2249,fd=9))
5. 浏览器访问prometheus
http://192.168.11.153:9090/
# 可以在这个界面使用promeSQL查看监控的数据,后面再说。
# Status------->Service Discovery 查看发现的被监控端的机器
# Status------->Targets 查看被监控的机器的状态
# Status------->Rules 查看配置的告警规则
# Status------->Configuration 查看prometheus的配置文件
# Graph 可以编辑promeSQL,查看收集到的数据,可以做sql调试,也可以用图形化展示;不过图形化展示建议配合grafna做。
# Alerts 可以查看告警的状态
# 至此,Prometheus服务端安装完毕,会自动监控自己本身。
# 安装node-export,Prometheus数据采集有不同的采集工具,export是官方给出的采集node数据的工具,另外官方网站还给出了很多基于服务的采集工具,例如:consul_export、mysql_export等等
1. 在192.168.11.114上安装node_export
[root@localhost soft]# wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz # 下载 [root@localhost soft]# tar -xf node_exporter-1.0.1.linux-amd64.tar.gz # 解压 [root@localhost soft]# mv node_exporter-1.0.1.linux-amd64/ /usr/local/node_exporter/ # 移动到/usr/local/下
2. 查看目录文件

# node_export 可执行文件,可以直接启动
# node_export --help 可以查看更多关于node_export的用法,比如打开某个数据采集,有些是默认禁用了的
3. 将node_export配置到systemd进行管理,我们将监控sshd,nginx,docker服务,所以打开systemd的数据采集,默认是关闭的状态
[root@localhost node_exporter]# cat /usr/lib/systemd/system/node_exporter.service [Unit] Description=prometheus.node1 [Service] ExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(nginx|docker|sshd).service # 打开systemd的数据采集,以及添加监控的白名单,支持正则表达式 Restart=on-failure [Install] WantedBy=multi-user.target
4. 启动服务
[root@localhost ~]# systemctl start node_exporter.service
[root@localhost ~]# ss -antulp | grep :9100
tcp LISTEN 0 128 :::9100 :::* users:(("node_exporter",pid=1745,fd=3))
# 可以通过http://192.168.11.114:9100/metrics 查看监控到的数据信息
# 至此,被监控端node_expor安装完成
# prometheus配置文件配置文件服务发现或者静态,本次配置的文件发现node主机。
1. 修改prometheus配置文件
# 在prometheus.yaml中添加
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#static_configs: # 静态
#- targets: ['localhost:9090']
- job_name: 'test_cluster' # 创建一个job
file_sd_configs: # 此job基于文件动态添加node
- files: ['/usr/local/prometheus/sd_config/*.yml'] # 动态添加node的文件路径
refresh_interval: 5s # 隔 5s检查一次文件是否有新增或删除
2.检查prometheus配置文件是否有错误
[root@jenkins prometheus]# ./promtool check config prometheus.yml
3. 根据prometheus配置文件中配置的文件发现路径创建文件,上面配置的*.yml是因为支持通配符
[root@jenkins prometheus]# cat /usr/local/prometheus/sd_config/node.yml - targets: ['192.168.11.114:9100'] #labels: # 可以设置标签 # name: docker - targets: ['192.168.11.153:9090'] #labels: # name: prometheus
3. 没有错误可重新加载配置文件,也可以重启prometheus
[root@jenkins prometheus]# ps -aux | grep prometheus root 2249 0.1 3.5 1051844 66460 ? Ssl 10:36 0:36 /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml root 2865 0.0 0.0 112824 984 pts/0 S+ 15:55 0:00 grep --color=auto prometheus [root@jenkins prometheus]# kill -hup 2249 # kill -hup 加上PID
4. 在prometheus的web页面Status----->Service Discovery查看是否发现了192.168.11.114:9100的node
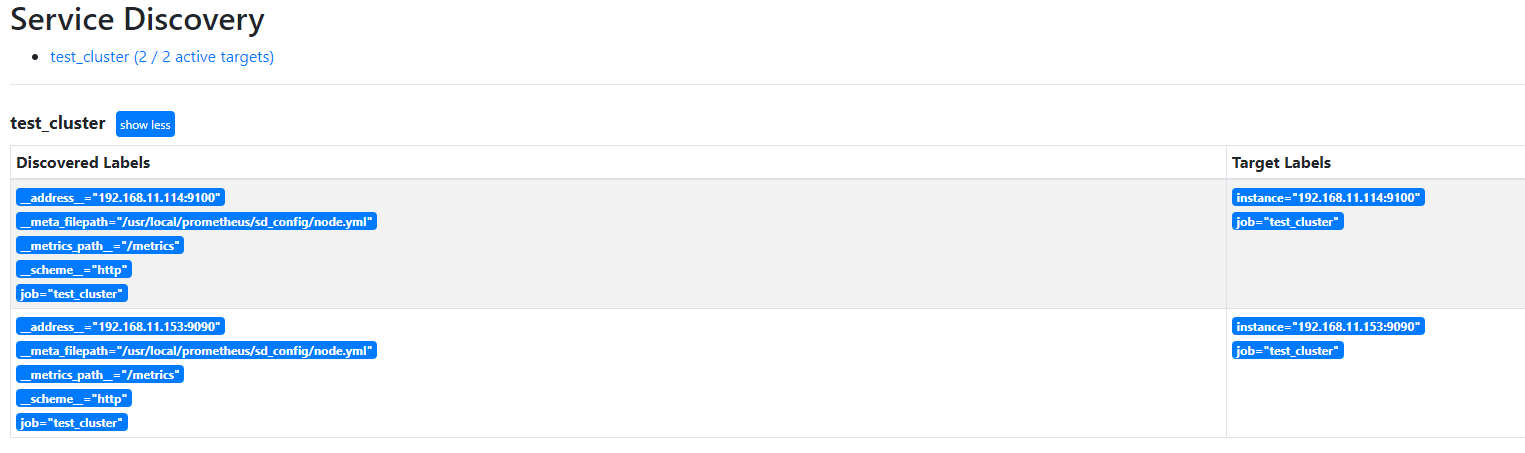
5. 在Status----->Targets可以查看当前发现的node状态是否是正常的,up为正常

# 还可以更具上面Endpoint的连接,查看收集的数据
6. 在Prometheus上利用sql查看node的CPU的数据
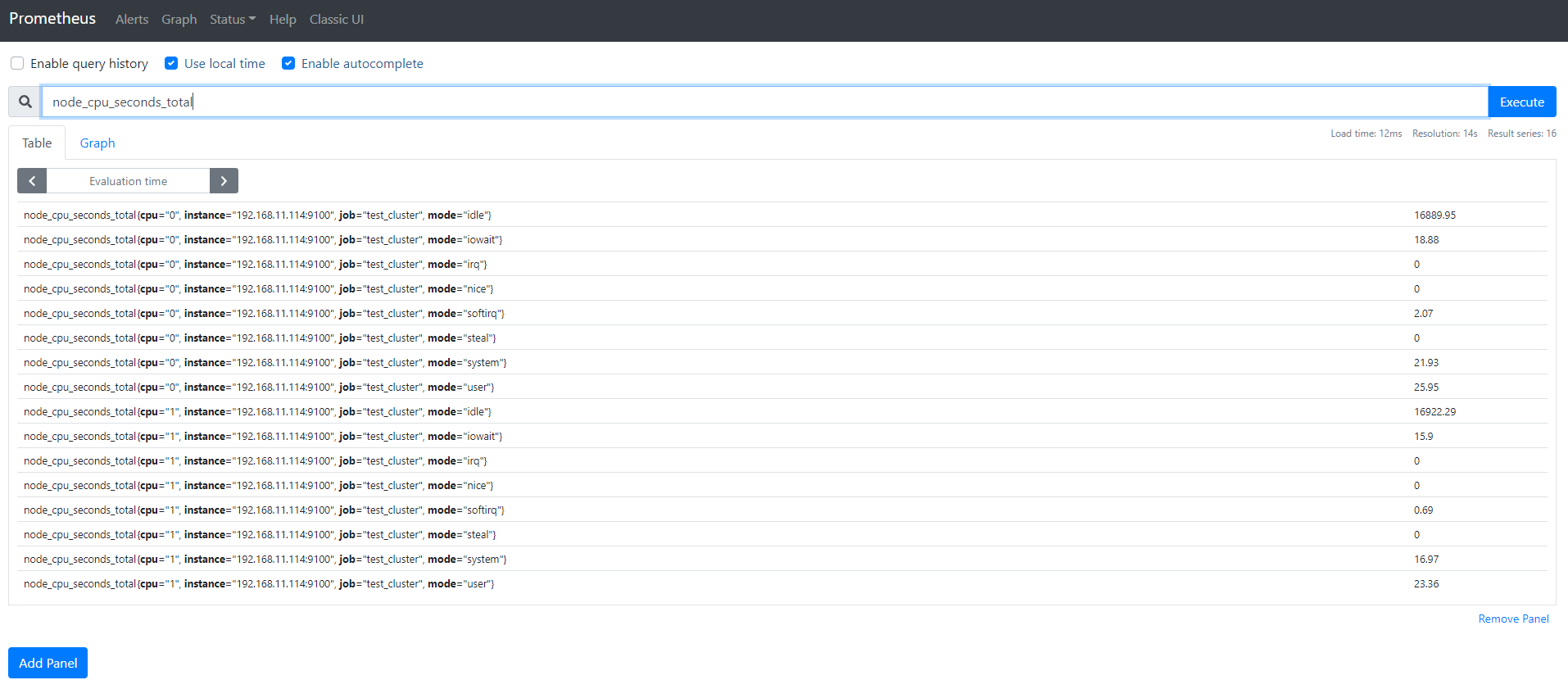
CPU使用率:
# irate 平均
100-irate(node_cpu_seconds_total{name="docker",mode="idle"}[5m])*100
内存使用率:
100-(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)/node_memory_MemTotal_bytes*100
/分区磁盘使用率:
100-(node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"}/node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"}*100)
# 能查看到数据,证明11.114的数据是采集成功了的,也可用旁边的Graph用图形来展示,当然promtheus的图形展示能里比较弱,建议使用grafna配合使用,监控主机基础信息,可以使用Grafna的模板ID为:9276模板
# 安装alertmanager,实现邮件报警
1. 安装alertmanager,修改alertmanager配置文件,启动。
2. 在prometheus配置文件中,配置alertmanager和prometheus通信。
3. 在prometheus配置文件中创建告警规则。
1. 在192.168.11.153机器上部署alertmanager
[root@jenkins soft]# wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz [root@jenkins soft]# tar -xf alertmanager-0.21.0.linux-amd64.tar.gz [root@jenkins soft]# mv alertmanager-0.21.0.linux-amd64 /usr/local/alertmanager/

# alertmanager 程序打包好的启动文件
# alertmanager.yml 配置文件
# amtool 检查工具
# 加入systemd管理
[root@jenkins alertmanager]# cat /usr/lib/systemd/system/alertmanager.service [Unit] Description=alertmanager.service [Service] ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml Restart=on-failure [Install] WantedBy=multi-user.target
启动
[root@jenkins ~]# systemctl start alertmanager.service
[root@jenkins ~]# ss -antulp | grep aler
udp UNCONN 0 0 :::9094 :::* users:(("alertmanager",pid=2282,fd=7))
tcp LISTEN 0 128 :::9093 :::* users:(("alertmanager",pid=2282,fd=8))
tcp LISTEN 0 128 :::9094 :::* users:(("alertmanager",pid=2282,fd=3))
2. 在prometheus配置文件中,配置alertmanager和prometheus通信。
[root@jenkins ~]# cd /usr/local/prometheus/
[root@jenkins prometheus]# vim prometheus.yml
# Alertmanager configuration
alerting: # alertmanager配置文件
alertmanagers:
- static_configs:
- targets: # 地址
- 127.0.0.1:9093
3. 在prometheus配置文件中创建告警规则。
[root@jenkins ~]# cd /usr/local/prometheus/
[root@jenkins prometheus]# vim prometheus.yml
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: # 创建告警规则存放文件
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
[root@jenkins prometheus]# mkdir rules/
[root@jenkins prometheus]# cd rules/
[root@jenkins rules]# cat systemd.yml
groups:
- name: docker
rules:
- alert: docker_systemd_down # 告警聚合的名称依据
expr: node_systemd_unit_state{name="docker.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难 # 告警级别
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"
- alert: sshd_systemd_down
expr: node_systemd_unit_state{name="sshd.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"
- alert: nginx_systemd_down
expr: node_systemd_unit_state{name="nginx.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"
配置altermanager配置文件
global: # 全局的配置
resolve_timeout: 5m # 解析的超时时间
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '959877177@qq.com'
smtp_auth_username: '9594567177@qq.com'
smtp_auth_password: 'fye123123sa4ghai'
smtp_require_tls: false
route: # 将告警具体怎么发送
group_by: ['alertname'] # 根据标签进行分组
group_wait: 10s # 发送告警等待时间
group_interval: 10s # 发送告警邮件的间隔时间
repeat_interval: 1h # 重复的告警发送时间
receiver: 'email' # 接收者是谁
receivers: # 将告警发送给谁
- name: 'email'
email_configs:
- to: 'aaa@bbb.com'
inhibit_rules: # 抑制告警
- source_match:
severity: 'critical' # 当收到同一台机器发送的critical时候,屏蔽掉warning类型的告警
target_match:
severity: 'warning'
equal: ['alertname', 'severity', 'instance'] # 根据这些标签来定义抑制
例如

检查altermanager和Prometheus的配置文件,看看是否有报错,是否有发现规则
[root@jenkins alertmanager]# ./amtool check-config alertmanager.yml Checking 'alertmanager.yml' SUCCESS Found: - global config - route - 1 inhibit rules - 1 receivers - 0 templates [root@jenkins prometheus]# ./promtool check config prometheus.yml Checking prometheus.yml SUCCESS: 2 rule files found Checking rules/rules.yml SUCCESS: 1 rules found Checking rules/systemd.yml SUCCESS: 3 rules found
# 没有报错,并且发现了报警规则,可以重启prometheus和altermanager服务
[root@jenkins prometheus]# systemctl restart prometheus.service alertmanager.service
# 登陆prometheus的web页面,查看是否有规则等
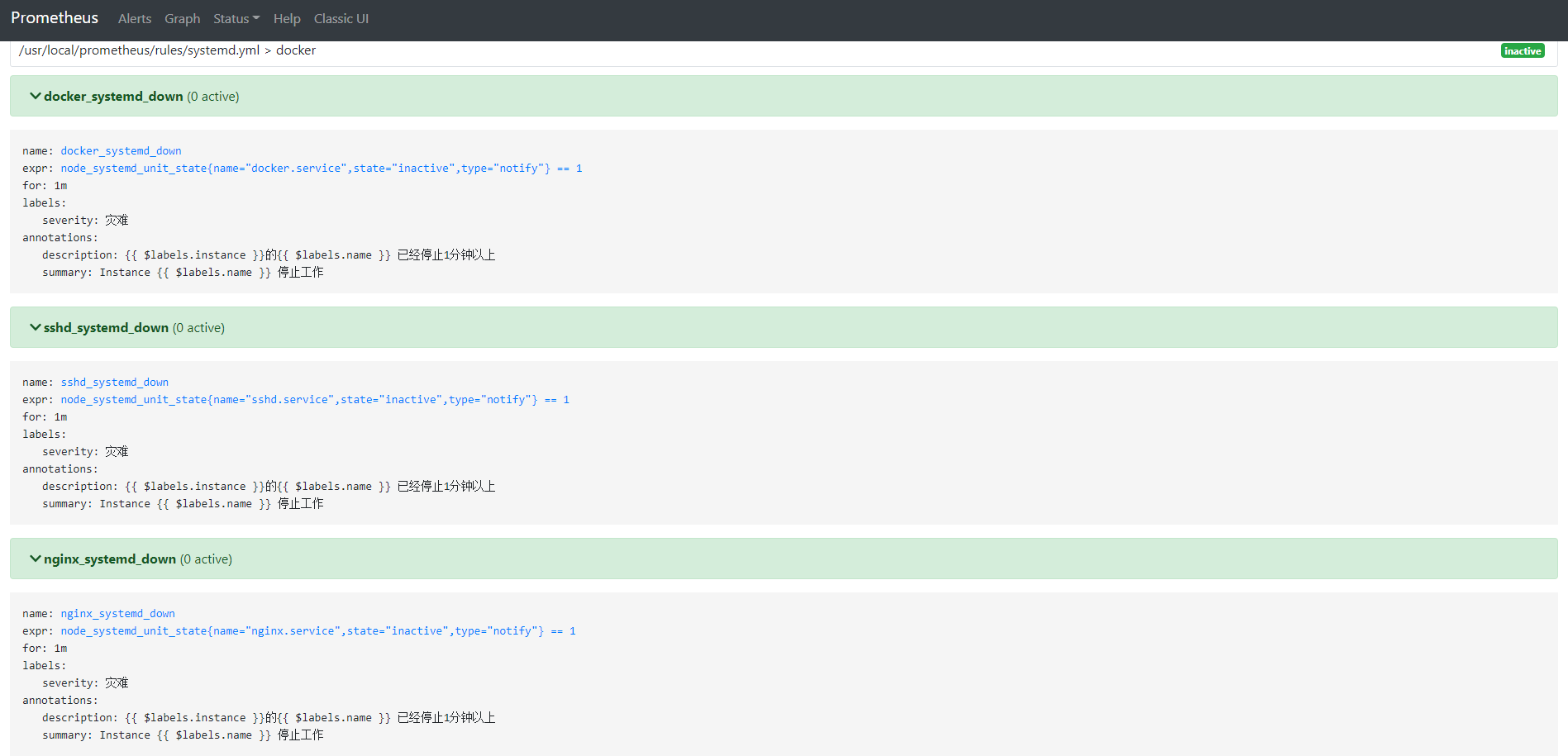
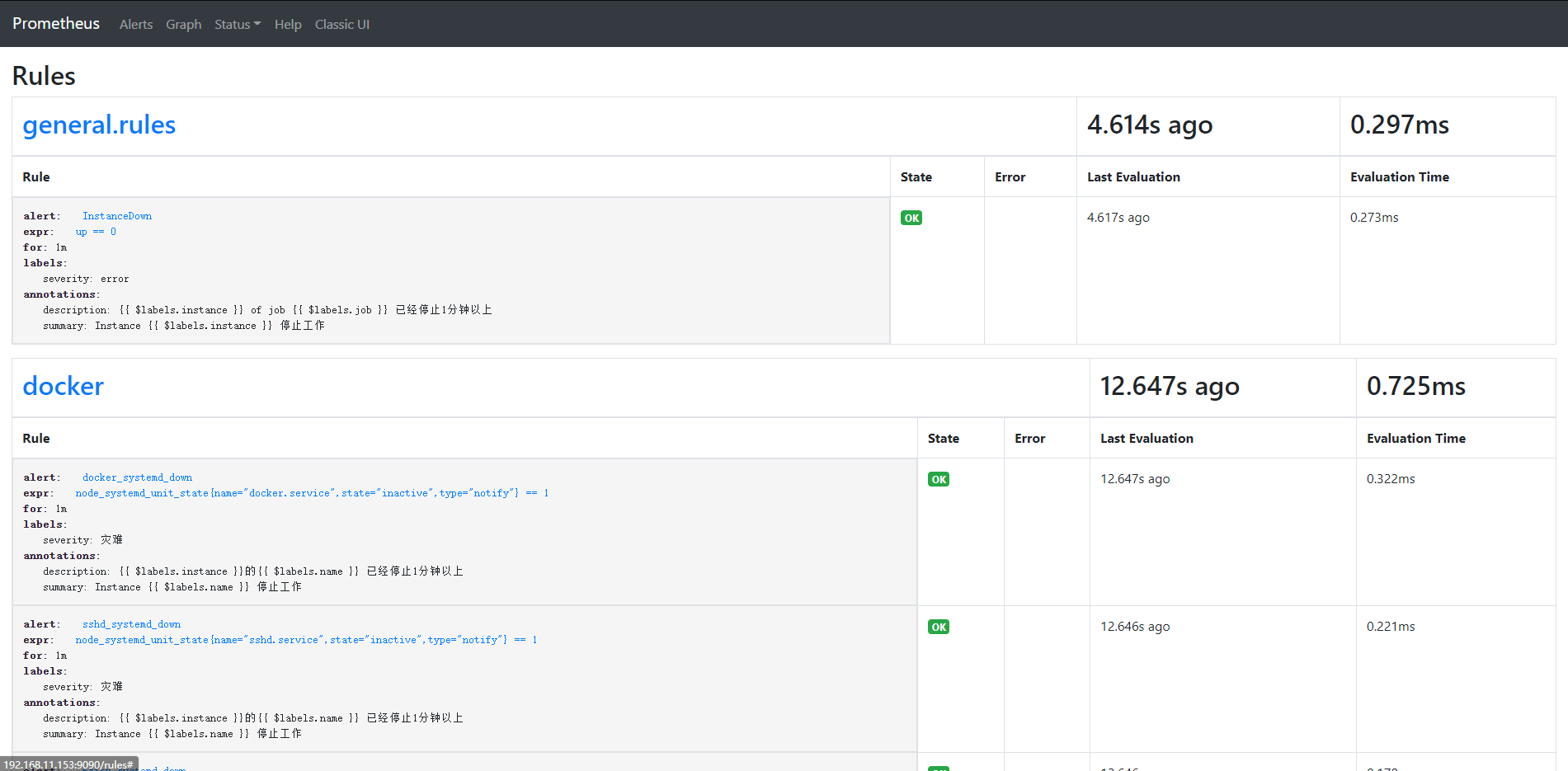
# 之后可以测试邮件报警,停掉docker服务
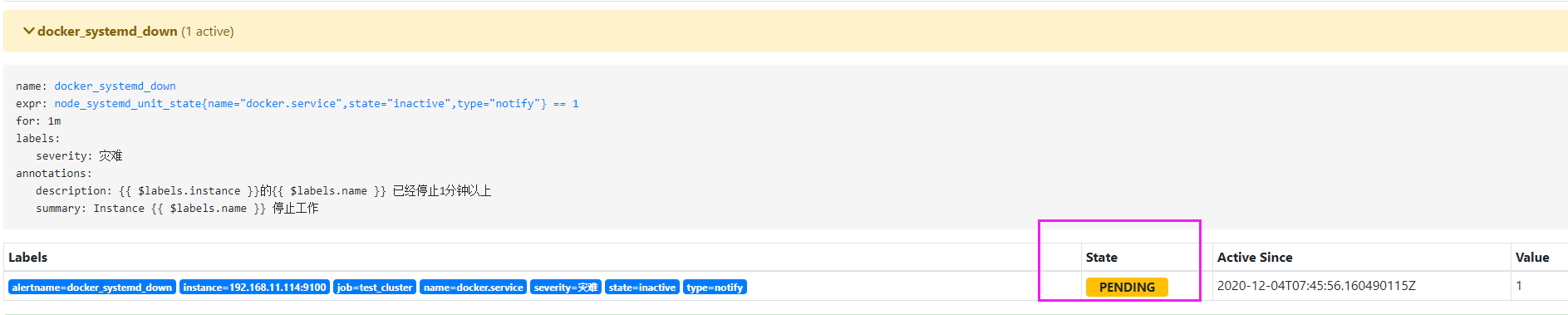
# 停止docker服务后,不会立即发送报警邮件,可以看到当前的状态已经是PENDING,这个时候altermanager已经收到prometheus的报告,说docker服务已经挂掉了,等待状态变为FIRING的时候,才会发送邮件

# altermanager报警会经过几个阶段:
# 收到告警信息的时候,会根据我们配置文件中配置的等待时间,在等待时间内如果恢复了,将不发送告警邮件;在等待时间内如果有相同类似的告警,将组合到一封邮件中发送
# altermanager告警有几个过程,从收到告警后,会内部进行分组,抑制,或者静默的处理,等待时间过了,告警没有恢复,才会下发邮件。
# 收到报警邮件
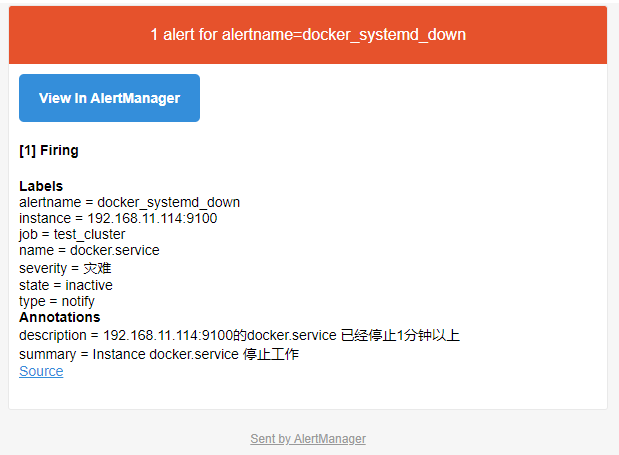
告警收敛(分组、抑制、静默)
分组:group,将类似性质的警报分类为单个通知
抑制:inhibition,当警报发出后,停止重复发送由此警报引发的其它报警
静默:silence,是一种简单的特定的时间静音提醒机制
# 静默可以在altermanager的文本页面去配置,当维护某个服务的时候,知道要报警,会收到邮件,而又不想收邮件的时候,可以配置静默
http://192.168.11.153:9093 # 访问alertmanager的地址
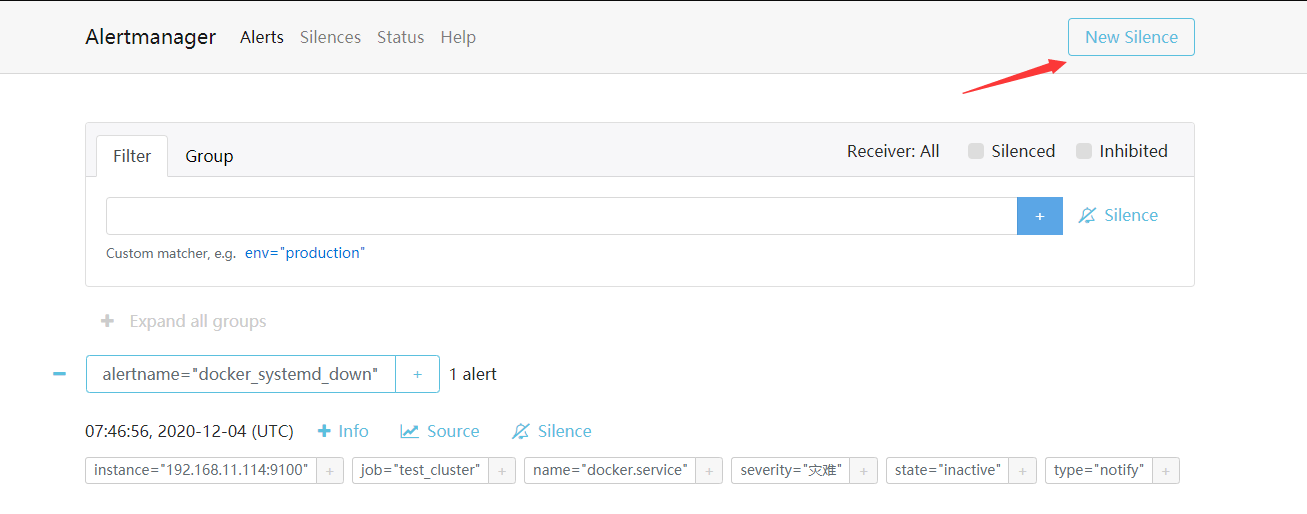
# New Silence创建静默
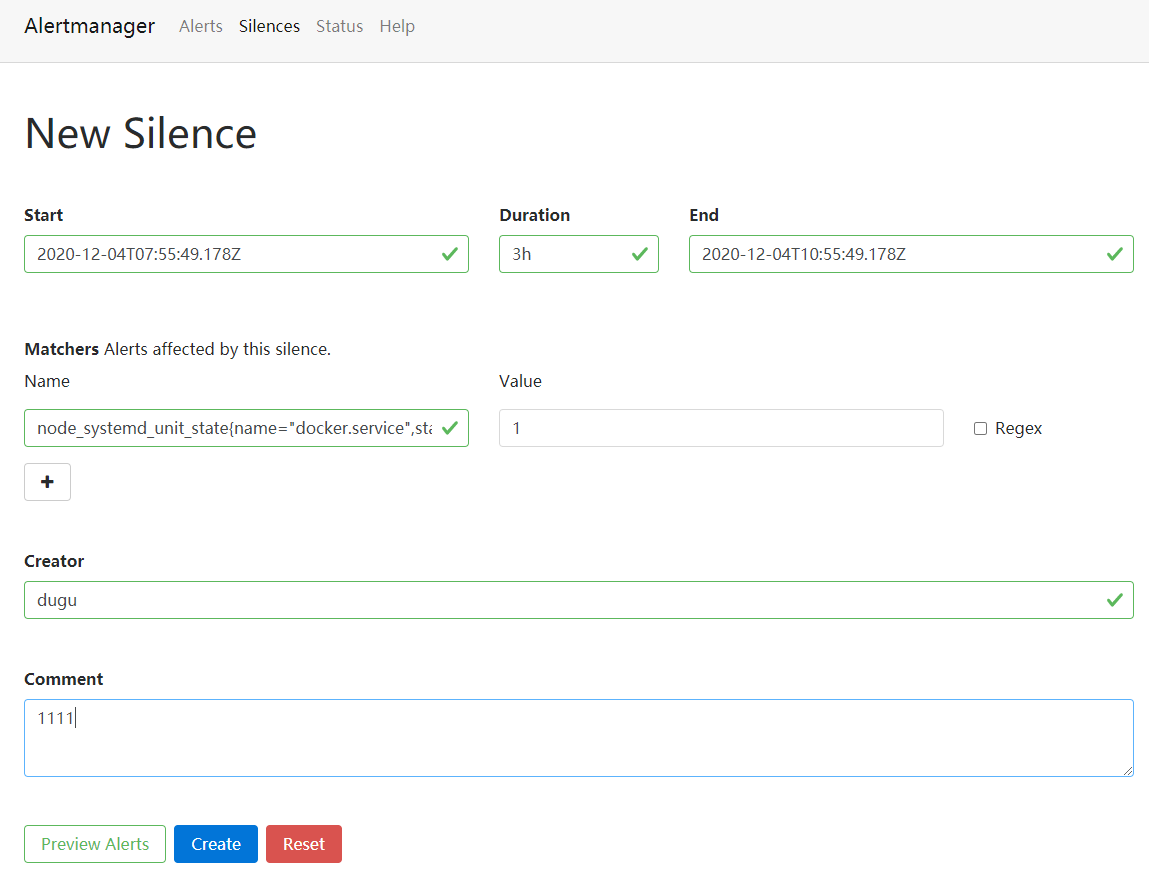
# 这样静默后,比如docker服务停止了,就不会发送邮件
记录一些常见的告警监控
[root@lmd_monitor_promethues_8_241 rules]# cat host_basic_monitoring.yml
groups:
- name: 服务器基本监控
rules:
# 告警聚合的名称
- alert: 与监控主机失去连接5分钟
expr: up == 0
for: 5m
labels:
# 告警级别
severity: 灾难
annotations:
summary: "{{ $labels.instance }} 不可达!"
description: "{{ $labels.instance }} 与监控主机失去连接超过5分钟。"
- name: 服务器 / 分区磁盘占用率监控
rules:
- alert: / 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 / 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 / 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data 分区磁盘占用率监控
rules:
- alert: /data 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data"} / node_filesystem_size_bytes{mountpoint="/data"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
#- name: 服务器 CPU 使用率监控
# rules:
# - alert: CPU 使用率大于95%
# expr: 100 * (1 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])))) > 95
# for: 5m
# labels:
# severity: warning
# annotations:
# summary: "{{ $labels.instance }} 的 5分钟 CPU 使用率大于 95% "
# description: "{{ $labels.instance }} 的 5分钟 CPU 使用率大于 95%,请运维人员注意!"
#
#- name: 服务器 内存 使用率监控
# rules:
# - alert: 内存 使用率大于95%
# expr: ((node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes) * 100 > 95
# for: 5m
# labels:
# severity: warning
# annotations:
# summary: "{{ $labels.instance }} 的 内存 使用率大于 95% "
# description: "{{ $labels.instance }} 的 内存 使用率大于 95%,请运维人员注意!"
- name: 服务器 /home 分区磁盘占用率监控
rules:
- alert: /home 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/home"} / node_filesystem_size_bytes{mountpoint="/home"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /home 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /home 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data1 分区磁盘占用率监控
rules:
- alert: /data1 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data1"} / node_filesystem_size_bytes{mountpoint="/data1"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data1 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data1 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data2 分区磁盘占用率监控
rules:
- alert: /data2 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data2"} / node_filesystem_size_bytes{mountpoint="/data2"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data2 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data2 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data3 分区磁盘占用率监控
rules:
- alert: /data3 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data3"} / node_filesystem_size_bytes{mountpoint="/data3"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data3 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data3 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /svn 分区磁盘占用率监控
rules:
- alert: /svn 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/svn"} / node_filesystem_size_bytes{mountpoint="/svn"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data3 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data3 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data1_hdd 分区磁盘占用率监控
rules:
- alert: /data1_hdd 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data1_hdd"} / node_filesystem_size_bytes{mountpoint="/data1_hdd"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data1_hdd 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data1_hdd 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /data1_ssd 分区磁盘占用率监控
rules:
- alert: /data1_ssd 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data1_ssd"} / node_filesystem_size_bytes{mountpoint="/data1_ssd"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /data1_ssd 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /data1_ssd 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 /bak_data 分区磁盘占用率监控
rules:
- alert: /bak_data 分区磁盘占用率大于95%
expr: 100 * (1 - (node_filesystem_avail_bytes{mountpoint="/bak_data"} / node_filesystem_size_bytes{mountpoint="/bak_data"})) > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "{{ $labels.instance }} 的 /bak_data 分区磁盘占用率大于 95%"
description: "{{ $labels.instance }} 的 /bak_data 分区磁盘占用率 95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 C 盘磁盘空间占用率监控
rules:
- alert: 服务器 C 盘磁盘空间占用率大于95%
expr: ((windows_logical_disk_size_bytes{volume="C:"} - windows_logical_disk_free_bytes{volume="C:"}) / windows_logical_disk_size_bytes{volume="C:"}) * 100 > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "C 盘磁盘使用率过高"
description: "{{ $labels.instance }} 的 C 盘磁盘使用率已经超过了95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 D 盘磁盘空间占用率监控
rules:
- alert: 服务器 D 盘磁盘空间占用率大于95%
expr: ((windows_logical_disk_size_bytes{volume="D:"} - windows_logical_disk_free_bytes{volume="D:"}) / windows_logical_disk_size_bytes{volume="D:"}) * 100 > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "D 盘磁盘使用率过高"
description: "{{ $labels.instance }} 的 D 盘磁盘使用率已经超过了95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 E 盘磁盘空间占用率监控
rules:
- alert: 服务器 E 盘磁盘空间占用率大于95%
expr: ((windows_logical_disk_size_bytes{volume="E:"} - windows_logical_disk_free_bytes{volume="E:"}) / windows_logical_disk_size_bytes{volume="E:"}) * 100 > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "E 盘磁盘使用率过高"
description: "{{ $labels.instance }} 的 E 盘磁盘使用率已经超过了95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
- name: 服务器 F 盘磁盘空间占用率监控
rules:
- alert: 服务器 F 盘磁盘空间占用率大于95%
expr: ((windows_logical_disk_size_bytes{volume="F:"} - windows_logical_disk_free_bytes{volume="F:"}) / windows_logical_disk_size_bytes{volume="F:"}) * 100 > 95
for: 5m
labels:
severity: 警告
annotations:
summary: "F 盘磁盘使用率过高"
description: "{{ $labels.instance }} 的 F 盘磁盘使用率已经超过了95%,请运维人员通知项目组服务器管理员清理磁盘空间。"
采用supervisord管理服务,supervisord ini文件
[root@lmd_monitor_promethues_8_241 prometheus]# cat prometheus.ini [program:prometheus] command=/data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --log.level=debug --log.format=json directory=/data/prometheus autorestart=true redirect_stderr=true stdout_logfile=/home/prometheus/prometheus.log stdout_logfile_maxbytes=300MB stdout_logfile_backups=50 [root@lmd_monitor_promethues_8_241 alertmanager]# cat alertmanager.ini [program:alertmanager] command=/data/alertmanager/alertmanager --config.file=/data/alertmanager/alertmanager.yml directory=/data/alertmanager autorestart=true redirect_stderr=true stdout_logfile=/home/alertmanager/alertmanager.log stdout_logfile_maxbytes=300MB stdout_logfile_backups=50 [root@lmd_monitor_promethues_8_241 grafana]# cat grafana.ini # 日志存放在/data/grafana/data/log [program:grafana] command=/data/grafana/bin/grafana-server directory=/data/grafana autorestart=true
暂时记录这么多…………

