爬虫之requests模块
一、爬虫介绍
1、作用
使用程序 模拟发送http请求---》得到http响应---》把响应的数据解析出来---》存储起来
2、做爬虫需要掌握的技术
web端爬虫(网页)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | -抓包: -抓包工具---》浏览器,charles,fiddler。。。 -发送http请求的模块 -requests:同步的---》不仅仅做爬虫用 调用第三方api就可以使用 -request-html: -aiohttp:异步的http模块 -解析库:http响应---》可能是xml,html,json,文件,图片。。。---》响应中解析出想要的数据 -beautifulsoup4---》xml/html -lxml--->xml/html -selenium--->请求加解析(本质是模拟浏览器) -json-存储:mysql,redis,es,mongodb。。。。 -pymysql:aiomysql -redis:aioredis -elasticsearch.py -py-mongo |
移动端爬虫(app)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | -抓包,发请求,解析,存储跟web一样的 -对app进行反编译---》jadx -安卓:java写的app---》把app反编译成java---》懂java---》看懂逻辑---》使用python模拟这个过程 -hook技术---》frida -c语言写加密---》用java调用c语言的加密方式---》xx.so-->动态链接库文件 -反编译 so文件---》IDA---》反编译成汇编和c -动态调试 -python模拟这个过程即可 -反扒 -请求头反扒:user-agent,referfer:上一个访问的地址是什么 -反扒:无限调试 -封ip---》ip代理池 -封账号---》cookie池 -js加密---》js逆向 |
3、动态链接库
1 2 3 4 5 6 7 | # 百度,谷歌 搜索引擎本质其实就是个大爬虫---》不停的在互联网上爬取页面---》存到自己的库中使用搜索的时候---》去百度的数据库中查询相关的关键字----》显示在页面上---》当我们点击某一个---》真正的跳转到 真正的搜索到的页面百度做爬取时---》对动态页面的爬取权重要低seo优化---》保证我们公司的网站通过关键字搜索,显示在第一个 -伪静态---》sem:付费买关键词 |
二、requests模块
1、requests封装
使用requests可以模拟浏览器的请求,比起之前用到的urllib(内置模块),requests模块的api更加便捷(本质就是封装了urllib3)
注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
-混合项目---》拿回来的页面---带数据
-分离项目---》拿回来的页面--》数据是空的--》再分析接口---》再发请求才能拿到真正的数据
-看到一个页面有数据---》用requests发送请求---》拿回来的,可能跟看到的不一样
2、快速使用
1 2 3 4 5 | 安装:pip install requestsimport requestsres=requests.get('https://www.cnblogs.com/') # res中会有:http响应 响应头的,响应体的print(res.text) # 响应体的文本字符串(可能会乱码) |
三、携带请求参数
1、 get请求携带请求参数
1 2 3 4 5 6 | # 方式一:直接拼在后面res=requests.get('https://www.cnblogs.com/?ordering=-id&search=课程')# 方式二:使用params参数res=requests.get('https://www.cnblogs.com/',params={'ordering':'-id','search':'课程'})print(res.text) |
四、url 编码和解码
1、parse 解码与编码
1 2 3 4 5 6 7 8 | from urllib import parse# url解码# res = parse.unquote('%E7%BE%8E%E5%A5%B3')# url编码res=parse.quote('刷币') # %E5%88%B7%E5%B8%81print(res) |
五、携带请求头
1、请求头中可能有的:User-Agent,referer,cookie,Host
1 2 3 4 5 6 | header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}res = requests.get('https://www.sogou.com/web?query=%E7%BE%8E%E5%A5%B3', headers=header)# res=requests.request('get','url',headers=header)print(res.text) |
六、发送post请求
1、请求体中:两种方式:
data={}--->编码格式urlencoded---》key=value&key=value
json={}---》编码格式是json
res=requests.post('url')
花花手机的登录为例(验证码并没有真正的用上)
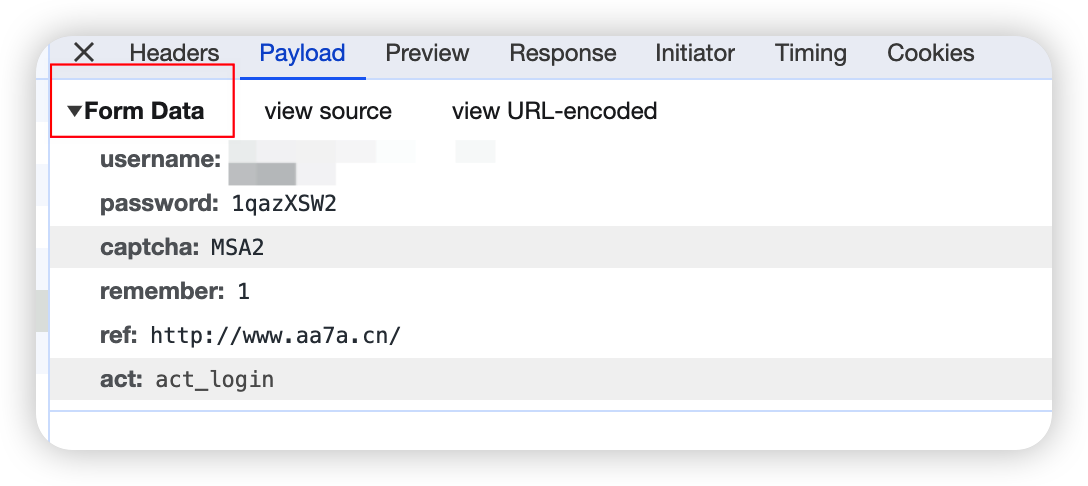
1 2 3 4 5 6 7 8 9 | data = { 'username': 'jing@outlook.com', 'password': '1qazXSW2', 'captcha': 'xxxx', 'ref': 'http://www.aa7a.cn/', 'act': 'act_login',}res = requests.post('http://www.aa7a.cn/user.php', data=data)print(res.text) |
七、携带cookie
1、cookie的补充
后端签发token,前端保存token到cookie
后端:
序列化类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class LoginSerializers(serializers.Serializer): def validate(self, attrs): user = self._get_user(attrs) token = self._get_token(user) print(user) self.context['username'] = user.username self.context['token'] = token return attrs def _get_user(self, attrs): pass def _get_token(self, user): payload = jwt_payload_handler(user) token = jwt_encode_handler(payload) return token |
视图函数:
1 2 3 4 5 6 7 | def _login(self, request, *args, **kwargs): ser = self.get_serializer(data=request.data) ser.is_valid(raise_exception=True) username = ser.context.get('username') token = ser.context.get('token') icon = ser.context.get('icon') return APIResponse(username=username, token=token, iocn=icon) |
前端:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | this.$axios({ url: this.$settings.BASE_URL + 'user/login/mul_login/', method: 'post', data: { username: this.username, password: this.password, } }).then(response => { console.log(response) if (response.data.code === 100) { let username = response.data.username; let token = response.data.token; this.$cookies.set('username', username, '7d'); this.$cookies.set('token', token, '7d'); this.$emit('success', response.data); this.$message({ message: '登录成功', type: 'success', duration: 1000, }); this.$router.push('/index') |
2、登录的时候请求头中带有cookie
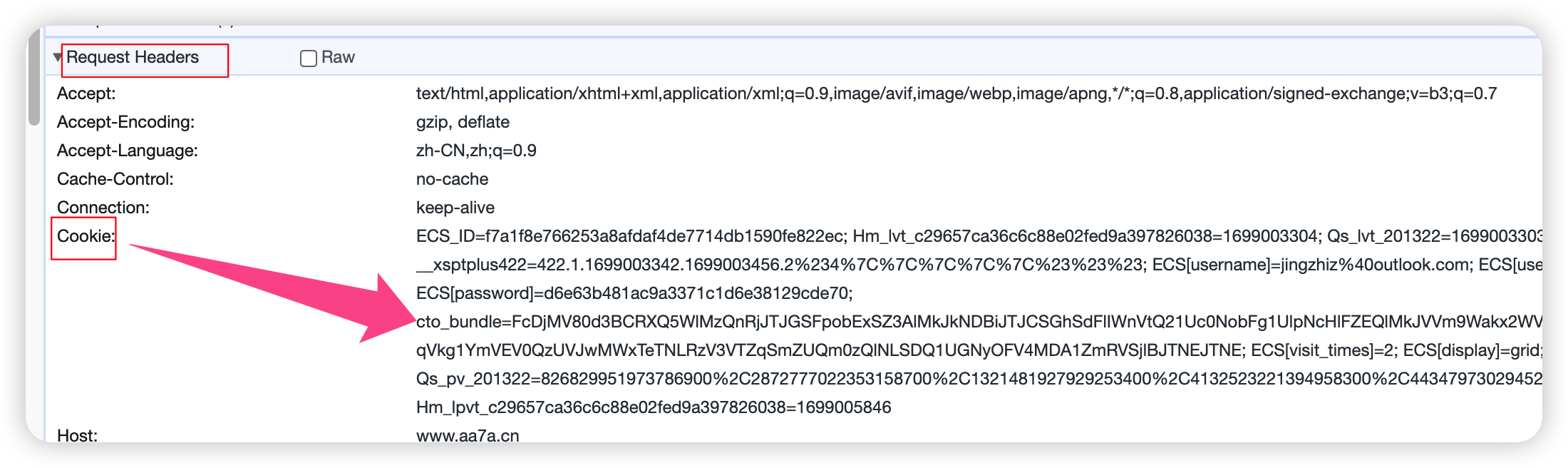
1 2 3 4 5 6 7 | import requestsheader = { 'Cookie': 'ECS_ID=f7a1f8e766253a8afdaf4de7714db1590fe822ec; Hm_lvt_c29657ca36c6c88e02fed9a397826038=1699003304; Qs_lvt_201322=1699003303; __xsptplus422=422.1.1699003342.1699003456.2%234%7C%7C%7C%7C%7C%23%23%23; ECS[username]=jingzhiz%40outlook.com; ECS[user_id]=67693; ECS[password]=d6e63b481ac9a3371c1d6e38129cde70; cto_bundle=FcDjMV80d3BCRXQ5WlMzQnRjJTJGSFpobExSZ3AlMkJkNDBiJTJCSGhSdFlIWnVtQ21Uc0NobFg1UlpNcHlFZEQlMkJVVm9Wakx2WVBQZG9GZ1pPYTBoZVVrWUhPVWxqZ05YYVNnb1JBMiUyQlE0SkFqVkg1YmVEV0QzUVJwMWxTeTNLRzV3VTZqSmZUQm0zQlNLSDQ1UGNyOFV4MDA1ZmRVSjlBJTNEJTNE; ECS[visit_times]=2; ECS[display]=grid; Qs_pv_201322=826829951973786900%2C2872777022353158700%2C1321481927929253400%2C4132523221394958300%2C4434797302945210000; Hm_lpvt_c29657ca36c6c88e02fed9a397826038=1699005846'}res = requests.get('http://www.aa7a.cn/', headers=header)print('jxxz@outlook.com' in res.text) # 没有携带cookie 访问 |
没有cookie时,模拟的是没登录,打印邮箱为False。
3、模拟自动点赞
携带cookie 方式一:放到headers中
https://dig.chouti.com/ 一个新闻小网站
1 2 3 4 5 6 7 8 9 10 11 12 | import requestsdata = { 'linkId': 40496403 # 携带数据}header = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36', 'Cookie': 'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiI5ZjdhMzg4My1lNzE3LTRjZWItYTFlOS00M2RlZjViNzcxZTQiLCJleHBpcmUiOiIxNzAxNTk2ODg5NTkwIn0.hObzQIi48gGyQquOSJ0khw86KOZh1m5Fp-EZT43o2LU; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1699004891; __snaker__id=M7mhrtczSgObqvHu; gdxidpyhxdE=fN%2FaXpZBkwOHh5o%2Bpt5RN7hdShpijvAsDHmyQY6PacPHun2i50Htl3z17tbmRxRg1HM2UybdYQ%2Br5ectzMdH4JHNrYmTh3c0eZ8dDZy3S7XLuNg1W6skfuVoEpBRv7vvyBnRz%2F03Wq87Av4e3shXbxrYlLucCjzIuXo4mkugwdoCPiSk%3A1699005793876; YD00000980905869%3AWM_NI=iG0Xe6VFKNVNcScLWP5IqGCv1Bdy9m8tdF7QfPRZsBWfXeLO%2B11YN4aK7d5hpXZYNc7pmGXHxzGFK4oy%2FR8pdensbNfyY%2BEsxVIuCTWdy5h1VHJSQZFiUhCMAN8iREcjY1g%3D; YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee92c46efc8b9f8bcb50a9e78aa6c15a838f8eb0d439fc92008cf952ab9a83acd12af0fea7c3b92aab9900b9e83e969a85afd546a18dadadd65cf797bfa8c27ef39eac9abc67fcacaca7b65ba6909ebbf24a95ba9886cf45e9efffbacd40a395f985b864b48896bacd69f5b0a3a8db44bca689a7ca40ada7e1b3bb7ca8bba294e146a6a797ccc879bc8a8796c26095bcb7d6eb3b969886b4d45286b79b89c2478392f88ad14fa1b697d2e637e2a3; YD00000980905869%3AWM_TID=Gm68Ql837AVFUFABEAfBjpdlxzNnBJeQ; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjdHVfNjk5MDA0OTU3NjgiLCJleHBpcmUiOiIxNzAxNTk2OTU3ODM5In0.ZotjKwHkfg7aUL2epOIYBpv3jIxm2kuKWKNyKsz9RoI; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1699010536'}res = requests.post('https://dig.chouti.com/link/vote', data=data, headers=header)print(res.text) |
4、携带cookie 方式二
1 2 3 4 5 6 7 8 9 | def cookie_str_to_cookie_dict(s): return {item.split('=')[0]: item.split('=')[1] for item in s.split(';')}from utils import cookie_str_to_cookie_dictimport requestss = 'ECS_ID=f7a1f8e766253a8afdaf4de7714db1590fe822ec; Hm_lvt_c29657ca36c6c88e02fed9a397826038=1699003304; Qs_lvt_201322=1699003303; __xsptplus422=422.1.1699003342.1699003456.2%234%7C%7C%7C%7C%7C%23%23%23; ECS[username]=jingzhiz%40outlook.com; ECS[user_id]=67693; ECS[password]=d6e63b481ac9a3371c1d6e38129cde70; ECS[display]=grid; cto_bundle=apdAYl80d3BCRXQ5WlMzQnRjJTJGSFpobExSZ2dmY1BvaVpTMnJiYXJlUTgzJTJGdjVTVGdQSGdvN1lpZXBuaGF5ZWc5OTlXSkFIdFZuQ0k4Y25xSHpoVWoxaDhTdWdGWWRHUGN6czZCMXRWOXB3Sk9OVkxXTTFYMU9KQUxiMnNPNCUyRkklMkJrNURpN1N3dGJNWXdYcSUyRm1jc01ZTENnd3EzSXg3cE05MVZFMkswbUtSJTJGWkRLdGRsZE9PN1RmYW51UUI2M09lYUttOVU; ECS[visit_times]=3; Qs_pv_201322=1321481927929253400%2C4132523221394958300%2C4434797302945210000%2C4303319800648504000%2C3623981280408506400; Hm_lpvt_c29657ca36c6c88e02fed9a397826038=1699011224'res = requests.get('http://www.aa7a.cn/', cookies=cookie_str_to_cookie_dict(s))print('jingzhiz@outlook.com' in res.text) # 携带cookie 访问, 结果为True |
5、携带cookie 方式三
cookies参数携带RequestsCookieJar
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | data = { 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': 'xxxx', 'ref': 'http://www.aa7a.cn/', 'act': 'act_login',}res = requests.post('http://www.aa7a.cn/user.php', data=data)print(res.text)print(type(res.cookies.get_dict())) # 登录成功的cookie,RequestsCookieJar 本质就是字典from requests.cookies import RequestsCookieJar# 拿到登录后的cookie,再向首页发送请求res = requests.get('http://www.aa7a.cn/', cookies=res.cookies)print('616564099@qq.com' in res.text) # 没有携带cookie 访问 |
6、session 的使用---》原来每次都需要手动携带cookie
1 2 3 4 5 6 7 8 9 10 11 12 | from requests import Sessionsession=Session()data = { 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': 'xxxx', 'ref': 'http://www.aa7a.cn/', 'act': 'act_login',}res = session.post('http://www.aa7a.cn/user.php', data=data)res = session.get('http://www.aa7a.cn/') # 可以自动处理cookie,不需要手动携带print('616564099@qq.com' in res.text) |
八、响应对象
1、响应对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import requestsrespone = requests.get('http://www.aa7a.cn/')# print(type(respone))# 类的属性跟方法# from requests.models import Response# print(respone.text) # 响应体转成了字符串# print(respone.content) # 响应体的二进制# print(respone.status_code) # 响应状态码# print(respone.headers) # 响应头print(respone.cookies) # 响应cookieprint(respone.cookies.get_dict())# print(respone.cookies.items()) # 响应cookie---》转成key-value形式## print(respone.url) # 请求地址# print(respone.history) # 了解:访问过的地址 针对于 重定向的情况,才会有值## print(respone.encoding) # 响应编码 |
2、下载一个视频
1 2 3 4 5 6 7 8 | respone = requests.get('https://img3.chouti.com/CHOUTI_231102_8B10E74FBE2646748DE951D4EAB1F1E7.jpg')# print(respone.content)# 保存到本地--》就是这张图片with open('致命诱惑.jpg', 'wb') as f: # f.write(respone.content) # for line in respone.iter_content(1024): for line in respone.iter_content(): f.write(line) |
九、高级用法
1、上传文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | ## 10 高级用法:# 1 关于https报错问题'''以后访问https地址时,可以会报错,访问https需要携带证书---》没带就会报错不携带证书---》不报错respone=requests.get('https://www.12306.cn',verify=False) #不验证证书,报警告,返回200'''import urllib3import requestsurllib3.disable_warnings()respone = requests.get('https://www.12306.cn', verify=False)print(respone.text)# 2 超时设置# import requests# respone=requests.get('https://www.baidu.com',timeout=0.0001)# 3 认证设置 ---》不需要知道了,现在没有这种了---》不是前端认证# 4 异常处理# 5 上传文件# import requests#files = {'file': open('a.jpg', 'rb')}respone = requests.post('http://httpbin.org/post', files=files)print(respone.status_code)# 后端存储 request.FILES.get('file') |



