python 常用的内置函数
1、sorted() 排序
sorted(iterable, key=None, reverse=False)
其中,参数的含义如下:
iterable:表示要排序的可迭代对象,如列表、元组、字符串等。key:可选参数,用于指定排序的依据。它是一个函数或 lambda 表达式,根据指定的键从可迭代对象中的元素中提取值来进行排序。默认为None,表示按照元素的原始值进行排序。reverse:可选参数,用于指定排序的顺序。如果设置为True,则降序排序;如果设置为False(默认值),则升序排序。
sorted() 函数返回一个新的已排序的列表,并不会改变原始的可迭代对象。
l = sorted([1, 2, 3, 6, 34, 20, 18]) print(l)
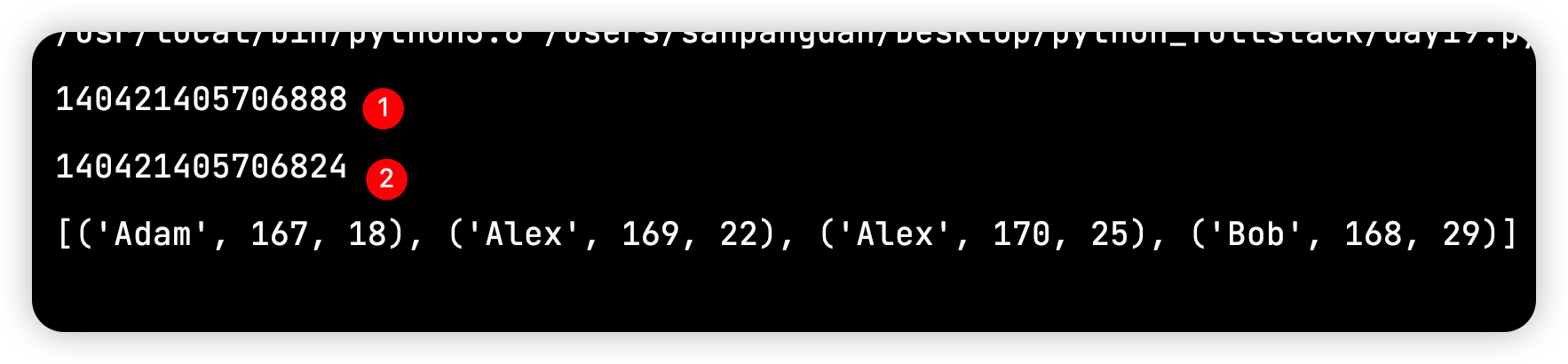
案例1:搭配匿名函数案例
l = [('Alex', 170, 25), ('Alex', 169, 22), ('Bob', 168, 29), ('Adam', 167, 18)]
print(id(l))
def sort_by_age(lst: list):
sorted_lst = sorted(lst, key=lambda x: x[2])
print(id(sorted_lst))
return sorted_lst
print(sort_by_age(l))
案例2:iterable:可迭代对象为字典时
dic = {'a': 24, 'g': 52, 'i': 12, 'k': 33}
res = sorted(dic.items(), key=lambda x: x[1])
# print(dic.items())
# [('a', 24), ('g', 52), ('i', 12), ('k', 33)]
print(res)
注:lambda匿名函数,x为形参,后面为return返回值元组。实参为前面的可迭代对象的元素items(k:v键值对)。函数带入参数后返回v值赋值给key。key是作为排序的依据。
另一种解法:
思路:先取出v值,做好排序;再用循环中字典k取v与列表中的v做相等判断;
如果相等,空字典中,新增k:v,此时的顺序是由list中的v决定的。
d = {'a': 11, 'b': 7, 'c': 9, 'd': 2}
v = list(d.values())
v.sort()
# [1, 2, 7, 9]
# 返回排序结果
result = {}
for i in range(len(v)):
for k in d:
if d[k] == v[i]:
result[k] = v[i] # 关键点:利用排好序的v值,进行新字典k值添加的先后顺序依据
print(result)
结果:
{'a': 1, 'd': 2, 'b': 7, 'c': 9}
变相题
list1 = [{'name': 'a', 'age': 20}, {'name': 'b', 'age': 30}, {'name': 'c', 'age': 25}, {'name': 'd', 'age': 29}]
list2 = []
while True:
x = list1[0]
for i in list1:
if x['age'] > i['age']:
x = i # 先挑一个字典出来,循环取值对比,如果x的age值大就赋值为小的
list2.append(x) # for循环完成后,找到age最小值,赋值该字典给x列表
for i, j in enumerate(list1): # 循环做删除操作
if x == j:
list1.pop(i)
if len(list1) == 0:
break
print(list2)
思路:
先挑出一个小字典出来,然后取值做比较,找出age值最小的字典,添加到新的列表中,原来的列表做删除操作,直到原列表元素删空。

2、help()
会经常使用python自带函数或模块,一些不常用的函数或是模块的用途不是很清楚,这时候就需要用到help函数来查看帮助。
3、dir()
dir()函数的参数是你传入的对象,它会返回对象的属性和方法
print(dir(list))
4、globals()
以字典类型返回当前位置的全部全局变量。
print(globals()) {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7f83a81686d8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/sanpangdan/Desktop/python_fullstack/day18.py', '__cached__': None}
5、divmod()
divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
print(divmod(7,2)) (3, 1)
6、pow() 和
它计算并返回x的y次方的值

与之相反的是开根.sqrt()
print(math.sqrt(9))
7、eval()
用来执行一个字符串或者字符串表达式,并返回表达式的值。
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
接受的是什么数据类型就转换成什么类型
比如 a = eval(input()),input默认接受的都是字符串,输入一个列表,eval会转成列表
a = eval(input('enter:'))
b = input('enter:')
print(type(a), type(b))
# enter:[1,2,3]
# enter:123
# <class 'list'> <class 'str'>
8、exec() 执行字符串类型的代码
s2 = "for i in range(5): print(i)" a = exec(s2) # exec 执行代码不返回任何内容 print(a) # 0 # 1 # 2 # 3 # 4 # None
9、isinstance()
判断数据类型是否一致
l = [1, 2, 3, 4] print(isinstance(l, list))
10、字符编码相关的
ord()
输入字符找带字符编码的位置
print(ord('A') # 65 print(ord('a') # 97
chr()
输入位置数字找出对应的字符
print(chr(97)) # a
ascii()
是ascii码中的返回该值 不是就返回u
11、hash()
用于获取取一个对象(字符串或者数值等)的哈希值。
print(hash('test13'))
12、all() 和 any()
all()
l = [1, 2, 3, 4, " ", None] l2 = {} print(all(l2))
函数接受一个可迭代对象作为参数,仅当可迭代对象中的所有项的计算结果为 True,或者或可迭代对象为空时才返回 True。
any()
函数将一个可迭代对象作为参数,只要该可迭代对象中至少有一项为 True,则输出为True。
any() 函数检查字符串中的数字,有数字则返回True
my_string = "coding**is**cool**345" # 列表推导 res = [char.isdigit() for char in my_string] print(any(res))
13、bytes() 字节函数
bytes 只负责以字节序列的形式(二进制形式)来存储数据
bytes 类型的数据非常适合在互联网上传输,可以用于网络通信编程;bytes 也可以用来存储图片、音频、视频等二进制格式的文件。
b4 = bytes('C语言中文网8岁了', encoding='UTF-8') print(b4) # b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86' print(b4.decode(encoding='UTF-8')) s = str(b4, 'utf-8') print(s) """ b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86' C语言中文网8岁了 C语言中文网8岁了 """
14、enumerate() 枚举
enumerate参数为可遍历/可迭代的对象(如列表、字符串)
enumerate多用于在for循环中得到计数,利用它可以同时获得索引和值,即需要index和value值的时候可以使用enumerate
enumerate()返回的是一个enumerate对象
l = [1, 2, 3, 4, 5] e = enumerate(l) for index, value in e: print('%s, %s' % (index, value))
还可以指定索引从哪里开始,以1为例
s = [1, 2, 3, 4, 5] for index, value in enumerate(s, 1): print('%s, %s' % (index, value))

15、vars()
vars()函数返回对象的__dic__属性。
__dict__属性是包含对象的可变属性的字典。
注意:不带参数调用vars()函数将返回包含本地的属性和属性值的字典,类似 locals()。
class Person: name = "John" age = 36 country = "norway" x = vars(Person) print(x) # 输出 {'__module__': '__main__', 'name': 'John', 'age': 36, 'country': 'norway', '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None}
16、max()
phone = {'mac': 19000, 'iphone': 10000, 'xiaomi': 5000, 'vivo': 5000, 'huawei': 21000}
max_k = max(phone, key=phone.get)
print(max_k)
phone.get 是字典的一个方法,用于获取指定键的值。当你使用 phone.get 时,它返回一个可调用对象,可以用于获取字典中指定键的值。
在 max() 函数中,key 参数用于指定一个函数,该函数将作用于可迭代对象中的每个元素,并返回一个用于比较的关键字。在这个例子中,我们使用 phone.get 作为 key 参数。
具体地说,当 max() 函数迭代字典 phone 中的键时,对于每个键(手机品牌),它会调用 phone.get 方法并传入该键作为参数,以获取对应的价格。然后,max() 函数将使用这些价格进行比较,并找到具有最大价格的键(即最贵的手机品牌)。
在这个例子中,max_k = max(phone, key=phone.get) 执行后,max_k 将存储具有最大价格的手机品牌。通过将 phone.get 作为 key 参数,我们实现了根据手机价格进行比较的逻辑,并找到了价格最高的手机品牌。
17、filter():过滤,和 map 函数很像()里面接收函数和可迭代对象
filter(function, iterable)
l = [11, 22, 33, 44, 55]
ls = []
# for i in ll:
# if i > 30:
# ls.append(i)
res = filter(lambda key: key > 30, l) # lambda 匿名函数,key表示形参,中间是条件,l是可迭代数据类型
print(list(res))
[33, 44, 55]
def is_odd(n):
return n % 2 == 1
newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
for i in newlist:
print(i)
结果:
1
3
5
7
9
18、zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
l1 = [1, 2, 3, 4, 5 ]
l2 = [11, 21, 31, 41, 51]
l3 = [21, 22, 23, 24, 25]
res=zip(l1, l2, l3) # 拉链
print(list(res))
[(1, 11, 21), (2, 21, 22), (3, 31, 23), (4, 41, 24), (5, 51, 25)]
########
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
for item1, item2 in zip(list1, list2):
print(f"Item from list1: {item1}, Item from list2: {item2}")
Item from list1: 1, Item from list2: a
Item from list1: 2, Item from list2: b
Item from list1: 3, Item from list2: c
itertools模块
可以将多个列表或其他可迭代对象连接起来,形成一个新的迭代器
import itertools
for item in itertools.chain([1, 2, 3], ['a', 'b', 'c']):
print(item)
19、map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
map(function, 可迭代数据类型) # 计算列表各个元素的平方
def square(x): # 计算平方数
return x ** 2
l = [1, 2, 3, 4, 5]
map(square, l) # 计算列表各个元素的平方
a = list(map(square, l)) # 使用 list() 转换为列表
print(a)
# 结果: [1, 4, 9, 16, 25]
b = list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数
print(b)
# 结果: [1, 4, 9, 16, 25]
慢慢补充


