递归、二分查找、冒泡排序
一、递归查找
什么是递归函数?
递归就是直接或者间接调用自己的函数就是递归函数
1、案例
l = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, [11, [12, [13]]]]]]]]]]]]]
列表嵌套,要求打印出所有的数字(不带列表)
2、思路
循环打印:
- 判断元素是不是列表,如果是列表不打印,如果不是列表则打印
- 继续判断,元素是不是列表,如果不是则打印,如果是,不在打印
- 继续循环,判断元素是不是列表,如果不是,则打印,如果是,不打印
- 继续循环...
3、代码实现
l = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, [11, [12, [13]]]]]]]]]]]]] def recursion(l): # 定义一个函数 for i in l: if str(i).isdigit(): # 将元素转换为 str,内容内置方法判断是数字组成 print(i) else: recursion(i) recursion(l) # 函数调用
或者判断 i 的类型
if type(i) is int:
第一次传参为列表 l,后续传参 i 为 l 里面的嵌套列表
结果:
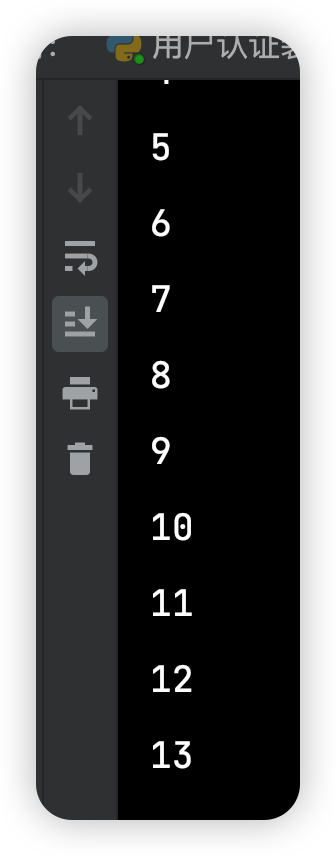
二、二分查找
1、思路
- 可迭代的数据类型首选要做一个排序
- 排序求出中间值mid,中间的索引使用 len(l)//2 来确认
- 先定义左右边界的起始点,起始左边界为 0,右边界为 len(l),即列表的最右边
- 再利用中间索引值与目标值索引值进行比较,以此来确认左右两边的数字大小
2、代码
写法一:
# 定义二分查找函数 def binary_search(sorted_list, target): left = 0 # 左边范围定义为最开始的地方,即下标为 0 right = len(sorted_list) # 右边宽度位置,定义为列表长度,即最右边 while left <= right: # 当左边小于等于右边,满足可以切 mid = (left + right) // 2 # 定义中间索引等于左边+右边整除2,返回商的整数部分 mid_value = sorted_list[mid] # 定义中间值等于列表取中间索引 if mid_value == target: # 判断:中间值与目标值是否相等 return mid # 条件成立,返回索引位置,中断程序执行 elif mid_value < target: # 判断:中间值是否小于目标值 left = mid + 1 # 条件成立,左边等于中间值+1 else: right = mid - 1 # 否则右边减1 return None # 上面没有查找到目标值,返回None # 选择一个目标值进行二分查找 l = [11, 2, 3, 44, 567, 34, 78, 89, 111, 23, 34, 45, 56, 78, 66] l.sort() # 列表需要做一个排序 print(f'有序列表为:\n {l}') target = 111 # 设置目标值 result = binary_search(l, target) # 'xx' 等于函数时候,取的是函数的返回值 # # 判断整个函数的返回值,返回值不为None,查找到,否则没有查找到。 if result is not None: print(f"The target {target} is at index {result}.") else: print(f"The target {target} is not in the sorted list.")
写法 2:使用函数递归
# 二分查找法(使用递归) l = [12, 23, 34, 54, 12, 65, 76, 87, 89, 100, 120, 130, 145, 146, 147, 148, 222, 233, 244] # 排序 l.sort() # 定义一目标查找值 target = 244 def birnary(l, target): if len(l) == 0: # 判断列表是否有为空 print('列表为空') return # 判断列表为空,return 结束程序 mid = len(l) // 2 # 定义一个中间值,列表长度取整 if l[mid] > target: # 如果中间值大于目标值 l_left = l[:mid] # 右边的列表切掉,使用切片表示剩余左边的列表 print(l_left) birnary(l_left, target) # 嵌套方法 elif l[mid] < target: # 如果中间值小于目标值 l_right = l[mid + 1:] # 左边切掉,使用切片表示剩余右边的列表 print(l_right) birnary(l_right, target) else: print(f'{target} 找到了') birnary(l, target)
三、冒泡排序的原理
1. 比较相邻的两个元素。如果第一个比第二个大则交换他们的位置(升序排列,降序则反过来)。
2. 从列表的开始一直到结尾,依次对每一对相邻元素都进行比较。这样,值最大的元素就通过交换“冒泡”到了列表的结尾,完成第一轮“冒泡”。
3. 重复上一步,继续从列表开头依次对相邻元素进行比较。已经“冒泡”出来的元素不用比较(一直比较到结尾也可以,已经“冒泡”到后面的元素即使比较也不需要交换,不比较可以减少步骤)。
4. 继续从列表开始进行比较,每轮比较会有一个元素“冒泡”成功。每轮需要比较的元素个数会递减,一直到只剩一个元素没有“冒泡”时(没有任何一对元素需要比较),则列表排序完成。
1、思路
将上述的原理用python进行翻译,i 表示第几轮“冒泡”,j 表示“走访”到的元素索引。每一轮“冒泡”中,j 需要从列表开头“走访”到 len(array) - i 的位置
array[j] > array[j+1] 表示将前一个元素同后一个元素比较(相邻两元素),array[j], array[j+1] = array[j+1], array[j]表示左右置换
2、代码
def bubble_sort(var): for i in range(1, len(l)): for j in range(0, len(l) - i): if l[j] > l[j + 1]: l[j], l[j + 1] = l[j + 1], l[j] return l if __name__ == '__main__': l = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21] print(bubble_sort(l))
注解:
1、return的用法作用:
return语句用于退出函数,终止函数并将函数作用后的结果return值传回
2、if判断结构
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
3、for循环结构
for <variable> in <sequence>:
<statements>
4、数组和列表list的区别
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
list = [1, 2, 3, 4, 5 ]
- 1. 列表list与数组array的定义:
列表是由一系列按特定顺序排列的元素组成,可以将任何东西加入列表中,其中的元素之间没有任何关系;
Python中的列表(list)用于顺序存储结构。它可以方便、高效的的添加删除元素,并且列表中的元素可以是多种类型。
数组也就是一个同一类型的数据的有限集合。
- 2. 列表list与数组array的相同点:
a. 都可以根据索引来取其中的元素;
- 3. 列表list与数组array的不同点:
a.列表list中的元素的数据类型可以不一样。数组array里的元素的数据类型必须一样;
b.列表list不可以进行数学四则运算,数组array可以进行数学四则运算;
c.相对于array,列表会使用更多的存储空间;
d.list是python内置的数据类型。
去掉 if __name__ == '__main__'部分的判断,如下:
#!/usr/bin/python def bubble_sort(array): for i in range(1, len(array)): for j in range(0, len(array)-i): if array[j] > array[j+1]: array[j], array[j+1] = array[j+1], array[j] return array array = [100,10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21] print(bubble_sort(array)) print(__name__)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号