kubernetes HPA
HPA全称是Horizontal Pod Autoscaler,翻译成中文是POD水平自动伸缩,以下都会用HPA代替Horizontal Pod Autoscaler,HPA可以基于CPU利用率对replication controller、deployment和replicaset中的pod数量进行自动扩缩容(除了CPU利用率也可以基于其他应程序提供的度量指标custom metrics进行自动扩缩容)。pod自动缩放不适用于无法缩放的对象,比如DaemonSets。HPA由Kubernetes API资源和控制器实现。资源决定了控制器的行为。控制器会周期性的获取平均CPU利用率,并与目标值相比较后来调整replication controller或deployment中的副本数量。
HorizontalPodAutoscaler Walkthrough | Kubernetes 官网介绍
custom metrics详细介绍参考如下:
1 | https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/custom-metrics-api.md |
参考官网地址如下:
1 | https://v1-17.docs.kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ |
一、HPA工作原理
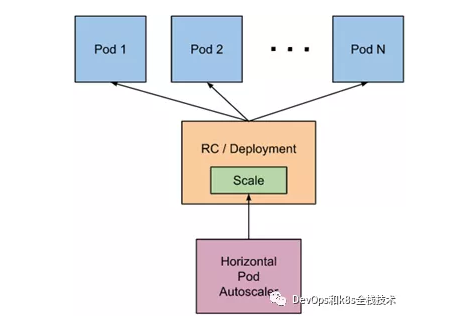
HPA的实现是一个控制循环,由controller manager的--horizontal-pod-autoscaler-sync-period参数指定周期(默认值为15秒)。每个周期内,controller manager根据每个HorizontalPodAutoscaler定义中指定的指标查询资源利用率。controller manager可以从resource metrics API(pod 资源指标)和custom metrics API(自定义指标)获取指标。
1)对于每个pod的资源指标(如CPU),控制器从资源指标API中获取每一个 HorizontalPodAutoscaler指定的pod的指标,然后,如果设置了目标使用率,控制器获取每个pod中的容器资源使用情况,并计算资源使用率。如果使用原始值,将直接使用原始数据(不再计算百分比)。然后,控制器根据平均的资源使用率或原始值计算出缩放的比例,进而计算出目标副本数。需要注意的是,如果pod某些容器不支持资源采集,那么控制器将不会使用该pod的CPU使用率
2)如果 pod 使用自定义指标,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
3)如果pod 使用对象指标和外部指标(每个指标描述一个对象信息)。这个指标将直接跟据目标设定值相比较,并生成一个上面提到的缩放比例。在autoscaling/v2beta2版本API中,这个指标也可以根据pod数量平分后再计算。通常情况下,控制器将从一系列的聚合API(metrics.k8s.io、custom.metrics.k8s.io和external.metrics.k8s.io)中获取指标数据。metrics.k8s.io API通常由 metrics-server(需要额外启动)提供。
二、metrics server
metrics-server是一个集群范围内的资源数据集和工具,同样的,metrics-server也只是显示数据,并不提供数据存储服务,主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等
使用HPA前提:
A、部署好metrics-server
B、部署pod时候要设置资源requests
1.部署metrics-server,在k8s的master节点操作
1)通过离线方式获取镜像
需要的镜像是:
1 2 | k8s.gcr.io/metrics-server-amd64:v0.3.6和k8s.gcr.io/addon-resizer:1.8.4 |
镜像所在百度网盘地址如下:
1 2 3 4 | 链接:https://pan.baidu.com/s/1SKpNaskVr_zQJVQuM_GzIQ提取码:24yb链接:https://pan.baidu.com/s/1KXOSiSJGGGaUXCjdCHoXjQ提取码:yab5docker load -i metrics-server-amd64_0_3_1.tar.gz |
2)metrics.yaml文件
cat metrics.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 | apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: metrics-server:system:auth-delegator labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: ReconcileroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegatorsubjects:- kind: ServiceAccount name: metrics-server namespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata: name: metrics-server-auth-reader namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: ReconcileroleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-readersubjects:- kind: ServiceAccount name: metrics-server namespace: kube-system---apiVersion: v1kind: ServiceAccountmetadata: name: metrics-server namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: system:metrics-server labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces verbs: - get - list - watch- apiGroups: - "extensions" resources: - deployments verbs: - get - list - update - watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: system:metrics-server labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: ReconcileroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-serversubjects:- kind: ServiceAccount name: metrics-server namespace: kube-system---apiVersion: v1kind: ConfigMapmetadata: name: metrics-server-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExistsdata: NannyConfiguration: |- apiVersion: nannyconfig/v1alpha1 kind: NannyConfiguration---apiVersion: apps/v1kind: Deploymentmetadata: name: metrics-server namespace: kube-system labels: k8s-app: metrics-server kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile version: v0.3.6spec: selector: matchLabels: k8s-app: metrics-server version: v0.3.6 template: metadata: name: metrics-server labels: k8s-app: metrics-server version: v0.3.6 annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-cluster-critical serviceAccountName: metrics-server containers: - name: metrics-server image: k8s.gcr.io/metrics-server-amd64:v0.3.6 command: - /metrics-server - --metric-resolution=30s - --kubelet-preferred-address-types=InternalIP - --kubelet-insecure-tls ports: - containerPort: 443 name: https protocol: TCP - name: metrics-server-nanny image: k8s.gcr.io/addon-resizer:1.8.4 resources: limits: cpu: 100m memory: 300Mi requests: cpu: 5m memory: 50Mi env: - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: metrics-server-config-volume mountPath: /etc/config command: - /pod_nanny - --config-dir=/etc/config - --cpu=300m - --extra-cpu=20m - --memory=200Mi - --extra-memory=10Mi - --threshold=5 - --deployment=metrics-server - --container=metrics-server - --poll-period=300000 - --estimator=exponential - --minClusterSize=2 volumes: - name: metrics-server-config-volume configMap: name: metrics-server-config tolerations: - key: "CriticalAddonsOnly" operator: "Exists" - key: node-role.kubernetes.io/master effect: NoSchedule---apiVersion: v1kind: Servicemetadata: name: metrics-server namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" kubernetes.io/name: "Metrics-server"spec: selector: k8s-app: metrics-server ports: - port: 443 protocol: TCP targetPort: https---apiVersion: apiregistration.k8s.io/v1beta1kind: APIServicemetadata: name: v1beta1.metrics.k8s.io labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilespec: service: name: metrics-server namespace: kube-system group: metrics.k8s.io version: v1beta1 insecureSkipTLSVerify: true groupPriorityMinimum: 100 versionPriority: 100kubectl apply -f metrics.yaml3)验证metrics-server是否部署成功kubectl get pods -n kube-system显示如下running状态说明启动成功4)测试kubectl top命令metrics-server组件安装成功之后,就可以使用kubectl top命令了kubectl top nodes显示如下:NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master 660m 16% 1608Mi 20% k8s-node 348m 8% 1046Mi 28% kubectl top pods -n kube-system显示如下:NAME CPU(cores) MEMORY(bytes) calico-node-9wkmr 100m 26Mi calico-node-sp5m6 162m 35Mi coredns-6955765f44-j2xrl 8m 8Mi coredns-6955765f44-th2sb 10m 8Mi etcd-k8s-master 48m 44Mi kube-apiserver-k8s-master 128m 286Mi kube-controller-manager-k8s-master 79m 38Mi kube-proxy-9s48h 2m 17Mi kube-proxy-vcx2s 2m 10Mi kube-scheduler-k8s-master 12m 15Mi metrics-server-5cf9669fbf-jmrdx 3m 17Mi |
三、HPA API对象
HPA的API有三个版本,通过kubectl api-versions | grep autoscal可看到
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
1 2 3 | autoscaling/v1只支持基于CPU指标的缩放;autoscaling/v2beta1支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)的缩放;autoscaling/v2beta2支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)和ExternalMetrics(额外指标)的缩放。 |
四、使用kubectl操作HPA
与其他API资源类似,kubectl也支持Pod自动伸缩。我们可以通过kubectl create命令创建一个自动伸缩对象,通过kubectl get hpa命令来获取所有自动伸缩对象,通过kubectl describe hpa命令来查看自动伸缩对象的详细信息。最后,可以使用kubectl delete hpa命令删除对象。此外,还有个简便的命令kubectl autoscale来创建自动伸缩对象。例如,命令kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80将会为名为foo的replication set创建一个自动伸缩对象,对象目标的CPU使用率为80%,副本数量配置为2到5之间。
五、多指标支持
在Kubernetes1.6+中支持基于多个指标进行缩放。你可以使用autoscaling/v2beta2 API来为HPA指定多个指标。HPA会跟据每个指标计算,并生成一个缩放建议。
六、自定义指标支持
自Kubernetes1.6起,HPA支持使用自定义指标。你可以使用autoscaling/v2beta2 API为HPA指定用户自定义指标。Kubernetes会通过用户自定义指标API来获取相应的指标。
七、测试HPA的autoscaling/v1版-基于CPU的自动扩缩容
用Deployment创建一个php-apache服务,然后利用HPA进行自动扩缩容。步骤如下:
1.通过deployment创建pod,在k8s的master节点操作
1)创建并运行一个php-apache服务
使用dockerfile构建一个新的镜像,在k8s的master节点构建
cat dockerfile
1 2 3 | FROM php:5-apacheADD index.php /var/www/html/index.phpRUN chmod a+rx index.php |
cat index.php
1 2 3 4 5 6 7 | <?php $x = 0.0001; for ($i = 0; $i <= 1000000;$i++) { $x += sqrt($x); } echo "OK!";?> |
docker build -t k8s.gcr.io/hpa-example:v1 .
2)打包镜像
docker save -o hpa-example.tar.gz k8s.gcr.io/hpa-example:v1
3)解压镜像
可以把镜像传到k8s的各个节点,docker load-i hpa-example.tar.gz进行解压
4)通过deployment部署一个php-apache服务
cat php-apache.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | apiVersion:apps/v1kind:Deploymentmetadata: name:php-apachespec: selector: matchLabels: run:php-apache replicas:1 template: metadata: labels: run:php-apache spec: containers: -name:php-apache image:k8s.gcr.io/hpa-example:v1 ports: -containerPort:80 resources: limits: cpu:500m requests: cpu:200m---apiVersion: v1kind:Servicemetadata: name:php-apache labels: run:php-apachespec: ports: -port:80 selector: run:php-apache |
kubectl apply -f php-apache.yaml
5)验证php是否部署成功
kubectl get pods
显示如下,说明php服务部署成功了
1 2 | NAME READY STATUS RESTARTS AGEphp-apache-5694767d56-mmr88 1/1 Running 0 66s |
2.创建HPA
php-apache服务正在运行,使用kubectl autoscale创建自动缩放器,实现对php-apache这个deployment创建的pod自动扩缩容,下面的命令将会创建一个HPA,HPA将会根据CPU,内存等资源指标增加或减少副本数,创建一个可以实现如下目的的hpa:
1 2 | 1)让副本数维持在1-10个之间(这里副本数指的是通过deployment部署的pod的副本数)2)将所有Pod的平均CPU使用率维持在50%(通过kubectlrun运行的每个pod如果是200毫核,这意味着平均CPU利用率为100毫核) |
1)给上面php-apache这个deployment创建HPA
1 | kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10 |
上面命令解释说明
1 2 | kubectl autoscale deployment php-apache (php-apache表示deployment的名字) --cpu-percent=50(表示cpu使用率不超过50%) --min=1(最少一个pod) --max=10(最多10个pod) |
2)验证HPA是否创建成功
kubectl get hpa
3.压测php-apache服务,只是针对CPU做压测
启动一个容器,并将无限查询循环发送到php-apache服务(复制k8s的master节点的终端,也就是打开一个新的终端窗口)
1 2 3 | kubectl run -it load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"If you don't see a command prompt, try pressing enter.OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK |
在一分钟左右的时间内,我们通过执行以下命令来看到更高的CPU负载
kubectl get hpa
显示如下:

上面可以看到,CPU消耗已经达到256%,每个pod的目标cpu使用率是50%,所以,php-apache这个deployment创建的pod副本数将调整为5个副本,为什么是5个副本,因为256/50=5
kubectl get pod
显示如下:
1 2 3 4 5 6 | NAME READY STATUS RESTARTS AGEphp-apache-5694767d56-b2kd7 1/1 Running 0 18sphp-apache-5694767d56-f9vzm 1/1 Running 0 2sphp-apache-5694767d56-hpgb5 1/1 Running 0 18sphp-apache-5694767d56-mmr88 1/1 Running 0 4h13mphp-apache-5694767d56-zljkd 1/1 Running 0 18s |
kubectl get deployment php-apache
显示如下:
1 2 | kubectl get deployment php-apache显示如下: |
注意:可能需要几分钟来稳定副本数。由于不以任何方式控制负载量,因此最终副本数可能会与此示例不同。
4.停止对php-apache服务压测,HPA会自动对php-apache这个deployment创建的pod做缩容
停止向php-apache这个服务发送查询请求,在busybox镜像创建容器的终端中,通过<Ctrl>+ C把刚才while请求停止,然后,我们将验证结果状态(大约一分钟后):
kubectl get hpa
......
通过上面可以看到,CPU利用率下降到0,因此HPA自动将副本数缩减到1。
注意:自动缩放副本可能需要几分钟。
八、测试HPA autoscaling/v2beta1版本-基于内存的自动扩缩容
1.创建一个nginx的pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | cat nginx.yamlapiVersion:apps/v1kind: Deploymentmetadata: name:nginx-hpaspec: selector: matchLabels: app: nginx replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.9.1 ports: - containerPort: 80 name: http protocol: TCP resources: requests: cpu: 0.01 memory: 25Mi limits: cpu: 0.05 memory: 60Mi---apiVersion: v1kind: Servicemetadata: name: nginx labels: app: nginxspec: selector: app: nginx type: NodePort ports: - name: http protocol: TCP port: 80 targetPort: 80 nodePort: 30080 kubectl apply -f nginx.yaml |
2.验证nginx是否运行
kubectl get pods
显示如下,说明nginx的pod正常运行:
1 2 | NAME READY STATUS RESTARTS AGEnginx-hpa-bb598885d-j4kcp 1/1 Running 0 17m |
注意:nginx的pod里需要有如下字段,否则hpa会采集不到内存指标
1 2 3 4 5 6 7 | resources: requests: cpu: 0.01 memory: 25Mi limits: cpu: 0.05 memory: 60Mi |
3.创建一个hpa
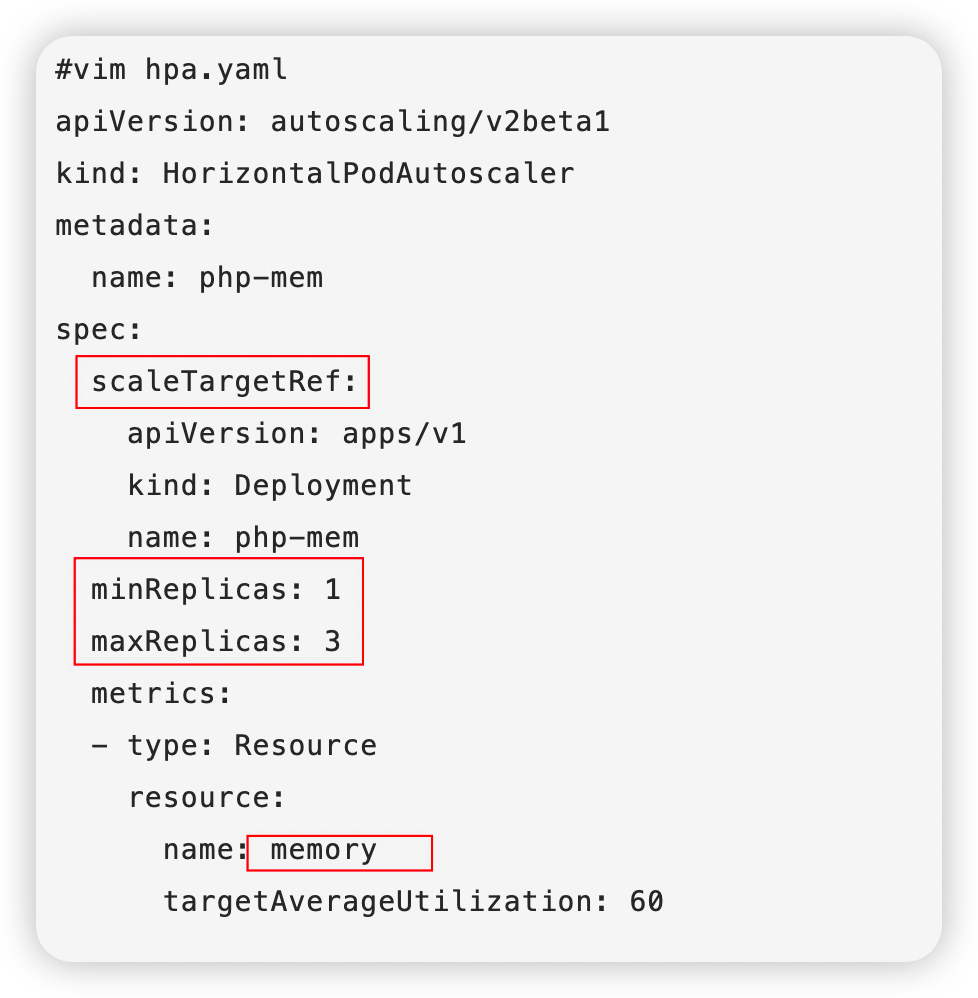
cat hpa-v1.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | apiVersion: autoscaling/v2beta1kind: HorizontalPodAutoscalermetadata: name: nginx-hpaspec: maxReplicas: 10 minReplicas: 1 scaleTargetRef: apiVersion:apps/v1 kind: Deployment name: nginx-hpa metrics: - type: Resource resource: name: memory targetAverageUtilization: 60 |
kubectl get hpa
显示如下:
1 2 | NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx-hpa Deployment/nginx-hpa 5%/60% 1 10 1 20s |
4.压测nginx的内存,hpa会对pod自动扩缩容
登录到上面通过pod创建的nginx,并生成一个文件,增加内存
1 | kubectl exec -it nginx-hpa-bb598885d-j4kcp -- /bin/sh |
压测:
1 | dd if=/dev/zero of=/tmp/a |
打开新的终端:
1 | kubectl get hpa |
显示如下:
1 2 | NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx-hpa Deployment/nginx-hpa 200%/60% 1 10 3 12m |
上面的targets列可看到200%/60%,200%表示当前cpu使用率,60%表示所有pod的cpu使用率维持在60%,现在cpu使用率达到200%,所以pod增加到4个
kubectl get deployment
显示如下:
1 2 | NAME READY UP-TO-DATE AVAILABLE AGEnginx-hpa 4/4 4 4 25m |
5.取消对nginx内存的压测,hpa会对pod自动缩容
1 | kubectl exec -it nginx-hpa-bb598885d-j4kcp -- /bin/sh |
删除/tmp/a这个文件
1 | rm -rf /tmp/a |
kubectl get hpa
显示如下,可看到内存使用率已经降到5%:
1 2 | NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx-hpa Deployment/nginx-hpa 5%/60% 1 10 1 26m |
kubectl get deployment
显示如下,deployment的pod又恢复到1个了:
1 2 | NAME READY UP-TO-DATE AVAILABLE AGEnginx-hpa 1/1 1 1 38m |
九、基于多项指标和自定义指标的自动缩放
可以通过使用autoscaling/v2beta2 API版本来介绍在自动缩放php-apache这个deployment时使用的其他度量指标(metrics)。
获取autoscaling/v2beta2 API版本HPA的yaml文件
1 | kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml |
在编辑器打开文件/tmp/hpa-v2.yaml,删除掉一些不需要要的字段,可看到如下yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata: name: php-apache namespace: defaultspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50status: observedGeneration: 1 lastScaleTime: <some-time> currentReplicas: 1 desiredReplicas: 1 currentMetrics: - type: Resource resource: name: cpu current: averageUtilization: 0 averageValue: 0 |
targetCPUUtilizationPercentage字段由metrics所取代,CPU利用率这个度量指标是一个resource metric(资源度量指标),因为它表示容器上指定资源的百分比。 除CPU外,你还可以指定其他资源度量指标。默认情况下,目前唯一支持的其他资源度量指标为内存。只要metrics.k8s.io API存在,这些资源度量指标就是可用的,并且他们不会在不同的Kubernetes集群中改变名称。你还可以指定资源度量指标使用绝对数值,而不是百分比,你需要将target类型AverageUtilization替换成AverageValue,同时将target.averageUtilization替换成target.averageValue并设定相应的值。还有两种其他类型的度量指标,他们被认为是*custom metrics*(自定义度量指标): 即Pod度量指标和对象度量指标(pod metrics and object metrics)。这些度量指标可能具有特定于集群的名称,并且需要更高级的集群监控设置。第一种可选的度量指标类型是Pod度量指标。这些指标从某一方面描述了Pod,在不同Pod之间进行平均,并通过与一个目标值比对来确定副本的数量。它们的工作方式与资源度量指标非常相像,差别是它们仅支持target类型为
AverageValue。
Pod 度量指标通过如下代码块定义
1 2 3 4 5 6 7 | type: Podspods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k |
第二种可选的度量指标类型是对象度量指标。相对于描述Pod,这些度量指标用于描述一个在相同名字空间(namespace)中的其他对象。请注意这些度量指标用于描述这些对象,并非从对象中获取。对象度量指标支持的target类型包括Value和AverageValue。如果是Value类型,target值将直接与API返回的度量指标比较,而AverageValue类型,API返回的度量指标将按照Pod数量拆分,然后再与target值比较。下面的YAML文件展示了一个表示requests-per-second的度量指标。
1 2 3 4 5 6 7 8 9 10 11 | type: Objectobject: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1beta1 kind: Ingress name: main-route target: type: Value value: 2k |
如果你指定了多个上述类型的度量指标,HorizontalPodAutoscaler将会依次考量各个指标。HorizontalPodAutoscaler将会计算每一个指标所提议的副本数量,然后最终选择一个最高值。比如,如果你的监控系统能够提供网络流量数据,你可以通过kubectl edit命令将上述Horizontal Pod Autoscaler的定义更改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | apiVersion: autoscaling/v2beta1kind: HorizontalPodAutoscalermetadata: name: php-apache namespace: defaultspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: AverageUtilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second targetAverageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1beta1 kind: Ingress name: main-route target: kind: Value value: 10kstatus: observedGeneration: 1 lastScaleTime: <some-time> currentReplicas: 1 desiredReplicas: 1 currentMetrics: - type: Resource resource: name: cpu current: averageUtilization: 0 averageValue: 0 - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1beta1 kind: Ingress name: main-route current: value: 10k |
然后,你的HorizontalPodAutoscaler将会尝试确保每个Pod的CPU利用率在50%以内,每秒能够服务1000个数据包请求,并确保所有在Ingress后的Pod每秒能够服务的请求总数达到10000个。
十、在更多指定指标下的自动伸缩
许多度量管道允许你通过名称或附加的_labels_来描述度量指标。对于所有非资源类型度量指标(pod、object和后面将介绍的external),可以额外指定一个标签选择器。例如,如果你希望收集包含verb标签的http_requests度量指标, 你可以在GET请求中指定需要的度量指标,如下所示:
1 2 3 4 5 | type:Objectobject: metric: name:`http_requests` selector:`verb=GET` |
这个选择器使用与Kubernetes标签选择器相同的语法。如果名称和标签选择器匹配到多个系列,监测管道会决定如何将多个系列合并成单个值。选择器是附加的,它不会选择目标以外的对象(类型为Pods的目标和类型为Object的目标)。
十一、基于kubernetes对象以外的度量指标自动扩缩容
运行在Kubernetes上的应用程序可能需要基于与Kubernetes集群中的任何对象没有明显关系的度量指标进行自动伸缩,例如那些描述不在Kubernetes任何namespaces服务的度量指标。使用外部的度量指标,需要了解你使用的监控系统,相关的设置与使用自定义指标类似。 External metrics可以使用你的监控系统的任何指标来自动伸缩你的集群。你只需要在metric块中提供name和selector,同时将类型由Object改为External。如果metricSelector匹配到多个度量指标,HorizontalPodAutoscaler将会把它们加和。 External metrics同时支持Value和AverageValue类型,这与Object类型的度量指标相同。例如,如果你的应用程序处理主机上的消息队列, 为了让每30个任务有1个worker,你可以将下面的内容添加到 HorizontalPodAutoscaler 的配置中。
1 2 3 4 5 6 7 8 | -type:External external: metric: name:queue_messages_ready selector:"queue=worker_tasks" target: type:AverageValue averageValue:30 |
还是推荐custom metric而不是external metrics,因为这便于让系统管理员加固custom metrics API。而external metrics API可以允许访问所有的度量指标,当暴露这些服务时,系统管理员需要仔细考虑这个问题。
十二、经验
1、部署deployment pod
1 | kubectl create deployment java-web3 --image=java-demo:v1 |
命令行方式创建的pod,没有对资源做出限制,导致
1 | kubectl edit hpa java-web2 没有相应的images、containters字段,没有办法修改requests。 |
正解:修改deployment/pod request 字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | kubectl edit deployments.apps java-web2....spec: containers: - image: java-demo:v1 imagePullPolicy: IfNotPresent name: java-demo resources: limits: cpu: "1" requests: cpu: 500m...... |
创建java-web3 pod 的 hpa
1 | kubectl autoscale deployment java-web3 --min=3 --max=7 --cpu-percent=70 |
暴露pod服务
1 | kubectl expose deployment java-web3 --port=80 --target-port=8080 |
获取server ip
1 2 3 | [root@master ~]# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEjava-web2 ClusterIP 10.106.10.163 <none> 80/TCP 50m |
人为增大访问量
1 | for i in {1..10000};do curl 10.106.10.163; done |
测试
1 | kubectl get hpa |

https://mp.weixin.qq.com/s/6uy1fvzz2Y34DB7ugZ0PAQ
1 | java-web3 |



