ceph日常运维管理
一、常见问题
nearfull osd(s) or pool(s) nearfull
或者Ceph osd负载不均衡
此时说明部分osd的存储已经超过阈值,mon会监控ceph集群中OSD空间使用情况。如果要消除WA,可以修改这两个参数,提高阈值,但是通过实践发现并不能解决问题,可以通过观察osd的数据分布情况来分析原因。
配置文件设置阈值
1 2 | "mon_osd_full_ratio": "0.95","mon_osd_nearfull_ratio": "0.85" |
自动处理
1 2 | ceph osd reweight-by-utilizationceph osd reweight-by-pg 105 cephfs_data(pool_name) |
手动处理
注: reweight的值不超过1,osd.2表示编号为2的osd
1 | ceph osd reweight osd.2 0.8 |
全局处理
1 2 3 4 5 | ceph mgr module lsceph mgr module enable balancerceph balancer onceph balancer mode crush-compatceph config-key set "mgr/balancer/max_misplaced": "0.01" |
二、PG 故障状态
PG状态概述 一个PG在它的生命周期的不同时刻可能会处于以下几种状态中:
1.Creating(创建中) 在创建POOL时,需要指定PG的数量,此时PG的状态便处于creating,意思是Ceph正在创建PG。
2.Peering(互联中) peering的作用主要是在PG及其副本所在的OSD之间建立互联,并使得OSD之间就这些PG中的object及其元数据达成一致。
3.Active(活跃的) 处于该状态意味着数据已经完好的保存到了主PG及副本PG中,并且Ceph已经完成了peering工作。
4.Clean(整洁的) 当某个PG处于clean状态时,则说明对应的主OSD及副本OSD已经成功互联,并且没有偏离的PG。也意味着Ceph已经将该PG中的对象按照规定的副本数进行了复制操作。5.Degraded(降级的) 当某个PG的副本数未达到规定个数时,该PG便处于degraded状态。
6.在客户端向主OSD写入object的过程,object的副本是由主OSD负责向副本OSD写入的,直到副本OSD在创建object副本完成,并向主OSD发出完成信息前,该PG的状态都会一直处于degraded状态。又或者是某个OSD的状态变成了down,那么该OSD上的所有PG都会被标记为degraded。当Ceph因为某些原因无法找到某个PG内的一个或多个object时,该PG也会被标记为degraded状态。此时客户端不能读写找不到的对象,但是仍然能访问位于该PG内的其他object。
7.Recovering(恢复中) 当某个OSD因为某些原因down了,该OSD内PG的object会落后于它所对应的PG副本。而在该OSD重新up之后,该OSD中的内容必须更新到当前状态,处于此过程中的PG状态便是recovering。
8.Backfilling(回填) 当有新的OSD加入集群时,CRUSH会把现有集群内的部分PG分配给它。这些被重新分配到新OSD的PG状态便处于backfilling。
9.Remapped(重映射) 当负责维护某个PG的acting set变更时,PG需要从原来的acting set迁移至新的acting set。这个过程需要一段时间,所以在此期间,相关PG的状态便会标记为remapped。10.Stale(陈旧的) 默认情况下,OSD守护进程每半秒钟便会向Monitor报告其PG等相关状态,如果某个PG的主OSD所在acting set没能向Monitor发送报告,或者其他的Monitor已经报告该OSD为down时,该PG便会被标记为stale。
三、OSD状态
单个OSD有两组状态需要关注,其中一组使用in/out标记该OSD是否在集群内,另一组使用up/down标记该OSD是否处于运行中状态。两组状态之间并不互斥,换句话说,当一个OSD处于“in”状态时,它仍然可以处于up或down的状态。
1.OSD状态为in且up 这是一个OSD正常的状态,说明该OSD处于集群内,并且运行正常。
2.OSD状态为in且down 此时该OSD尚处于集群中,但是守护进程状态已经不正常,默认在300秒后会被踢出集群,状态进而变为out且down,之后处于该OSD上的PG会迁移至其它OSD。
3.OSD状态为out且up 这种状态一般会出现在新增OSD时,意味着该OSD守护进程正常,但是尚未加入集群。
4.OSD状态为out且down 在该状态下的OSD不在集群内,并且守护进程运行不正常,CRUSH不会再分配PG到该OSD上。
四、集群监控管理
集群整体运行状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # ceph -s 。。。health:集群运行状态,这里有一个警告,说明是有问题,意思是pg数大于pgp数,通常此数值相等。mon:Monitors运行状态。osd:OSDs运行状态。mgr:Managers运行状态。mds:Metadatas运行状态。pools:存储池与PGs的数量。objects:存储对象的数量。usage:存储的理论用量。pgs:PGs的运行状态$ ceph -w$ ceph health detail |
存储组件的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | pg状态~]$ ceph pg dump~]$ ceph pg statpool状态~]$ ceph osd pool stats~]$ ceph osd pool stats osd状态~]$ ceph osd stat~]$ ceph osd dump~]$ ceph osd tree~]$ ceph osd dfMonitor状态和查看仲裁状态~]$ ceph mon stat~]$ ceph mon dump~]$ ceph quorum_status |
集群空间用量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | ceph df--- RAW STORAGE ---CLASS SIZE AVAIL USED RAW USED %RAW USEDhdd 437 TiB 48 TiB 388 TiB 389 TiB 89.03ssd 19 TiB 16 TiB 3.0 TiB 3.2 TiB 16.59TOTAL 456 TiB 64 TiB 391 TiB 392 TiB 85.97--- POOLS ---POOL ID PGS STORED OBJECTS USED %USED MAX AVAILdevice_health_metrics 20 1 57 MiB 66 170 MiB 100.00 0 BCeph-rbd-Delete 25 32 5.9 TiB 1.54M 18 TiB 100.00 0 BCeph-rbd-Retain 26 32 524 GiB 310.21k 1.6 TiB 100.00 0 BCeph-rbd-PVE 27 128 19 TiB 5.47M 57 TiB 100.00 0 BCeph-Cache-Delete 28 32 555 GiB 193.44k 1.1 TiB 7.43 6.7 TiBCeph-Cache-Retain 29 32 26 GiB 497.38k 51 GiB 0.37 6.7 TiBCeph-Cache-PVE 30 32 739 GiB 192.00k 1.4 TiB 9.66 6.7 TiBCephfs-Data 31 1024 100 TiB 115.00M 312 TiB 100.00 0 BCephfs-Metadata 32 32 66 GiB 1.20M 198 GiB 1.41 4.5 TiBCephfs-Data-Cache 33 32 209 GiB 802.19k 420 GiB 2.95 6.7 TiB.rgw.root 35 4 1.3 KiB 4 512 KiB 100.00 0 Bdefault.rgw.log 38 256 3.4 KiB 207 4 MiB 100.00 0 Bdefault.rgw.control 39 256 0 B 8 0 B 0 0 Bdefault.rgw.meta 40 256 1.2 KiB 7 48 KiB 0 6.7 TiBdefault.rgw.buckets.index 41 256 141 KiB 11 282 KiB 0 6.7 TiB~]$ ceph df detail |
五、集群配置管理(临时和全局,服务平滑重启)
有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用tell和daemon子命令来完成此需求。
1 2 3 4 5 6 | 查看运行配置命令格式:# ceph daemon {daemon-type}.{id} config show 命令举例:# ceph daemon osd.0 config show |
tell子命令格式
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。
1 2 3 4 5 6 7 8 | 命令格式:# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]命令举例:# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1•daemon-type:为要操作的对象类型如osd、mon、mds等。•daemon id:该对象的名称,osd通常为0、1等,mon为ceph -s显示的名称,这里可以输入*表示全部。•injectargs:表示参数注入,后面必须跟一个参数,也可以跟多个 |
daemon子命令
使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
1 2 3 4 | 命令格式:# ceph daemon {daemon-type}.{id} config set {name}={value}命令举例:# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false |
六、RBD基础
1、查看集群中的pool
1 | ceph osd lspools |
2、获取 pg 个数
1 2 | ceph osd pool get Cephfs-Data pg_numpg_num: 1024 |
3、获取 pgp 个数
1 2 | ceph osd pool get Cephfs-Data pgp_numpgp_num: 1024 |
4、获取副本数
1 2 | ceph osd pool get Ceph-rbd-PVE sizesize: 3 |
5、获取使用模型
1 2 | ceph osd pool get Ceph-rbd-PVE crush_rulecrush_rule: new_hdd_rule3 |
6、设置副本数
1 | ceph osd pool set ceph-demo size 2 |
7、设置pg数量
1 | ceph osd pool set ceph-demo pg_num 128 |
8、设置 pgp 数量
1 | ceph osd pool set ceph-demo pgp_num 128 |
9、创建 rbd 块设备
查看块设备
1 2 3 4 5 6 7 8 9 10 | rbd -p Ceph-rbd-PVE lsbase-119-disk-2base-119-disk-3base-122-disk-0base-122-disk-1base-136-disk-0base-143-disk-2base-143-disk-3base-146-disk-0base-146-disk-1 |
创建块设备
1 2 3 4 5 6 7 8 9 10 | # 创建 块设备方式一# rbd create -p ceph-demo --image rbd-demo.img --size 10G# 创建 块设备方式二# rbd create ceph-demo/rbd-demo2.img --size 10G# 查看 块设备# rbd -p ceph-demo lsrbd-demo.imgrbd-demo2.img |
查看块设备信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | rbd info Ceph-rbd-PVE/vm-180-disk-1rbd image 'vm-180-disk-1': size 200 GiB in 51200 objects order 22 (4 MiB objects) snapshot_count: 0 id: c31ee76b8b4567 block_name_prefix: rbd_data.c31ee76b8b4567 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Tue Jul 26 10:08:51 2022 access_timestamp: Tue Jul 26 10:08:51 2022 modify_timestamp: Tue Jul 26 10:08:51 2022 |
删除块设备
1 | rbd rm -p ceph-demo --image rbd-demo2.img |
数据存储流程
1. 文件对象;
2. 切割成大小为4M的 object 对象;
3. object 对象通过CRUSH 算法映射到 PG;
4. PG 通过CRUSH算法映射到OSD;
基本使用
创建 pool 池:ceph osd pool create ceph-demo 64 64
在 Pool 池中创建 rbd 对象:
rbd create -p ceph-demo --image rbd-demo.img --size 10G
使用内核map 挂载rbd对象:rbd map ceph-demo/rbd-demo.img
格式化块设备:mkfs.ext4 /dev/rbd0
挂载块设备:mount /dev/rbd0 /mnt/rbd-demo/
设置 pool 池信息:ceph osd pool set ceph-demo size 2
扩容 rbd 块设备:rbd resize ceph-demo/rbd-demo.img --size 20G
扩容挂载后文件系统:resize2fs /dev/rbd0
删除块设备:rbd rm -p ceph-demo --image rbd-demo2.img
信息查看
查看pool池中的rbd块设备:rbd -p ceph-demo ls
查看块设备详细信息方式一:rbd info ceph-demo/rbd-demo2.img、
查看块设备详细信息方式二:rbd -p ceph-demo info rbd-demo.img
查看本机rbd设备列表:rbd device list
查看块设备对应的所有 objects :rados -p ceph-demo ls|grep rbd_data.12e14e0cad6b
单个object对象映射的PG及OSD信息/大小等:ceph osd map ceph-demo bd_data.12e14e0cad6b.000000000000042f
七、集群操作
1 2 3 4 5 6 7 8 | 1、启动所有守护进程# systemctl start ceph.target2、按类型启动守护进程# systemctl start ceph-mgr.target# systemctl start ceph-osd@id# systemctl start ceph-mon.target# systemctl start ceph-mds.target# systemctl start ceph-radosgw.target<br><br>ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。(把集群的一些指标暴露给外界使用,比如用于监控) |
添加和删除osd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 添加1、格式化磁盘ceph-volume lvm zap /dev/sd2、进入到ceph-deploy执行目录/my-cluster,添加OSD# ceph-deploy osd create --data /dev/sd删除1、调整osd的crush weight为 0ceph osd crush reweight osd.<ID> 0.02、将osd进程stopsystemctl stop ceph-osd@<ID>3、将osd设置outceph osd out <ID>4、立即执行删除OSD中数据ceph osd purge osd.<ID> --yes-i-really-mean-it5、卸载磁盘umount /var/lib/ceph/osd/ceph-? |
扩容pg
1 2 3 4 | ceph osd pool set {pool-name} pg_num 128ceph osd pool set {pool-name} pgp_num 128 注:1、扩容大小取跟它接近的2的N次方 2、在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常rebalancing。 |
Pool操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | 列出存储池ceph osd lspools20 device_health_metrics25 Ceph-rbd-Delete26 Ceph-rbd-Retain27 Ceph-rbd-PVE28 Ceph-Cache-Delete29 Ceph-Cache-Retain30 Ceph-Cache-PVE31 Cephfs-Data32 Cephfs-Metadata33 Cephfs-Data-Cache35 .rgw.root38 default.rgw.log39 default.rgw.control40 default.rgw.meta41 default.rgw.buckets.index创建存储池命令格式:# ceph osd pool create {pool-name} {pg-num} [{pgp-num}]命令举例:# ceph osd pool create rbd 32 32设置存储池配额命令格式:# ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]命令举例:# ceph osd pool set-quota rbd max_objects 10000删除存储池ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]重命名存储池ceph osd pool rename {current-pool-name} {new-pool-name}查看存储池统计信息rados df给存储池做快照ceph osd pool mksnap {pool-name} {snap-name}删除存储池的快照ceph osd pool rmsnap {pool-name} {snap-name}获取存储池选项值ceph osd pool get {pool-name} {key}调整存储池选项值ceph osd pool set {pool-name} {key} {value}size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_min_interval 。scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_max_interval 。deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配置文件里的 osd_deep_scrub_interval 。获取对象副本数ceph osd dump | grep 'replicated size' |
用户管理
Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | 查看用户信息查看所有用户信息# ceph auth list获取所有用户的key与权限相关信息# ceph auth get client.admin如果只需要某个用户的key信息,可以使用pring-key子命令# ceph auth print-key client.admin 添加用户# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'# ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'# ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring# ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key修改用户权限# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'# ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'# ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'# ceph auth caps client.ringo mon ' ' osd ' '删除用户# ceph auth del {TYPE}.{ID}其中, {TYPE} 是 client,osd,mon 或 mds 的其中一种。{ID} 是用户的名字或守护进程的 ID 。 |
增加和删除Monitor
一个集群可以只有一个 monitor,推荐生产环境至少部署 3 个。Ceph 使用 Paxos 算法的一个变种对各种 map 、以及其它对集群来说至关重要的信息达成共识。建议(但不是强制)部署奇数个 monitor 。Ceph 需要 mon 中的大多数在运行并能够互相通信,比如单个 mon,或 2 个中的 2 个,3 个中的 2 个,4 个中的 3 个等。初始部署时,建议部署 3 个 monitor。后续如果要增加,请一次增加 2 个。
1 2 3 4 5 6 7 | 新增一个monitor# ceph-deploy mon create $hostname注意:执行ceph-deploy之前要进入之前安装时候配置的目录。/my-cluster删除monitor# ceph-deploy mon destroy $hostname注意: 确保你删除某个 Mon 后,其余 Mon 仍能达成一致。如果不可能,删除它之前可能需要先增加一个。 |
https://www.jianshu.com/p/dd572541df2e ceph优化
https://mp.weixin.qq.com/s/X59UFaP1UnOb5h21z1aFdA
http://docs.ceph.org.cn/ 中文社区
八、ceph的版本
https://docs.ceph.com/en/latest/releases/general/ 官网版本介绍
第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00 ?),我们制定了新策略。
-
x.0.z - 开发版(给早期测试者和勇士们)
-
x.1.z - 候选版(用于测试集群、高手们)
-
x.2.z - 稳定、修正版(给用户们)
x 将从 9 算起,它代表 Infernalis ( I 是第九个字母),这样我们第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。
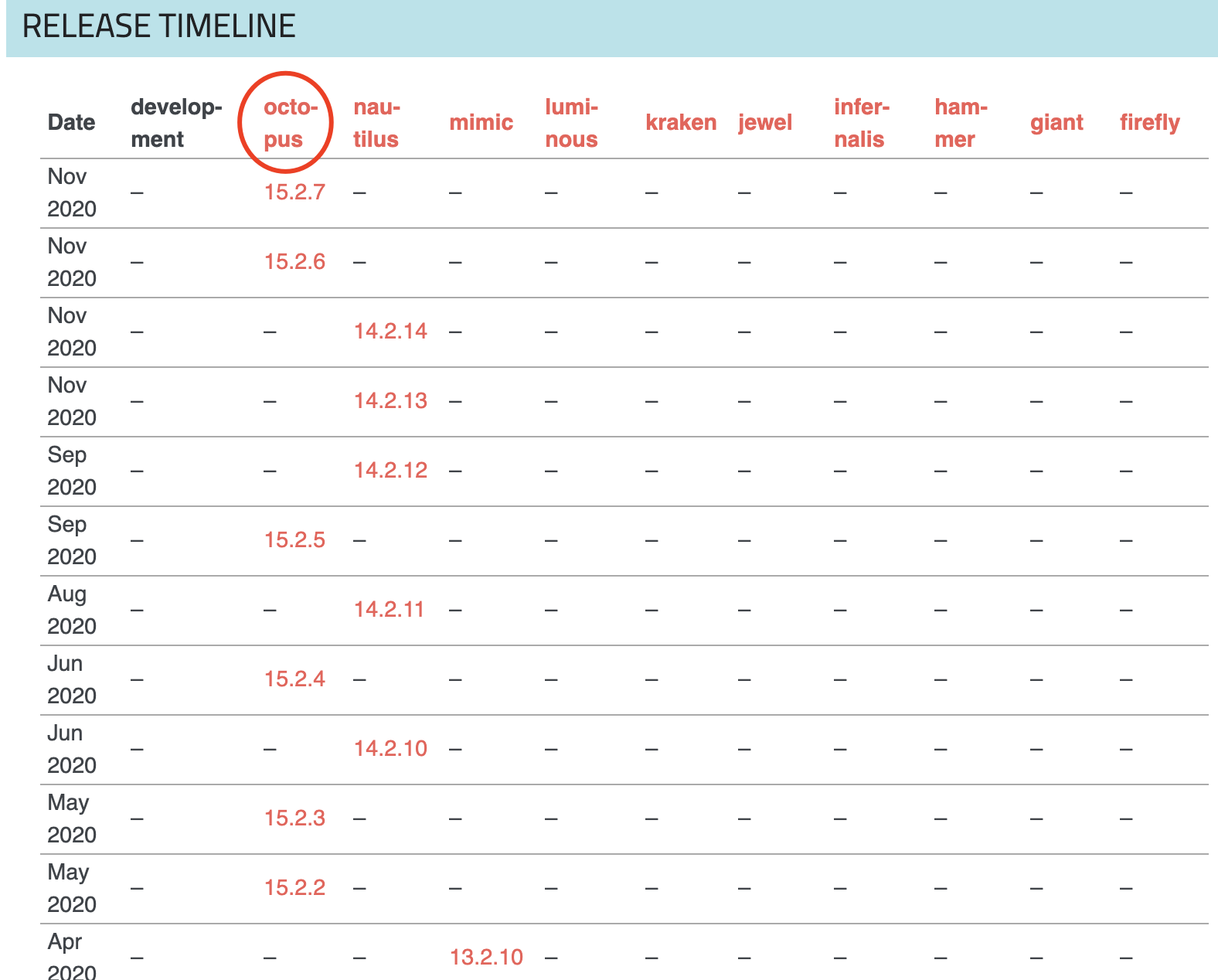
https://blog.csdn.net/qq_37242520/article/details/108101126 ceph的dashboard
https://www.bookstack.cn/read/ceph-handbook/Operation-operate_cluster.md ceph运维手册
https://yq.aliyun.com/articles/606731 ceph调优



