三剑客之sed
一、sed 写法
sed [选项] ‘范围 动作’ 文件

一个简单的 sed 命令包含三个主要部分:参数、范围、操作。要操作的文件,可以直接挂在命令行的最后。除了命令行,sed也可以通过-f参数指定一个 sed脚本,这个属于高级用法,不做过多描述。
参数选项:
--quiet
--silent
-i :
所有改动将在原文件上执行。你的输出将覆盖原文件,
非常危险,一定要注意。
地址范围:
(1)没有地址:默认对全文进行处理。
(2)单地址:
1 2 3 | X:指定的行/pattern/:被匹配到的每一行 |
(3)地址范围:
1 2 3 4 5 6 7 | X1,X2 : 选取第 X1 行到 X2 行之间的行,如从第二行到最后一行:2,$X1,+X2 : 选取第 X1 行之后的 X2 个行/pat1/,/pat2/ : 选取 pat1 第一次匹配到的行到 pat2 第一次匹配到的行之间的行X,/pat1/ : 选取 X 第一次匹配到的行到 pat1 第一次匹配到的行 |
(4)X1~X2 : 步长
1 2 3 | 1~2 : 从1开始,步进为2(奇数行)2~2 : 从2开始,步进为2(偶数行) |
(5)下一行
1 | n 匹配下一行 |
范围的选择还可以使用正则匹配。
1 2 | /sys/,+3 选择出现sys字样的行,以及后面的三行。/\^sys/,/mem/ 选择以sys开头的行,和出现mem字样行之间的数据。 |
为了直观,下面的命令一一对应上面的介绍,范围和操作之间是可以有空格的。
1 2 3 4 5 6 7 8 9 | sed -n '5p' filesed -n '2,5 p' filesed -n '1~2 p' filesed -n '2~2 p' filesed -n '2,+3p' filesed -n '2,$ p' filesed -n '/sys/,+3 p' filesed -n '/^sys/,/mem/p' file |
动作:
d : 删除模式空间匹配的行,并立即启用下一轮循环 p : 打印当前模式空间内容,追加到默认输出之后 a [\]text : 在指定行后面追加文本。支持使用\n 实现多行追加 i [\]text : 在行前面插入文本 c [\]text : 替换行为单行或多行文本 w : 保存模式匹配的行至指定文件 r : 读取指定文件的文本至模式空间中匹配到的行后 = : 为模式空间中的行打印行号 ! : 模式空间中匹配行取反处理
s/X/X/g : 查找替换, 支持使用其它分隔符,s@@@ ,s### y/XX/XX/ : 检索所有匹配的项,替换为对应的字符
最常用的操作就是p,意思就是打印。比如,以下两个命令就是等同的:
1 2 | cat filesed -n 'p' file |
除了打印,还有以下操作,我们来说常用的。
1 2 | d 对匹配内容进行删除。这个时候就要去掉-n参数了,想想为什么。w 将匹配内容写入到其他地方。 |
1 2 3 | sed -n '2,5 p' filesed '2,5 d' filesed -n '2,5 w output.txt' file |
我们来看一下sed命令都能干些啥,上点命令体验一下。
删除所有#开头的行和空行。
1 2 3 4 5 6 | sed -e 's/#.*//' -e '/^$/ d' file (-e:多次操作)sed -ri.bak '/^[ \t]*#|^[ \t]*$/d' /etc/ntp.conf^[ \t]*#删除以#开头的行,^[ \t]*$删除空行,\t是tab键,[]是可选择删除空行和注释行,并做备份 |
最常用的,比如下面这个。
1 | sed -n '2p' /etc/group 表示打印group文件中的第二行。1、参数部分 比如 -n |
那么我想一次执行多个命令,还不想写sed脚本文件怎么办?那就需要加-e参数。sed的操作单元是行。
匹配关键字的下一行
写法:sed -n '/关键字/{n;p}' filename
1 2 3 | sed -n '/zjz/{n;p}' test.txt host => "127.0.0.1:6379" host => "127.0.0.1:9300" |
匹配到关键字的下一行并进行替换
写法:sed -i '/查询匹配的内容/{n;s/下一行内要被替换的内容/替换内容/;}' filename
1 2 3 4 5 | sed -i '/zjz/{n;s/127.0.0.1/127.1.1.1/;}' test.txtsed -n '/zjz/{n;p}' test.txt host => "127.1.1.1:6379" host => "127.1.1.1:9300" |
匹配最后一行,并去除最后一行中的乱码数据
filename文件中最后一行是乱码占用大量空间,使用hexdump可以看到乱码对应的16进制字符为x20。
1 | sed -i '${s/\x20//g}' filename |
替换模式(s、c)
以上是sed命令的常用匹配模式,但它还有一个强大的替换模式,意思就是查找替换其中的某些值,并输出结果。使用替换模式很少使用-n参数。
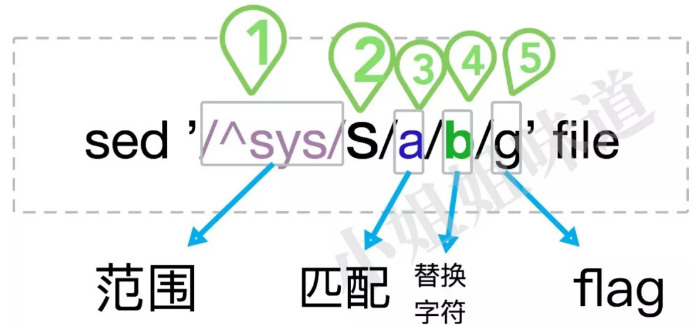
替换模式的参数有点多,但第一部分和第五部分都是可以省略的。替换后会将整个文本输出出来。前半部分用来匹配一些范围,而后半部分执行替换的动作。
范围
这个范围和上面的范围语法类似。看下面的例子。
1 2 | /sys/,+3 选择出现sys字样的行,以及后面的三行。/\^sys/,/mem/ 选择以sys开头的行,和出现mem字样行之间的数据。 |
具体命令为:
1 2 | sed '/sys/,+3 s/a/b/g' filesed '/^sys/,/mem/s/a/b/g' file |
命令
这里的命令是指s。也就是substitute替代的意思。
查找匹配
查找部分会找到要被替换的字符串。这部分可以接受纯粹的字符串,也可以接受正则表达式。
1 2 | a 查找范围行中的字符串a。[a,b,c] 从范围行里查找字符串a或者b或者c。 |
命令类似:
1 2 | sed 's/a/b/g' filesed 's/[a,b,c]/<&>/g' file#这个命令我们下面解释 |
s替换
常用的就是精确替换,比如把a替换成b。但也有高级功能。和java或者python的正则api类似,sed的替换同样有Matched Pattern的含义,同样可以得到Group,不深究。常用的替位符,就是&。&号,再重复一遍。当它用在替换字符串中的时候,代表的是原始的查找匹配数据。
1 2 | [&] 表明将查找到的数据使用[]包围起来。“&” 表明将查找的数据使用””包围起来。 |
1 | sed 's/.*/"&"/' file |
c取代(替换整行)
将第二行的内容替换 hehe
1 2 3 4 | # sed "2 c hehe" test.txttom likes to play footballhehefrank likes to drink beer |
仅仅替换有 tom 的行
1 2 3 4 | # sed "/tom/c cat" test.txtcatkevin likes to eat cabbagefrank likes to drink beer |
flag 参数
这些参数可以单个使用,也可以使用多个,仅介绍最常用的。
1 2 3 4 5 | g 默认只匹配行中第一次出现的内容,加上g,就可以全文替换了。常用。p 当使用了-n参数,p将仅输出匹配行内容。w 和上面的w模式类似,但是它仅仅输出有变换的行。i 这个参数比较重要,表示忽略大小写。e 表示将输出的每一行,执行一个命令。不建议使用,可以使用xargs配合完成这种功能。 |
1 2 | sed -n 's/a/b/gipw output.txt' filesed 's/^/ls -la/e' file |
正则表达式
可以看到,正则表达式在命令行中无处不在。以下,紧做简要说明。
^ 行首
$ 行尾
. 单个字符
* 0个或者多个匹配
1个或者多个匹配
? 0个或者1个匹配
{m} 前面的匹配重复m次
{m,n} 前面的匹配重复m到n次
\ 转义字符
[0-9] 匹配括号中的任何一个字符,or的作用
| or,或者
\b 匹配一个单词。比如\blucky\b 只匹配单词lucky
参数i
上面已经简单介绍了参数i,它的作用是让操作在原文件执行。无论你执行了啥,原始文件都将会被覆盖。这是非常危险的。通过加入一个参数,可以将原文件做个备份。
1 | sed -i.bak 's/a/b/' file |
以上命令会对原file文件生效,并生成一个file.bak文件。强烈建议使用i参数同时指定bak文件。
结合使用
输出长度不小于50个字符的行
1 | sed -n '/^.{50}/p' |
统计文件中有每个单词出现了多少次
1 | sed 's/ /\n/g' file | sort | uniq -c<br><br>'s/ /\n/g':以空格区分一个单词,然后一行多个单词全部换行,sort排序,uniq -c 是唯一显示,同时文本空格行数也能统计出来 |
查找目录中的 py 文件,删掉所有行级注释
1 | find ./ -name "*.py" | xargs sed -i.bak '/^[ ]*#/d' |
查看第 5-7 行和 10-13 行
1 | sed -n -e '5,7p' -e '10,13p' file |
删除文本中最后一行的逗号
1 2 3 | a=`sed -n '$p' filename`sed -i "/$a/ s/\(.*\),/\1/g" filename |
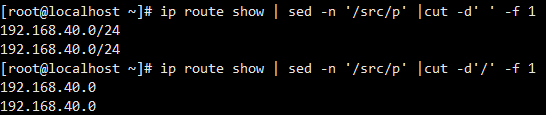
仅输出 ip 地址
1 2 3 4 5 6 7 8 9 10 11 12 | ip route show | sed -n '/src/p' | sed -e 's/ */ /g' | cut -d' ' -f9[root@localhost ~]# ip route show | sed -n '/src/p'192.168.40.0/24 dev ens33 proto kernel scope link src 192.168.40.152 metric 100 192.168.40.0/24 dev ens37 proto kernel scope link src 192.168.40.172 metric 101 [root@localhost ~]# ip route show | sed -n '/src/p' | sed 's/ .*/ /g'192.168.40.0/24 192.168.40.0/24 # ip route show | sed -n '/src/p' |cut -d' ' -f 9192.168.40.152192.168.40.172 cut -d 和 -f 的组合用法,-d删除跟分隔符,-f 指第几列,就是域 |
一个数G的文件,只想处理前30中的某些字符,使用行数范围后,发现,sed依然会把剩余的行数进行轮询一遍,只不过不执行操作了。
时间非常长,如何让其在处理完相关的行数后就正常退出呢?
执行完操作部分就退出:q
1 2 3 4 5 | sed -n '1, 30 p; 31 q' file_namesed -n '/something/ {p; q}' file_namesed -n '1p' filesed -n '1p;1q' file |
他们的作用一样,都是获取文件的第一行。但是第一条命令会读取整个文件,而第二条命令只读取第一行。当文件很大的时候,仅仅是这样一条命令不一样就会造成巨大的效率差异。
& 是反向引用
在配置文件中所有不以#开头的行前面添加*符号,注意:以#开头的行不添加
^[^#] 对以#号开头的行取反就是非#开头的行,& 是反向引用代表前面的行,然后加*
1 2 3 | sed -i 's/^[^#]/*&/g' nginx.confecho "50d" | sed 's/[^0-9]*//g' |
带有变量的替换
写法一,将外部单引号用双引号替代
1 2 3 4 5 6 7 8 9 10 11 | sed "/key/{n;s/${beitihuan}/${tihuan}/;}" test.txtinput { redis { zjz host => "127.1.1.1:6379" key => "logstash:demo" data_type => "mysql2" codec => "json" type => "logstash-redis-demo" tags => ["logstashdemo"] } |
写法二,不修改外部单引号,将变量用单引号引起来
1 | sed '/key/{n;s/'${beitihuan}'/'${tihuan}'/;}' test.txt |
sed对软连文件进行操作(实测)
sed对软连文件进行操作,倘若不指定--follow-symlinks,则软连文件和原始文件会被拆分,原始文件不会被修改,而软连的文件会被修改,且变成一个独立文件。
1 | sed -i --follow-symlinks '/key/{n;s/'${beitihuan}'/'${tihuan}'/;}' redis.conf |
二、常见用法
测试文件(11 12 为空行)
1 2 3 4 5 6 7 8 9 10 11 12 13 | #cat -n test.file 1 1a 2 2b 3 3c 4 4d 5 5e 6 6f 7 7g 8 8h 9 9j 10 10k 11 12 |
打印基数行
1 2 3 4 5 6 | #sed -n '1~2 p' test.file1a3c5e7g9j |
打印1到3行
1 2 3 4 | sed -n '1,3 p' test.file1a2b3c |
打印带有字母a或带有字母c的行,「」表示可选,但必须带上-n,才能有输出
1 2 3 | #sed -n '/[ac]/ p' test.file 1a3c |
打印c到e的行/c/,/e/
1 2 3 4 | sed -n '/c/,/e/ p' test.file 3c4d5e |
在第3行前一行插入字符i
1 2 3 4 5 | sed '3 i zjz' test.file 1a2bzjz3c |
将每行第二个字符删除 -r支持正则
1 2 3 4 5 | #sed -r 's/(.)(.)/\1/' test.file 11a22b33c44d |
所有的空格被删掉。-r选项支持扩展正则表达式(相当于sed ‘s/^/\1/’)另一种方式sed ‘/.//2’ file ”
把所有a替换为A,-y选项是把前面匹配的项全部对应替换为后面的字符
1 2 3 | sed 'y/a/A/' test.file 1 A2 b |
进阶用法
将1行放到3行后面
1 2 3 4 5 6 | #sed ' 1h;3G ' test.file 1 a2 b3 c1 a4 d |
h:将模式空间的内容覆盖保持空间中
G:将保持空间内容追加到模式空间中
在每行后面添加1个空行,保持空间默认有一个空白行
1 2 3 4 5 6 7 8 9 10 | sed ' 1,$G ' test.file 1 a2 b3 c4 d5 e |
把1到4行放在5行后面
1 2 3 4 5 6 7 8 9 10 | sed ' 1h;2,4H;5G;1,4d' test.file 5 e1 a2 b3 c4 d6 f7 g8 h9 j |
1h:覆盖掉保持空间中的空白行
1,4d:删除最前面的4行
将第3行替换为第1行内容
1 2 3 4 5 6 | sed -n '1h;3x;p' test.file 1 a2 b1 a4 d5 e |
递增输出sed 'H;g'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | $ seq 9 | sed 'H;g'112123123412345 |
常见用法
1、sed 命令 -n 选项的用法
1 2 3 | sed -n '1p' /etc/passwd (显示passwd文件的第一行,不加n则会全部显示,p是打印)sed -n '1,4d' /etc/passwd (d删除,删除passwd的1-4行内容,并显示删除后的内容)sed -n '1p;5p' /etc/passwd (显示第一行和第五行) |
2、sed中&符号
1 | sed -ri 's/.*swap.*/#&/' /etc/fstab &符号就是代表前面.*匹配的到字符 |
3、sed "" 和\1和\2...的组合使用
1 | sed '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab |
将aabbccddeeffgghh替换为aa:bb:cc:dd
sed -ri 's/^.*$/\1:\2:\3:\4/'
第一个表示匹配任意2个字符,并且对应后面的\1
对于字符串aabbccddeeffgghh而言,就是aa这2个字符
同理,第二匹配bb,对应\2;第三匹配cc,对应\3;第四匹配dd,对应\4
剩下的eeffgghh匹配 .*$,其中.*表示匹配任意个字符,$匹配到末尾,这些字符串被抛弃
4、sed工具p输出操作
1 2 3 4 5 | sed -n '/local$/p' 1.txt 输出以local结尾的行sed -n 'p;n' 1.txt 输出基数行sed -n 'n;p' 1.txt 输出偶数行sed -n '5,$p' 1.txt 输出从第五行到最后一行sed -n '$=' 1.txt 输出文本的总行数 |
5、sed工具的d输出操作(不要加-n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | sed '3,5d' 1.txt 删除3-5行sed '/init/d' 1.txt 删除包含init所有的行sed '/init/d;/bin/d' 1.txt 删除所有包含init和bin的行sed '/init/!d' 1.txt 删除不包含init的行sed '$d' 1.txt 删除最后一行sed '/^$/d' 1.txt 删除文件中所有的空行超大数据量文本,sed删除不合规数据#!/bin/bashfor i in `cat 00000.txt`doecho $ised -in "/`echo $i`/d" output.txtdone |
6、sed工具的s替换操作
1 2 3 4 5 6 7 8 | sed 's/ll/AA/' 1.txt 将所有行的第一个ll替换为AAsed 's/ll/AA/g' 1.txt 将所有行的ll替换为AAsed '3s/script/SCRIPT/2' 1.txt 将第三行内的第二个script替换为SCRIPTsed 's/init//g' 1.txt 删除所有的init字符sed 's/script|init\e//g' 删除所有的script init e 的字符sed '3,5s/^#//' 1.txt 解除3到5行的#注释sed '6,7s/^/#/' 1.txt 给6到7行添加注释sed -ri '/^SELINUX=/cSELINUX=disabled' /etc/selinux/config |
7、sed的扩展
1 2 3 4 | sed 's/.//2;s/.$//' 1.txt 删除每行的第二个字符和最后一个字符sed -r 's/^(.)(.)(.)/\2\1\3/' 把每行的第一个字符和第二个字符互换sed -r 's/[0-9]//g;s/^( )+//' 1.txt 把文件中所有数字,和首行空格删除;sed 's/[A-Z]/(&)/g' 1.txt 把文件中每个大写字母添加括号 |
8、删除空白行和注释行
1 2 3 4 5 6 | sed -ri.bak '/^[ \t]*#|^[ \t]*$/d' /etc/ntp.conf 删除前先备份整个文件###grep方式grep -Ev "^#|^$" configSELINUX=disabledSELINUXTYPE=targeted |



