prometheus告警
https://awesome-prometheus-alerts.grep.to/ 很全的告警模板

安装配置kube-state-metrics组件
kube-state-metrics是什么?
kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?我有多少job在运行中。
安装kube-state-metrics组件
1)创建sa,并对sa授权
在k8s的master1节点生成一个kube-state-metrics-rbac.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | cat > kube-state-metrics-rbac.yaml <<EOF---apiVersion: v1kind: ServiceAccountmetadata: name: kube-state-metrics namespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: kube-state-metricsrules:- apiGroups: [""] resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"] verbs: ["list", "watch"]- apiGroups: ["extensions"] resources: ["daemonsets", "deployments", "replicasets"] verbs: ["list", "watch"]- apiGroups: ["apps"] resources: ["statefulsets"] verbs: ["list", "watch"]- apiGroups: ["batch"] resources: ["cronjobs", "jobs"] verbs: ["list", "watch"]- apiGroups: ["autoscaling"] resources: ["horizontalpodautoscalers"] verbs: ["list", "watch"]---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: kube-state-metricsroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metricssubjects:- kind: ServiceAccount name: kube-state-metrics namespace: kube-systemEOF |
通过kubectl apply更新yaml文件
kubectl apply -f kube-state-metrics-rbac.yaml
2)安装kube-state-metrics组件
在k8s的master1节点生成一个kube-state-metrics-deploy.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | cat > kube-state-metrics-deploy.yaml <<EOFapiVersion: apps/v1kind: Deploymentmetadata: name: kube-state-metrics namespace: kube-systemspec: replicas: 1 selector: matchLabels: app: kube-state-metrics template: metadata: labels: app: kube-state-metrics spec: serviceAccountName: kube-state-metrics containers: - name: kube-state-metrics# image: gcr.io/google_containers/kube-state-metrics-amd64:v1.3.1 image: quay.io/coreos/kube-state-metrics:v1.9.0 ports: - containerPort: 8080EOF |
通过kubectl apply更新yaml文件
kubectl apply -f kube-state-metrics-deploy.yaml
查看kube-state-metrics是否部署成功
kubectl get pods -n kube-system
显示如下,看到pod处于running状态,说明部署成功
1 | kube-state-metrics-79c9686b96-4njrs 1/1 Running 0 76s |
3)创建service
在8s的master1节点生成一个kube-state-metrics-svc.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | cat >kube-state-metrics-svc.yaml <<EOFapiVersion: v1kind: Servicemetadata: annotations: prometheus.io/scrape: 'true' name: kube-state-metrics namespace: kube-system labels: app: kube-state-metricsspec: ports: - name: kube-state-metrics port: 8080 protocol: TCP selector: app: kube-state-metricsEOF |
通过kubectl apply更新yaml
kubectl apply -f kube-state-metrics-svc.yaml
查看service是否创建成功
kubectl get svc -n kube-system | grep kube-state-metrics
显示如下,说明创建成功
1 | kube-state-metrics ClusterIP 10.105.53.102 <none> 8080/TCP |
在grafana web界面导入Kubernetes Cluster (Prometheus)-1577674936972.json,出现如下页面
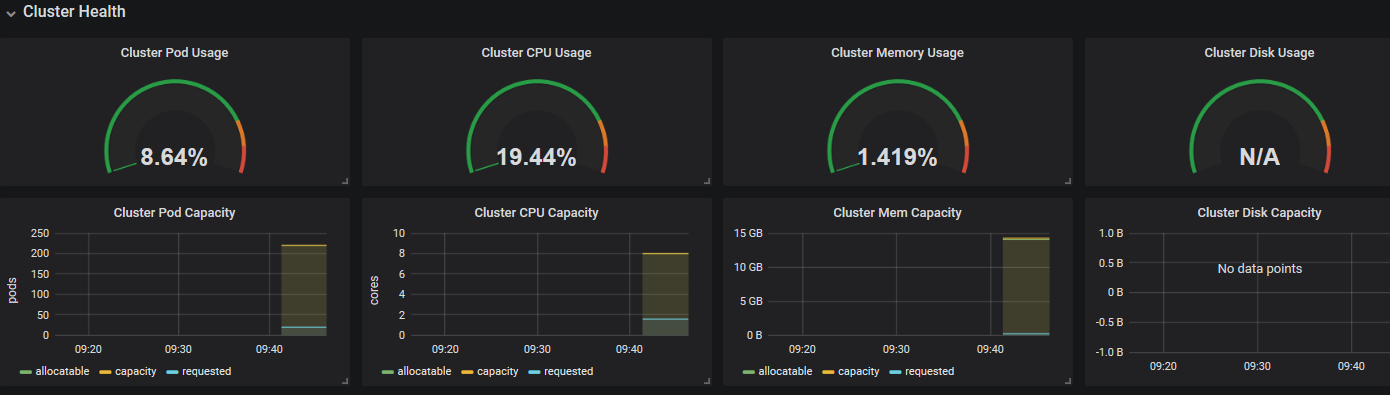
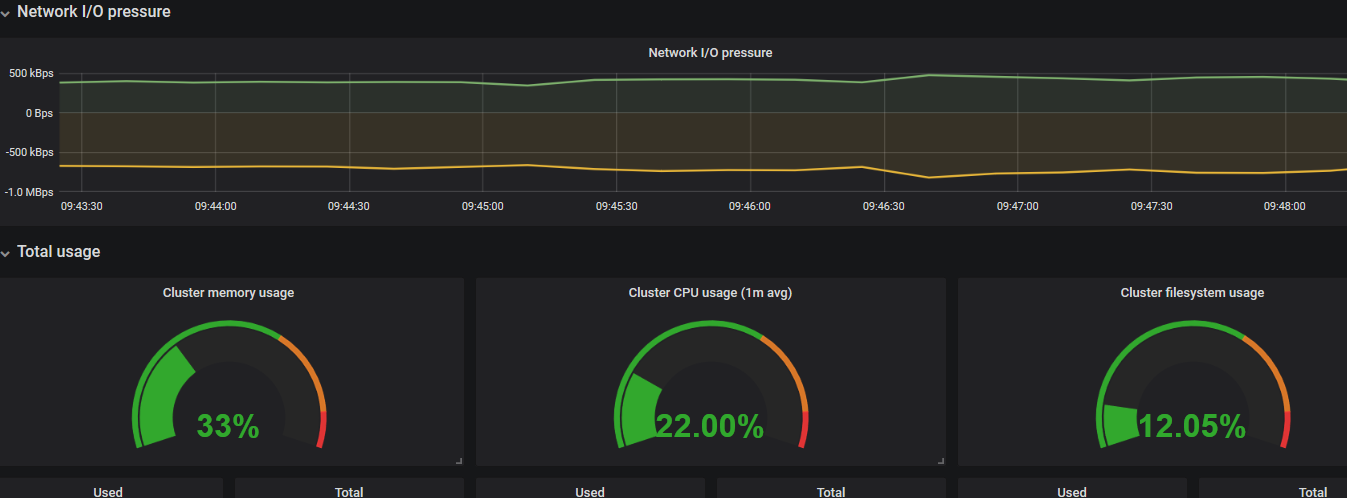
在grafana web界面导入Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json,出现如下页面
Kubernetes Cluster (Prometheus)-1577674936972.json和Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json文件在百度网盘,地址如下:
链接:https://pan.baidu.com/s/1QAMqT8scsXx-lzEPI6MPgA 提取码:i4yd
安装和配置Alertmanager-发送报警到qq邮箱
在k8s的master1节点创建alertmanager-cm.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | cat >alertmanager-cm.yaml <<EOFkind: ConfigMapapiVersion: v1metadata: name: alertmanager namespace: monitor-sadata: alertmanager.yml: |- global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: '15011572657@163.com' smtp_auth_username: '15011572657' smtp_auth_password: 'BDBPRMLNZGKWRFJP' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 10m receiver: default-receiver receivers: - name: 'default-receiver' email_configs: - to: '1980570647@qq.com' send_resolved: trueEOF |
通过kubectl apply 更新文件
kubectl apply -f alertmanager-cm.yaml
alertmanager配置文件解释说明:
smtp_smarthost: 'smtp.163.com:25'
#用于发送邮件的邮箱的SMTP服务器地址+端口
smtp_from: '15011572657@163.com'
#这是指定从哪个邮箱发送报警smtp_auth_username: '15011572657'
#这是发送邮箱的认证用户,不是邮箱名
smtp_auth_password: 'BDBPRMLNZGKWRFJP'
#这是发送邮箱的授权码而不是登录密码
email_configs:
- to: '1980570647@qq.com'
#to后面指定发送到哪个邮箱,我发送到我的qq邮箱,大家需要写自己的邮箱地址,不应该跟smtp_from的邮箱名字重复
在k8s的master1节点重新生成一个prometheus-cfg.yaml文件
cat prometheus-cfg.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 | kind: ConfigMapapiVersion: v1metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sadata: prometheus.yml: | rule_files: - /etc/prometheus/rules.yml alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: kubernetes-pods kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name - job_name: 'kubernetes-schedule' scrape_interval: 5s static_configs: - targets: ['192.168.0.6:10251'] - job_name: 'kubernetes-controller-manager' scrape_interval: 5s static_configs: - targets: ['192.168.0.6:10252'] - job_name: 'kubernetes-kube-proxy' scrape_interval: 5s static_configs: - targets: ['192.168.0.6:10249','192.168.0.56:10249'] - job_name: 'kubernetes-etcd' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key scrape_interval: 5s static_configs: - targets: ['192.168.0.6:2379'] rules.yml: | groups: - name: example rules: - alert: kube-proxy的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: kube-proxy的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: scheduler的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: scheduler的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: controller-manager的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: controller-manager的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: apiserver的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: apiserver的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: etcd的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: etcd的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: kube-state-metrics的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: coredns的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: coredns的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: kube-proxy打开句柄数>600 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kube-proxy打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>600 expr: process_open_fds{job=~"kubernetes-schedule"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-schedule"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>600 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>600 expr: process_open_fds{job=~"kubernetes-apiserver"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>600 expr: process_open_fds{job=~"kubernetes-etcd"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-etcd"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 600 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 1000 for: 2s labels: severity: critical annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000" value: "{{ $value }}" - alert: kube-proxy expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: scheduler expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-controller-manager expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-apiserver expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-etcd expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kube-dns expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: HttpRequestsAvg expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000" value: "{{ $value }}" threshold: "1000" - alert: Pod_restarts expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0 for: 2s labels: severity: warnning annotations: description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的" value: "{{ $value }}" threshold: "0" - alert: Pod_waiting expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中" value: "{{ $value }}" threshold: "1" - alert: Pod_terminated expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除" value: "{{ $value }}" threshold: "1" - alert: Etcd_leader expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader" value: "{{ $value }}" threshold: "0" - alert: Etcd_leader_changes expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变" value: "{{ $value }}" threshold: "0" - alert: Etcd_failed expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败" value: "{{ $value }}" threshold: "0" - alert: Etcd_db_total_size expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G" value: "{{ $value }}" threshold: "10G" - alert: Endpoint_ready expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用" value: "{{ $value }}" threshold: "1" - name: 物理节点状态-监控告警 rules: - alert: 物理节点cpu使用率 expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90 for: 2s labels: severity: ccritical annotations: summary: "{{ $labels.instance }}cpu使用率过高" description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}内存使用率过高" description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: InstanceDown expr: up == 0 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}: 服务器宕机" description: "{{ $labels.instance }}: 服务器延时超过2分钟" - alert: 物理节点磁盘的IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 入网流量带宽 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: 出网流量带宽 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!" description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$valu |
注意:通过上面命令生成的promtheus-cfg.yaml文件会有一些问题,2这种变量在文件里没有,需要在k8s的master1节点打开promtheus-cfg.yaml文件,手动把2这种变量写进文件里,promtheus-cfg.yaml文件需要手动修改部分如下:
1 2 3 4 5 | 22行的replacement: ':9100'变成replacement: '${1}:9100'42行的replacement: /api/v1/nodes//proxy/metrics/cadvisor变成 replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor73行的replacement: 变成replacement: $1:$2103行的replacement: 变成replacement: $1:$2 |
通过kubectl apply 更新文件
kubectl apply -f prometheus-cfg.yaml
在k8s的master1节点重新生成一个prometheus-deploy.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | cat >prometheus-deploy.yaml <<EOF---apiVersion: apps/v1kind: Deploymentmetadata: name: prometheus-server namespace: monitor-sa labels: app: prometheusspec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: nodeName: node1 serviceAccountName: monitor containers: - name: prometheus image: prom/prometheus:v2.2.1 imagePullPolicy: IfNotPresent command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-lifecycle" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume - name: k8s-certs mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ - name: alertmanager image: prom/alertmanager:v0.14.0 imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/alertmanager.yml" - "--log.level=debug" ports: - containerPort: 9093 protocol: TCP name: alertmanager volumeMounts: - name: alertmanager-config mountPath: /etc/alertmanager - name: alertmanager-storage mountPath: /alertmanager - name: localtime mountPath: /etc/localtime volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory - name: k8s-certs secret: secretName: etcd-certs - name: alertmanager-config configMap: name: alertmanager - name: alertmanager-storage hostPath: path: /data/alertmanager type: DirectoryOrCreate - name: localtime hostPath: path: /usr/share/zoneinfo/Asia/ShanghaiEOF |
生成一个etcd-certs,这个在部署prometheus需要
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
通过kubectl apply更新yaml文件
kubectl apply -f prometheus-deploy.yaml
#查看prometheus是否部署成功
kubectl get pods -n monitor-sa | grep prometheus
显示如下,可看到pod状态是running,说明prometheus部署成功
1 2 | NAME READY STATUS RESTARTS AGEprometheus-server-85dbc6c7f7-nsg94 1/1 Running 0 6m7 |
在k8s的master1节点重新生成一个alertmanager-svc.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | cat >alertmanager-svc.yaml <<EOF---apiVersion: v1kind: Servicemetadata: labels: name: prometheus kubernetes.io/cluster-service: 'true' name: alertmanager namespace: monitor-saspec: ports: - name: alertmanager nodePort: 30066 port: 9093 protocol: TCP targetPort: 9093 selector: app: prometheus sessionAffinity: None type: NodePortEOF |
通过kubectl apply更新yaml文件
kubectl apply -f prometheus-svc.yaml
#查看service在物理机映射的端口
kubectl get svc -n monitor-sa
显示如下:
1 2 3 | NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager NodePort 10.111.49.65 <none> 9093:31043/TCP 25sprometheus NodePort 10.96.45.93 <none> 9090:30090/TCP 34h |
注意:上面可以看到prometheus的service暴漏的端口是31043,alertmanager的service暴露的端口是30066
访问prometheus的web界面
点击status->targets,可看到如下
点击Alerts,可看到如下
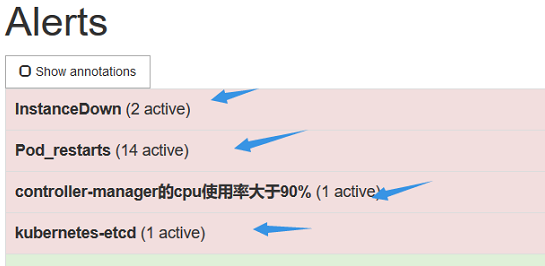
把controller-manager的cpu使用率大于90%展开,可看到如下
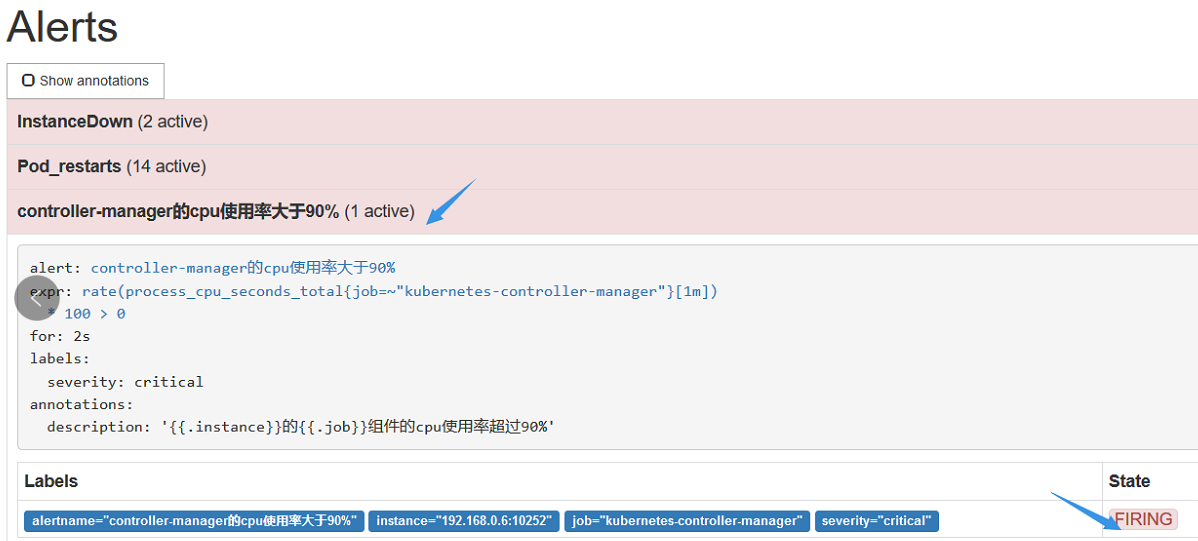
FIRING表示prometheus已经将告警发给alertmanager,在Alertmanager 中可以看到有一个 alert。
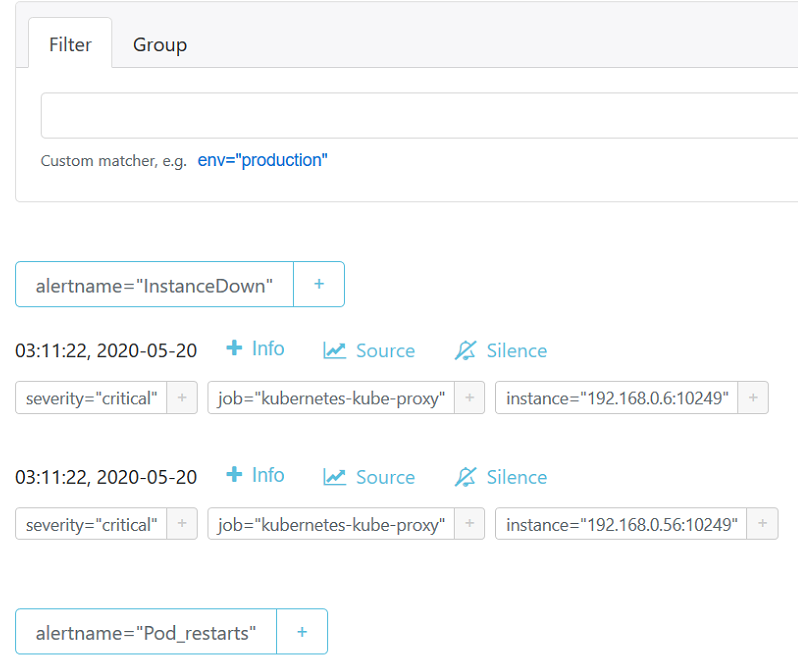
登录到alertmanager web界面
浏览器输入192.168.0.6:30066,显示如下
这样我在我的qq邮箱,1980570647@qq.com就可以收到报警了,如下

配置Alertmanager报警-发送报警到钉钉
打开电脑版钉钉创建机器人
1.创建钉钉机器人
打开电脑版钉钉,创建一个群,创建自定义机器人,按如下步骤创建
https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq
我创建的机器人如下:
群设置-->智能群助手-->添加机器人-->自定义-->添加
机器人名称:kube-event
接收群组:钉钉报警测试
安全设置:
自定义关键词:cluster1
上面配置好之后点击完成即可,这样就会创建一个kube-event的报警机器人,创建机器人成功之后怎么查看webhook,按如下:
点击智能群助手,可以看到刚才创建的kube-event这个机器人,点击kube-event,就会进入到kube-event机器人的设置界面
出现如下内容:
机器人名称:kube-event
接受群组:钉钉报警测试
消息推送:开启
webhook:https://oapi.dingtalk.com/robot/send?access_token=9c03ff1f47b1d15a10d852398cafb84f8e81ceeb1ba557eddd8a79e5a5e5548e
安全设置:
自定义关键词:cluster1
2.安装钉钉的webhook插件,在k8s的master1节点操作
tar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz
prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz压缩包所在的百度网盘地址如下:
链接:https://pan.baidu.com/s/1_HtVZsItq2KsYvOlkIP9DQ 提取码:d59o
cd prometheus-webhook-dingtalk-0.3.0.linux-amd64
启动钉钉报警插件
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="cluster1=https://oapi.dingtalk.com/robot/send?access_token=9c03ff1f47b1d15a10d852398cafb84f8e81ceeb1ba557eddd8a79e5a5e5548e" &
对原来的文件做备份
cp alertmanager-cm.yaml alertmanager-cm.yaml.bak
重新生成一个新的alertmanager-cm.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | cat >alertmanager-cm.yaml <<EOFkind: ConfigMapapiVersion: v1metadata: name: alertmanager namespace: monitor-sadata: alertmanager.yml: |- global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: '15011572657@163.com' smtp_auth_username: '15011572657' smtp_auth_password: 'BDBPRMLNZGKWRFJP' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 10m receiver: cluster1 receivers: - name: cluster1 webhook_configs: - url: 'http://192.168.124.16:8060/dingtalk/cluster1/send' send_resolved: trueEOF |
通过kubectl apply使配置生效
1 2 3 4 5 6 | kubectl delete -f alertmanager-cm.yamlkubectl apply -f alertmanager-cm.yamlkubectl delete -f prometheus-cfg.yamlkubectl apply -f prometheus-cfg.yamlkubectl delete -f prometheus-deploy.yamlkubectl apply -f prometheus-deploy.yaml |
通过上面步骤,就可以实现钉钉报警了
https://www.cnblogs.com/g2thend/articles/11865302.html 学习



