awk 条件判断与正则、12个实用函数
一、awk与条件判断、循环
(一) 条件判断
① if结构
if [ xxx ];then
xxx
fi
格式:
awk 选项 '正则,地址定位{awk语句}' 文件名
{ if(表达式){语句1;语句2;...}}
#$3为uid
awk -F: '{if($3>=500 && $3<=60000) {print $1,$3} }' passwd
awk -F: '{if($3==0) {print $1"是管理员"} }' passwd
root是管理员
awk 'BEGIN{if('$(id -u)'0) {print "admin"} }'
admin
② if...else结构
if [ xxx ];then
xxxxx
else
xxx
fi
格式:
{if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F: '{ if($3>=500 && $3 != 65534) {print $1"是普通用户"} else {print $1,"不是普通用户"}}' passwd
awk 'BEGIN{if( '$(id -u)'>=500 && '$(id -u)' !=65534 ) {print "是普通用户"} else {print "不是普通用户"}}'
③ if...elif...else结构
if [xxxx];then
xxxx
elif [xxx];then
xxx
....
else
...
fi
格式:
{ if(表达式1){语句;语句;...}else if(表达式2){语句;语句;...}else if(表达式3){语句;语句;...}else{语句;语句;...}}
范例:
1、打印用户类型
awk -F: '{ if($3==0) {print $1,":是管理员"} else if($3>=1 && $3<=499 || $3==65534 ) {print $1,":是系统用户"} else {print $1,":是普通用户"}}' /etc/passwd
root :是管理员
sys :是系统用户
zjz :是普通用户
2、打印用户个数
awk -F: '{ if($3==0) {i++} else if($3>=1 && $3<=499 || $3==65534 ) {j++} else {k++}};END{print "管理员个数为:"i "\n系统用户个数为:"j"\n普通用户的个数为:"k }' /etc/passwd
管理员个数为:1
系统用户个数为:27
普通用户的个数为:2
(二)循环语句
① for循环
##打印1~5
for ((i=1;i<=5;i++));do echo $i;done
awk 'BEGIN { for(i=1;i<=5;i++) {print i} }'
打印1~10中的奇数
for ((i=1;i<=10;i+=2));do echo $i;done|awk '{sum+=$0};END{print sum}'
awk 'BEGIN{ for(i=1;i<=10;i+=2) {print i} }'
awk 'BEGIN{ for(i=1;i<=10;i+=2) print i }'
#计算1-5的和
awk 'BEGIN{sum=0;for(i=1;i<=5;i++) sum+=i;print sum}'
awk 'BEGIN{for(i=1;i<=5;i++) (sum+=i);{print sum}}'
awk 'BEGIN{for(i=1;i<=5;i++) (sum+=i);print sum}'
② while循环
打印1-5
# i=1;while (($i<=5));do echo $i;let i++;done
# awk 'BEGIN { i=1;while(i<=5) {print i;i++} }'
打印1~10中的奇数
# awk 'BEGIN{i=1;while(i<=10) {print i;i+=2} }'
计算1-5的和
# awk 'BEGIN{i=1;sum=0;while(i<=5) {sum+=i;i++}; print sum }'
# awk 'BEGIN {i=1;while(i<=5) {(sum+=i) i++};print sum }'
③ 嵌套循环
嵌套循环:
#!/bin/bash
for ((y=1;y<=5;y++))
do
for ((x=1;x<=$y;x++))
do
echo -n $x
done
echo
done
awk 'BEGIN{ for(y=1;y<=5;y++) {for(x=1;x<=y;x++) {printf x} ;print } }'
awk 'BEGIN { for(y=1;y<=5;y++) { for(x=1;x<=y;x++) {printf x};print} }'
1
12
123
1234
12345
awk 'BEGIN{ y=1;while(y<=5) { for(x=1;x<=y;x++) {printf x};y++;print}}'
1
12
123
1234
12345
打印乘法口诀表shell的几种写法:
#!/bin/bash
for i in $(seq 9)
do
for j in $(seq $i)
do
echo -n "$j*$i=$[$i * $j] "
done
echo
done
seq 9 | sed 'H;g' | awk -v RS='' '{for (i=1;i<=NF;i++)printf("%dx%d=%d%s",i,NR,i*NR,i==NR?"\n":"\t")}'
awk 'BEGIN{for(y=1;y<=9;y++) { for(x=1;x<=y;x++) printf x"*"y"="x*y"\t";print} }'
awk 'BEGIN{i=1;while(i<=9){for(j=1;j<=i;j++) {printf j"*"i"="j*i"\t"};print;i++ }}'
awk 'BEGIN{for(i=1;i<=9;i++){j=1;while(j<=i) {printf j"*"i"="i*j"\t";j++};print}}'
###不够人性化
awk '{for(i=1;i<=9;i++){for(j=1;j<=i;j++){printf "%d*%d=%d ",j,i,j*i}printf "\n"}}'
循环的控制:
break 条件满足的时候中断循环
continue 条件满足的时候跳过循环
awk 'BEGIN{for(i=1;i<=5;i++) {if(i==3) break;print i} }'
1
2
awk 'BEGIN{for(i=1;i<=5;i++){if(i==3) continue;print i}}'
1
2
4
5
二、awk与算数运算
+ - * / %(模) ^(幂2^3)
可以在模式中执行计算,awk都将按浮点数方式执行算术运算
awk 'BEGIN{print 1+1}'
awk 'BEGIN{print 1**1}'
awk 'BEGIN{print 2**3}'
awk 'BEGIN{print 2/3}'
示例:
awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd
zjz 1000
zjz1 1001
awk -F: '{if($NF=="/bin/bash")print $1}' /etc/passwd
root
zjz
zjz1
awk -F: '{if($3>=1000){print "Common user:%s\n",$1}else {print "root or Sysuser:%s\n",$1}}' /etc/passwd
root or Sysuser:%s
sshd
root or Sysuser:%s
apache
Common user:%s
zjz
Common user:%s
zjz1
df -hT |awk -F% '/^\/dev\/sda1/{print $1}'|awk '$NF>=10{print $1,$6}'
/dev/sda1 13
awk 'BEGIN{test=20;if(test>90){print "very good"}else if (test>60){print "good"}else {print "no pass"} }'
no pass
打印行前或者行后,NR:行号,$NF:最后一列。(大于>、小于<、等于==)
$ cat zjz.txt | awk '{if(NR>6) print $NF}'
init.sh
django.log.2020-11-09.gz
backend.py
cassandra-env.sh
将当前目录下大于 10K 的文件转移到 /tmp 目录,再按照文件大小顺序,从大到小输出文件名。
#!/bin/bash
# 目标目录
DIRPATH='/tmp'
# 查看目录
FILEPATH='.'
find "$FILEPATH" -size +10k -type f | xargs -i mv {} "$DIRPATH"
ls -lS "$DIRPATH" | awk '{if(NR>1) print $NF}'
打印访问次数大于21的ip
cat access1.log |cut -d ' ' -f 1 | sort -nr |uniq -c | sort -nr | head -n 20 | awk -F" " '{if ($1 >= 21) print $0}'
896 60.21.253.82
75 216.83.59.82
21 61.241.50.63
21 211.95.50.7
三、awk流程控制
break、continue、next、nextfile、exit
1、break和continue
break:可退出for、while、do…while、switch语句。
continue:可让for、while、do…while进入下一轮循环。
awk '
BEGIN{
for(i=0;i<10;i++){
if(i==5){
break
}
print(i)
}
# continue
for(i=0;i<10;i++){
if(i==5)continue
print(i)
}
}'
2、next和nextfile
next:会在当前语句处立即停止后续操作,并读取下一行,进入循环顶部。
例如,输出除第3行外的所有行。
awk 'NR==3{next}{print}' a.txt
awk 'NR==3{getline}{print}' a.txt
nextfile:会在当前语句处立即停止后续操作,并直接读取下一个文件,并进入循环顶部。
例如,每个文件只输出前2行:
awk 'FNR==3{nextfile}{print}' a.txt a.txt
3、exit
直接退出awk程序。
注意,END语句块也是exit操作的一部分,所以在BEGIN或main段中执行exit操作,也会执行END语句块。
如果exit在END语句块中执行,则立即退出。
所以,如果真的想直接退出整个awk,则可以先设置一个flag变量,然后在END语句块的开头检查这个变量再exit。
BEGIN{
...code...
if(cond){
flag=1
exit
}
}
{}
END{
if(flag){
exit
}
...code...
}
awk '
BEGIN{print "begin";flag=1;exit}
{}
END{if(flag){exit};print "end2"}
'
exit可以指定退出状态码,如果触发了两次exit操作,即BEGIN或main中的exit触发了END中的exit,且END中的exit没有指定退出状态码时,则采取前一个退出状态码。
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit 1}}'
$ echo $?
1
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit}}'
$ echo $?
2
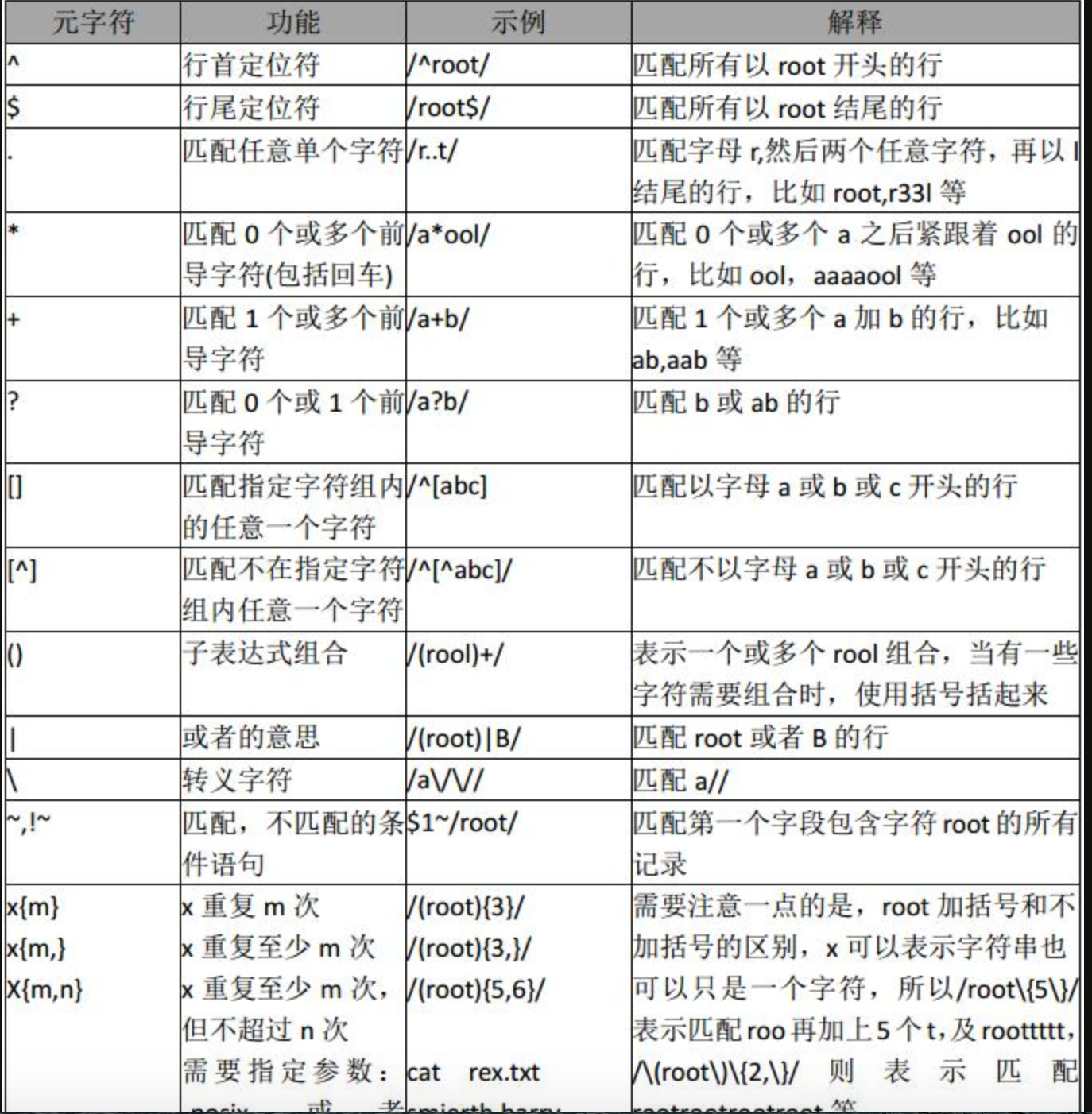
四、awk与正则
https://www.cnblogs.com/ginvip/p/6352157.html
五、12个实用函数
1、length()
返回字符串或字段的长度。
echo "hello world" | awk '{print length($0)}' # 输出:11
2、substr(s, start, [length])
返回字符串 s 中从位置 start 开始、长度为 length 的子串。如果未指定 length,则返回从 start 到字符串结尾的子串
echo "abcdef" | awk '{print substr($0, 2, 3)}' # 输出:bcd
3、index(s, t)
返回字符串 t 在字符串 s 中首次出现的位置。如果未找到,则返回 0
echo "hello world" | awk '{print index($0, "world")}' # 输出:7
4、match(s, regex)
测试字符串 s 是否与正则表达式 regex 匹配,如果匹配成功,RSTART 变量设置为匹配的起始位置,RLENGTH 为匹配的长度
echo "abcdef" | awk '{if (match($0, /c.*f/)) print RSTART, RLENGTH}' # 输出:3 4
5、split(s, a, [regex])
将字符串 s 通过 regex 分割成数组 a。如果未提供 regex,则使用默认字段分隔符。
echo "apple,banana,orange" | awk '{n=split($0, a, ","); for (i=1; i<=n; i++) print a[i]}'
# 输出:apple
# banana
# orange
6、sprintf(fmt, expr, ...)
返回格式化字符串,类似 printf。
echo "10" | awk '{print sprintf("%.2f", $1)}' # 输出:10.00
7、tolower(str)
将字符串 str 中的所有字符转换为小写。
echo "HELLO" | awk '{print tolower($0)}' # 输出:hello
8、toupper(str)
将字符串 str 中的所有字符转换为大写。
echo "hello" | awk '{print toupper($0)}' # 输出:HELLO
9、gsub(regex, replacement, [target])
在 target 中用 replacement 替换所有匹配 regex 的部分。如果未提供 target,则应用于当前行。
echo "foo bar baz" | awk '{gsub(/bar/, "baz", $0); print}' # 输出:foo baz baz
grep -nr image: ./*.yml | awk '{ gsub(/"/, ""); print $3 }'
172.30.247.81:5000/app-router:v3.1.4-20241211
172.30.247.81:5000/common-util:1-20180408
# 替换前
"172.30.247.81:5000/app-router:v3.1.4-20241211"
"172.30.247.81:5000/common-util:1-20180408"
10、sub(regex, replacement, [target])
在 target 中用 replacement 替换第一个匹配 regex 的部分。
echo "foo bar baz" | awk '{sub(/bar/, "baz", $0); print}' # 输出:foo baz baz
11、strftime([format [, timestamp]])
返回格式化的时间字符串,timestamp 为时间戳。如果未指定,则使用当前时间。
awk 'BEGIN {print strftime("%Y-%m-%d %H:%M:%S")}' # 输出当前时间,格式为:YYYY-MM-DD HH:MM:SS
12、srand([seed])
用于初始化随机数生成器的种子,如果未提供 seed,则使用当前时间。
srand([seed]) 用于初始化随机数生成器的种子,如果未提供 seed,则使用当前时间。
https://www.junmajinlong.com/shell/awk/awk_process_control_statement2/ 精通awk系列
