awk数组、tr、计数
1、统计用户登录类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #!/bin/bashdeclare -A shells (定义关联数组shells)while read ll (读取/etc/passwd,ll为变量)dotype=`echo $ll | awk -F: '{print $7}'` (type为变量,切割ll后的变量)let shells[$type]++done < /etc/passwdfor i in ${!shells[@]}do echo "$i ::::: ${shells[$i]}" done~ [root@localhost ~]# bash tj2.sh/sbin/nologin ::::: 17/bin/sync ::::: 1/bin/bash ::::: 3/sbin/shutdown ::::: 1/sbin/halt ::::: 1 |
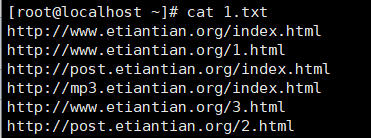
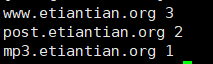
2、将域名取出并根据域名进行计数排序处理(常用)
1 | cat 1.txt | awk -F "/+" '{ip[$2]++}END{for(i in ip) print i,ip[i]}' | sort -rnk2 |
3、替换硬件地址小写为大写,去掉:
1 | # ip a | grep "link/ether" | awk -F" " '{print $2}' | tr '[a-z]' '[A-Z]'|sed 's/://g' |
4、打印某行某列
1 2 3 4 5 6 7 | # cat /etc/passwd | column -s : -t | awk 'NR==2 {print $3}' #NR表示行,$跟列($0特殊,表示本行)# cat /etc/passwd | column -s : -t | awk 'NR==2,NR==4 {print $3}' #行的范围# cat /etc/passwd | column -s : -t | awk 'NR==1' #只要某行时,不需要跟print就能出来root x 0 0 root /root /bin/bash注意:column -t 表示把输出以表格显示,-s参数是指定输出中已经存在的字符变为空格符。 |
5、sed和cut
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # sed -n 1,5p file1 | cut -d : -f1-6 (1,5p打印范围,-d 指定分隔符,-f字符串)root:x:0:0:root:/rootbin:x:1:1:bin:/bindaemon:x:2:2:daemon:/sbinadm:x:3:4:adm:/var/admlp:x:4:7:lp:/var/spool/lpd<br># sed -n 1,5p file1 | cut -c1-6(-c从左往右一个单字符就算一个整体)root:xbin:x:daemonadm:x:lp:x:4打印1行5列# sed -n 4p file1 |cut -c 5 (文本里是连续纯字符,-d 和 -f 组合就不适用了)5 |
6、awk拼接打印
1 2 3 | # docker images | grep 192 | awk 'BEGIN{OFS=":"}''{print $1,$2}' > 1.txt# cat images.txt | awk '{print $1 ":" $2}' |
OFS=":"表示以:为拼接符号
或者awk '{print $x".xxx"}',xxx为任意想要添加的变量
1 2 3 4 5 | cat output.txt | awk '{print $4".bmp"}' > barcat barRBA32010419vbjk101638.bmpRBA320104197904101611.bmp |
或者
1 2 3 4 5 | docker images | grep harbor | awk '{print "docker tag" " " $3 " " $1":"$2}'docker tag 18036ee471bc harbor.cetccloud.com/amd64/redis-photon:v1.8.2docker tag ad798fd6e618 harbor.cetccloud.com/amd64/harbor-registryctl:v1.8.2docker tag 081bfb3dc181 harbor.cetccloud.com/amd64/registry-photon:v2.7.1-patch-2819-v1.8.2 |
paste拼接命令方式
1 | paste -d -s -file1 file2 |
选项的含义如下:
-d 指定不同于空格分隔符,如果不指定,默认用空格分割
-s 将每个文件合并成行而不是按行粘贴。
- 使用标准输入。例如ls -l | paste ,意即只在一列上显示输出
-s用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # cat per1ID897ID666ID982# cat per2P.JonesS.RoundL.Clip# paste per1 per2ID897 P.JonesID666 S.RoundID982 L.Clip # paste -s per1 per2ID897 ID666 ID982P.Jones S.Round L.Clip |
-d案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | paste file1.txt file2.txt 12345 6789paste -d "+" file1.txt file2.txt 12345+6789paste -d "" file1.txt file2.txt 123456789交叉合并$ cat 123.txt aabbccdd$ cat 456.txt 112233$ paste 123.txt 456.txt |tr "\t" "\n"aa11bb22cc33dd |
7、awk -F分隔符 'BEGIN { 初始化 } { 循环执行部分 } END { 结束处理 }' file1 file2
1 2 3 4 5 6 7 8 9 10 11 12 | NR放在循环执行部分# awk '{print NR,$0}' aa.txt,表示行数,显示行号。1 aadak2 ksdlb3 d;smlb4 fl; b放在 END { 结束处理 }',表示最后一行。# awk 'END{print NR,$0}' aa.txt 4 fl; b |
8、求和(docker images镜像的大小)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # cat 1.sh |grep MB | awk '{sum+=$7}END{print sum}'7256# cat 1.sh |grep MB| awk '{print sum+=$7}END{print sum}'69711051513192623592773369341184543503056236465684872567256 |
9、tr常用操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr '\n' '+') 0 ]45 注:$[]表示计算,0表示末尾要加的数,因为会9后面的回车符会换成+号。xargs -n1 :表示每次只传递一个参数echo 1 2 3 4 | xargs -n1 1 2 3 4 echo 1 2 3 4 | xargs -n2 1 2 3 4 批量解压*.tar.gz文件。ls *.tar.gz | xargs -n1 tar -zxvfecho 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr '\n' '+') 1 ]46echo 1 2 3 4 5 6 7 8 9 | xargs -n1 | echo $[ $(tr '\n' '+') 2 ]47echo 1 2 3 4 5 6 7 8 9 |tr ' ' '+'1+2+3+4+5+6+7+8+9echo 1 2 3 4 5 6 7 8 9 |tr ' ' '+'|bc45 |
-s 压缩重复的部分或者是把多个字符当做一个整体
1 2 3 4 5 | cat 1.sh |grep MB| awk '{print $7}'| tr "MB\n" '+'697+++408+++408+++413+++433+++414+++920+++425+++425+++487+++593+++842+++383+++408+++cat 1.sh |grep MB| awk '{print $7}'| tr -s "MB\n" '+'697+408+408+413+433+414+920+425+425+487+593+842+383+408+ |
-d 删除
1 2 3 4 5 6 7 8 | # cat 1.sh |grep MB| awk '{print $7}'697MB408MB408MB# cat 1.sh |grep MB| awk '{print $7}'|tr -d MB697408408 |
10、生成任意长度的字符串
1 2 | # head /dev/urandom | tr -dc A-Za-z0-9 | head -c 12FZmEl60TxdvX |
11、打印所有的进程、slab分别占用内存总量(linux系统内存消耗主要有三个地方:进程、slab、pagecacge)
1 2 3 4 5 | # echo `ps aux |awk '{mem += $6} END {print mem/1024/1024}'` GB0.494217 GB# echo `cat /proc/meminfo|grep Slab|awk '{mem += $2} END {print mem/1024/1024}'` GB0.111328 GB |
12、取出本机ip
1 2 3 4 5 6 7 8 | #hostname -i |awk -F" " '{print $2}' #注意,{}外面的单引号192.168.40.132#hostname -ife80::20c:29ff:fece:16d0%ens33 192.168.40.132 172.17.0.1#hostname -I192.168.40.132 172.17.0.1 |
13、数组结合for循环
1 2 3 4 5 6 7 8 9 10 11 | # cat clean-rook-dir.shhosts=( ke-dev1-master3 ke-dev1-worker1 ke-dev1-worker3 ke-dev1-worker4)for host in ${hosts[@]} ; do ssh $host "rm -rf /var/lib/rook/*"done |
14、查看Apache的并发请求数及其TCP连接状态
1 | netstat -n | awk ‘/^tcp/ { S[$NF]} END {for(a in S) print a, S[a]}’ |
结果解读
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | LAST_ACK 5SYN_RECV 30ESTABLISHED 1597FIN_WAIT1 51FIN_WAIT2 504TIME_WAIT 1057其中的SYN_RECV表示正在等待处理的请求数;<br>ESTABLISHED表示正常数据传输状态;<br>TIME_WAIT表示处理完毕,等待超时结束的请求数。关于TCP状态的变迁,可以从下图形象地看出:状态:描述CLOSED:无连接是活动的或正在进行LISTEN:服务器在等待进入呼叫SYN_RECV:一个连接请求已经到达,等待确认SYN_SENT:应用已经开始,打开一个连接ESTABLISHED:正常数据传输状态FIN_WAIT1:应用说它已经完成FIN_WAIT2:另一边已同意释放ITMED_WAIT:等待所有分组死掉CLOSING:两边同时尝试关闭TIME_WAIT:另一边已初始化一个释放LAST_ACK:等待所有分组死掉 |
15、多个分隔符提取多个字段
log.txt的内容格式大概如下:
1 2 | 30000|ddddd|/jjjjj/22/nn|200003|mmm|/ffffff/222222/mmmmmm|111111 |
每行的第一个数据和第三个数据和第五个数据截出来,用“,”隔开,写法如下
1 | awk -F'[|/]' '{OFS=","}{print $1,$4,$6}' log.txt |
16、统计当前目录中以.html结尾的文件总大
1 | find . -name "*.html" -exec du -k {} \; |awk '{sum+=$1}END{print sum}' |
或者
1 2 3 4 | for size in $(ls -l *.html |awk '{print $5}'); do sum=$(($sum+$size))doneecho $sum |
for 和数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #!/bin/basha="file1file2file3file4file5file6file7file8"for i in ${a[*]}domkdir $idoneecho "输出数组的所有元素: ${a[*]}" |
关于shell中数组array的补充
1、定义
数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小(与 PHP 类似)。
与大部分编程语言类似,数组元素的下标由 0 开始。
Shell 数组用括号来表示,元素用"空格"符号分割开,语法格式如下:
1 | array_name=(value1 value2 ... valuen) |
2、创建与查看
1 2 3 4 5 6 7 8 9 10 | ##方式1my_array=(A B "C" D)##方式2array_name[0]=value0array_name[1]=value1array_name[2]=value2##查看数组元素echo ${array_name[index]} |
获取数组中的所有元素
使用 @ 或 * 可以获取数组中的所有元素
在数组前加一个感叹号 ! 可以获取数组的所有键,例如:
1 2 3 4 5 6 7 | declare -A sitesite["google"]="www.google.com"site["runoob"]="www.runoob.com"site["taobao"]="www.taobao.com"echo "数组的键为: ${!site[*]}"echo "数组的键为: ${!site[@]}" |
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
1 2 3 4 5 6 7 | my_array[0]=Amy_array[1]=Bmy_array[2]=Cmy_array[3]=Decho "数组元素个数为: ${#my_array[*]}"echo "数组元素个数为: ${#my_array[@]}" |
3、关联数组
Bash 支持关联数组,可以使用任意的字符串、或者整数作为下标来访问数组元素。
类似于py的字典,用-A指定
关联数组使用 declare 命令来声明,语法格式如下:
1 | declare -A array_name |
-A 选项就是用于声明一个关联数组。
关联数组的键是唯一的。
以下实例我们创建一个关联数组 site,并创建不同的键值:
1 2 3 4 5 6 7 | declare -A site=(["google"]="www.google.com" ["runoob"]="www.runoob.com" ["taobao"]="www.taobao.com")##也可以先声明一个关联数组,然后再设置键和值declare -A sitesite["google"]="www.google.com"site["runoob"]="www.runoob.com"site["taobao"]="www.taobao.com" |
4、数组操作案例
场景:ansible hosts文件中定义了一组标签,想要取出swarm-03的标签,将标签添加到新的swarm-02节点
1 2 3 | [docker_swarm_worker]swarm-02 swarm_labels='["secondary-manager", "opt", "es1", "mysqls", "common"]'swarm-03 swarm_labels='["dp", "kafka", "logstash", "es3", "dataflow_task", "systools", "common", "nacos"]' |
shell部分代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | function add_tag() { # 从文本中解析出的标签字符串 label_string=$(cat /etc/ansible/hosts | grep docker_swarm_worker -A 4 | grep $1 | grep -oP 'swarm_labels=\K.*') # 使用 sed 删除反斜杠,方括号,双引号,'和\ # cut -c 2- 表示从第二个字符到末尾结束做保留,rev反转 label_list=$(echo $label_string | tr -d '["]' | cut -c 2- | rev | cut -c 2- | rev) # 使用逗号将标签字符串分割为数组 IFS=',' read -ra labels <<< "$label_list" # 循环标签数组,每个标签都使用docker node update --label-add方式添加到swarm-02上 for label in "${labels[@]}"; do ssh ${new_master_ip} "docker node update --label-add $label=true $2" done}if [ ${node_num} -eq 2 ]; then add_tag swarm-03 ${curr_node_name}elif [ ${node_num} -eq 4 ];then add_tag swarm-05 ${curr_node_name}else exit 1fi |
注释:
1、在grep命令中,-o选项表示仅把匹配的部分打印出来,-P选项表示使用Perl的正则表达式。
\K是一个在Perl正则表达式中的特殊序列,表示"忽略前面已经匹配的内容"。'swarm_labels=\K.*'表示匹配'swarm_labels='和其后面的任何内容,但是只获取和返回=号之后的内容。所以,如果你有一行内容如下:
1 | swarm-05 swarm_labels='["dp", "kafka", "logstash", "dataflow_task", "systools", "common", "nacos"]' |
grep -oP 'swarm_labels=\K.*'会返回:
1 | '["dp", "kafka", "logstash", "dataflow_task", "systools", "common", "nacos"]' |
2、tr -d '["]' 表示删除所有的 ' (单引号)," (双引号) 和 [,] 这些字符。
1 | dp, kafka, logstash, dataflow_task, systools, common, nacos |
3、IFS=',' read -ra labels <<< "$label_list"
作用是将变量$label_list的内容按分隔符,解析,并分割为一个数组labels。
-
IFS=',': 这是bashshell中的特殊变量,全名是Internal Field Separator(内部字段分隔符),用来定义分词时的分割字符。在这里,我们设置IFS=',',意味着接下来的读取操作将使用,作为分割符。 -
read -ra labels:read命令用于读取一行输入。-a选项的作用是将读取到的数据分割成数组。-r选项的作用是使得read命令不会把反斜杠字符解释为转义字符。在这个命令中,我们使用read -ra labels读取分割后的数据到数组labels中。 -
<<< "$label_list":<<<是shell的一种输入重定向操作,它将$label_list的值作为输入传递给前面的read命令。 -
执行完这个命令后,
$labels变成了一个数组,其中存储了以,分割的每一个子项。例如,如果$label_list为dp, kafka, logstash, dataflow_task, systools, common, nacos,那么$labels将会是一个包含了各个项dpkafkalogstashdataflow_tasksystoolscommonnacos的数组。
https://www.runoob.com/linux/linux-shell-array.html 数组



